Prozessor-Revolution? ACE bringt KI-Matrix in x86-CPUs

Mit ACE bringen Intel und AMD eine x86-Erweiterung für KI-Matrixrberechnungen auf den Weg, die lokale Inferenz im Prozessorkern beschleunigen soll. Aktuelle Gaming-PCs sind nicht betroffen: Erste CPUs mit ACE kommen frühestens 2028.
Intel und AMD haben jetzt über die x86 Ecosystem Advisory Group ("EAG"), eine strategische Allianz der beiden CPU-Schwergewichte, die vollständige Spezifikation der ACE-Erweiterungen veröffentlicht. ACE steht dabei für AI Compute Extensions und beschreibt einen Befehlssatz, welcher die Matrixmultiplikation für KI-Workloads direkt im Prozessorkern beschleunigt, statt sie an die GPU oder NPU auszulagern.
Die Erweiterung ist der vierte gemeinsame Baustein der im Jahre 2024 gegründeten Allianz der beiden US-Unternehmen aus dem kalifornischen Santa Clara, nach dem Interrupt-Modell FRED, dem Vektorbefehlssatz AVX10 und der Speichersicherung ChkTag. Wer den Bezug zur Praxis sucht: AMD hat seine Matrix-Engine bereits angekündigt, die mit Zen 7 debütiert, während Intel mit den Nova Lake-S die notwendigen Grundlagen durch deren AVX10.2-Erweiterung bereitstellt.
ACE holt die KI-Matrix in den x86-Prozessorkern
Der Hintergrund ist ein Engpass, den derzeit jeder Hardware-Hersteller kennt: Das Rechenherz fast jedes KI-Modells ist die Matrixmultiplikation, und die klassischen CPU-Vektoreinheiten erledigen diese Aufgabe nur mit angezogener Handbremse.
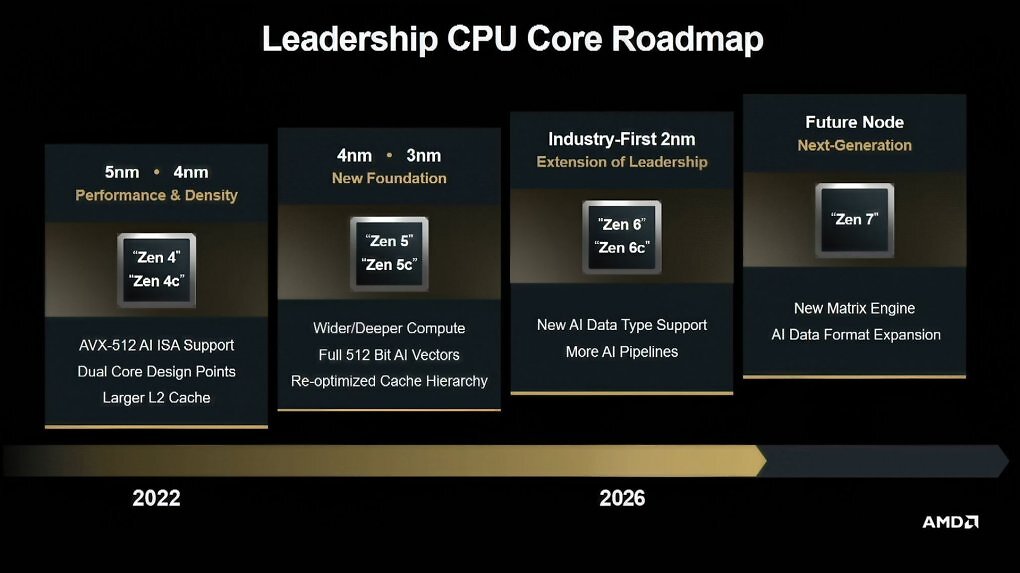 Quelle: AMD
AMD wird seine CPUs auf Basis von Zen 7 mit einer Matrix Engine ausrüsten.
AVX10 kann Matrizen zwar berechnen, doch der Befehlssatz war nie für solche zweidimensionale Operationen gedacht. ACE setzt genau hier an und ergänzt die vorhandenen Vektorregister um eine eigene Logik für Matrixrechnung.
Quelle: AMD
AMD wird seine CPUs auf Basis von Zen 7 mit einer Matrix Engine ausrüsten.
AVX10 kann Matrizen zwar berechnen, doch der Befehlssatz war nie für solche zweidimensionale Operationen gedacht. ACE setzt genau hier an und ergänzt die vorhandenen Vektorregister um eine eigene Logik für Matrixrechnung.
Wie ACE die Matrixmultiplikation beschleunigt
ACE erreicht laut der Spezifikation die 16-fache Rechendichte einer vergleichbaren AVX10-Operation, weil eine einzelne Anweisung "deutlich mehr Multiplikationen" mit jedem Takt erledigt. Technisch führt ACE acht neue Tile-Register ein, die Matrizen im Format 16 × 16 aufnehmen und nach dem Prinzip des äußeren Produkts verarbeiten.
Als Eingang dienen die bekannten 512 Bit breiten ZMM-Register aus AVX10, weshalb sich die Einheit ohne separate Datenpfade in bestehende Designs einfügen lässt. Eine ACE-Operation kombiniert dabei zwei 8-Bit-Matrizen zu 1.024 Multiplikationen pro Takt, wo klassisches AVX hingegen nur 64 Multiplikatoren schafft.
Aus dieser Lücke speist sich der Faktor 16. Die Website Tom's Hardware verweist allerdings darauf, dass diese Zahl die Rechendichte beschreibt und nicht zwingend die reale Leistung. Bei den Datenformaten deckt ACE die für Inferenz üblichen Typen ab, darunter INT8, BF16 sowie die FP8- und MX-Formate des Open Compute Project, welche AVX10 nativ nicht beherrscht.
Wo ACE im KI-Stack einsortiert ist
ACE ordnet sich zwischen dem Vektorbefehlssatz AVX10 und den dedizierten KI-Beschleunigern ein und gilt als Client-Nachfolger der bislang exklusiv den Xeon-CPUs vorbehaltenen AMX-Technologie. Anders als AMX, das Intel nur seinen Server-CPUs spendierte, soll ACE vom Notebook bis ins KI-Rechenzentrum nutzbar sein.
Warum die CPU die GPU nicht ersetzt
Die CPU rechnet auch mit ACE nicht effizienter als eine Grafikkarte oder ein dedizierter Beschleuniger, darauf weist Branchenanalyst Jim McGregor von Tirias Research hin. Der Nutzen liegt woanders: ACE erlaubt es, kleinere Modelle und latenzkritische Anfragen lokal zu erledigen, ohne Daten zur GPU und zurück zu schaufeln.
In Systemen ohne nennenswerte Grafikeinheit, etwa schlanken Notebooks mit integrierter Grafikeinheit ("IGP") oder Embedded-Geräten, ist die CPU ohnehin oftmals die einzige verfügbare Recheneinheit für solche Aufgaben. Hier bringt eine eigene Matrix-Engine innerhalb des Prozessors besonders große Vorteile.
Was das für NPUs bedeutet
Für die Neuralprozessoren, sogenannte NPUs ("Neural Processing Units"), die seit 2023 in fast jedem neuen Mobilprozessor stecken, entsteht damit eine mächtige hausinterne Konkurrenz. Microsoft hatte sein Copilot+-Label an eine NPU mit mindestens 40 TOPS geknüpft, doch ACE erlaubt den Entwicklern, einzelne Aufgabenbereiche bei Bedarf zurück auf die CPU zu holen.
Der Vorteil ist Einheitlichkeit: Wo jede NPU anders anzusprechen ist, bietet ACE über alle x86-CPUs hinweg dasselbe Ziel. Ob die NPUs deshalb mittelfristig verschwinden, ist offen und hängt von der Frage ab, ob ein leicht vergrößerter CPU-Kern effizienter arbeitet als ein eigener Block.
Was ACE für Gaming-CPUs und Spiele bedeutet
Für Spiele bleibt ACE vorerst ein Versprechen, denn neue Befehlssätze brauchen auf dem Spielemarkt traditionell Jahre, bis Engines sie voraussetzen. Konkret denkbar sind drei Felder:
- Erstens lokale Sprachmodelle für Spielfiguren, die Dialoge ohne Cloud-Anbindung erzeugen und dabei latenzkritisch sind, also vom kurzen Weg im CPU-Kern profitieren.
- Zweitens KI-gestützte Werkzeuge rund um Spiele, von Modding-Suiten bis zur Asset-Erzeugung, die auch auf Rechnern ohne potente Grafikkarte laufen müssen.
- Drittens Upscaling-Verfahren, die einen Teil ihrer Berechnung auf die CPU verlagern, wenn die Grafikkarte ausgelastet ist. Der Haken ist derselbe wie bei jeder Befehlssatzerweiterung:
Solange die Masse der verkauften Prozessoren ACE nicht beherrscht, pflegt kaum ein Studio einen Pfad dafür. AVX-512 zeigt, wie lange das dauert. Der Befehlssatz existiert seit 2013, ein nennenswerter Nutzen außerhalb von Emulatoren und Spezialsoftware stellte sich im Spielebereich nie ein.
ACE startet zudem mit dem Nachteil, dass die erste Hardware noch aussteht. Die ersten Prozessoren mit Matrix-Engine werden frühestens 2028 auf Basis der kommenden Zen-7-Architektur erwartet. ACE ist noch Zukunftsmusik.
Mitmachen und kommentieren
Wie stehen Sie zu diesem Thema? Die PCGH-Redaktion freut sich schon über Ihre Meinung in den Kommentaren zu dieser Meldung. Sollten Sie hingegen noch keinen Extreme-Account haben, laden wir Sie zu einer Registrierung im Forum ein. Beachten Sie beim Kommentieren aber bitte die gültigen Forenregeln. Folgen Sie gerne PCGH bei 🔈 YouTube oder 💬 WhatsApp und erhalten Sie Neuigkeiten zu CPUs, Grafikkarten und Gaming direkt in Ihrem Feed.
Quelle: x86 Ecosystem Advisory Group via Tom's Hardware









Das mit den Sprachmodellen gefällt mir allerdings gut.