Ryzen 6000 und Co: Neue Details zum 3D V-Cache - zündet AMD den Stapel-Turbo?
Im Rahmen der Hot Chips 33 hat AMD weitere Details zum 3D V-Cache verraten, der auf bestehende Zen-3-Prozessoren aufmontiert werden soll. Auch andere Stapelvorhaben wurden angedeutet. So will man künftig auch CPU-Kerne übereinanderlegen.
AMD hatte den gemeinsam mit TSMC entwickelten 3D V-Cache bereits im Juni präsentiert, ergänzende Details zum 3D-Stacking-Verfahren enthüllte man in den folgenden Monaten häppchenweise. Nun hat AMD die Hot Chips 33 genutzt, um weitere Einzelheiten zum 3D V-Cache zu enthüllen. Es ging dabei unter anderem um die Abstände der Through-Silicon-Vias, kurz TSVs. Laut AMD beträgt der Abstand zwischen den TSVs im Falle des 3D V-Cache gerade einmal 9 µm.
Auf dem Papier kann Intel, die bei Lakefield bereits auf 3D-Stacking setzen, nur mit Zukunftstechnologie mithalten. Erst Foveros Direct soll Abstände von "<10 µm" aufweisen, doch geplant ist das Verfahren erst für 2023. AMD hingegen soll erste Produkte mit 3D V-Cache noch dieses Jahr ankündigen. Einen 12- und 16-Kerner hatte man auch schon angedeutet. Prinzipiell seien aber alle Ryzen-5000-Prozessoren auf das "aufmontieren" des 3D V-Cache vorbereitet. Er soll, wie berichtet, den L3-Cache effektiv um den Faktor 3 vergrößern. Im Raum steht eine 15-prozentige Leistungssteigerung.
Bildergalerie
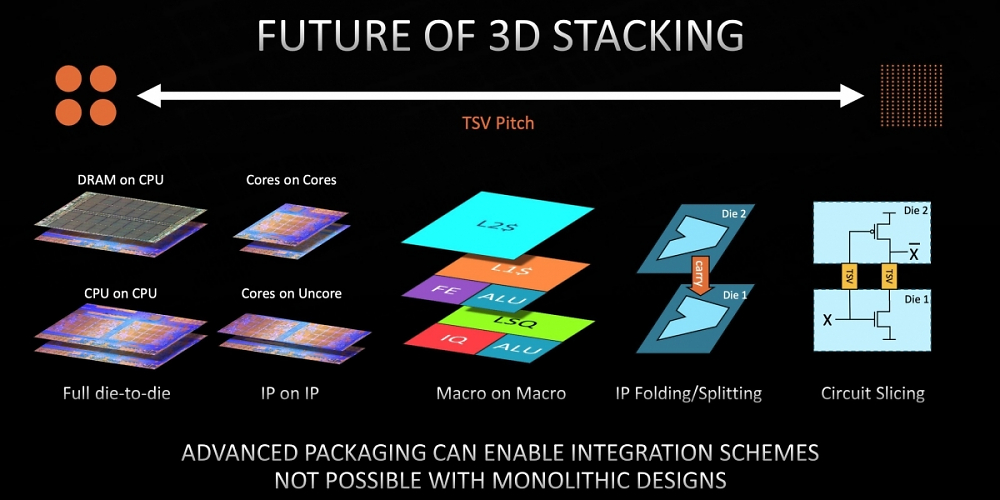
3D V-Cache nur der erste Schritt von vielen
AMD betonte während der Hot Chips 33, dass jede Lösung ihren Markt hat und nicht gleich produktübergreifend zum Einsatz kommen soll. Hochpreisige Produkte werden also eher als das Einsteiger- und Mittelklasseportfolio bedacht. Langfristig gehört den Stapeltechnologien aber offenbar die Zukunft.
Mehr zum Thema: X570S-Mainboards: MSI mit neuen Modellen - Hinweis auf AMDs Zen 3+?
So deutet AMD in Folien an, dass man künftig auch Kern auf Kern übereinanderzustapeln gedenkt. Selbst eine Die-auf-Die-Lösung findet sich in den Folien. Ähnlich wie bei Intels Lakefield sollen letztlich auch Core- und Uncore-Bereiche eines Prozessors gestapelt werden können. Wann bei AMD derartige Verfahren Einzug halten, wird abzuwarten sein. Als Herausforderung dürfte sich bei entsprechenden Chips insbesondere auch die Kühlung erweisen.
Quelle: Ian Cutress (AnandTech), Andreas Schilling (Hardwareluxx), Computerbase










Wie viel ist ein 11900K oder 5950X rein auf die IPC gesehen nochmal schneller als ein Skylake von 2015? 30% oder sowas?
Wenn du stapelst kannst du beispielsweise nur 1/4 so große Einzelchips herstellen und 4 davon stapeln.
Das klingt gleich, letzteres ist aber weit weniger Yieldrateanfällig - denn wenn du einen Siliziumfehler im großen Chip hast ist der CHip für die Tonne, im zweiten Beispiel wäre einer für die Tonne und die anderen drei brauchbar. Wenn das Stacking massenware ist und nicht für sich gesehen einen großen Kostenfaktor ausmacht dann wird ein 4x8 gestackter 32-Kerner schlicht billiger als ein 32-Kern-Monoolithischer Die.
[Ins Forum, um diesen Inhalt zu sehen]
Intel hat schon vor 1,5 Jahrzehnten Demo-Prozessoren mit Cache-on-Top vorgeführt, das ist erstmal der naheliegende Schritt. Gestapelte Logik werden wir erst sehen, wenn die Kommunikation zwischen Kernen über die schmalen Kanten nicht mehr schnell genug erfolgen kann und man stattdessen den flächigen Kontakt eines Stack sucht. Aufgrund der riesigen Probleme mit Kühlung und Stromversorgung könnte dieser Punkt aber nie erreicht werden; Intel strebt ja mit PowerVia sogar in die Gegenrichtung und will weniger Krempel auf die Kerne packen, damit das Routing beherrschbar bleibt. Ggf. wird stacking für CPUs mit der Technik sogar ganz obsolet, denn der Schritt von Nano-PowerTSVs zu Nano-DataTSVs, mit denen Cache oder ander Strukturen auf die Rückseite des gleichen Wafers belichtet werden können, erscheint mir ein kleiner zu sein.
Für Consumer sehe ich da keinen wirklichen Bedarf.
Verwendet Zen 4 auch schon Core Stacking?
Mutmaßung: Latenzen werden durch stacking eher schlechter als besser, AMD hat aber zumindest behauptet dass sie es geschafft haben dass es NICHT schlechter wird, zumindest bezogen auf den gestackten 3D-Cache.
ZEN4 wird mit großer Wahrscheinlichkeit noch keine Kerne stacken da das einfach noch nicht notwendig ist in dem Bereich vor allem wenn man Chiplets nutzt. Wenn man Richtung 3nm geht werden die Dies wieder so klein, dass man auch 12 oder 16 statt 8 Kerne in ein Chiplet packen könnte ohne dass es unwirtschaftlich würde. Man muss für normale Packages sogar schauen dass man eine Mindestgröße des Dies erreicht da dieser sonst erstens sauschlecht verlötbar wird und zweitens extreme Hotspots erzeugt... AMD kann kaum Interesse daran haben, ein 8-Kern Chiplet in 3nm zu produzieren das dann nur noch keine Ahnung 6x6 mm groß ist und nicht mehr am IHS hält. Sowas kannste im Smartphone machen wenn der Chip 5W verbraucht aber nicht im 100+W-TDP-Desktop^^
Cache stacken sehe ich durchaus in naher Zukunft, Kerne stacken im Endkundenbereich noch lange nicht.