
Radeon RX 7900 XT(X) im Test: Technik-Details
Der erste RDNA-3-Chip namens Navi 31 bringt einige Neuerungen im Silizium. Ein tieferTechnik-Tauchgang für Interessierte.
In diesem Artikel
- Seite 1 Radeon RX 7900 XT(X) im Test: Spezifikation
- Seite 2 Radeon RX 7900 XT(X) im Test: Technik-Details
- Seite 3 Radeon RX 7900 XT(X) im Test: Benchmarks
- Seite 4 Radeon RX 7900 XT(X) im Test: Raytracing-Benchmarks
- Seite 5 Radeon RX 7900 XT(X) im Test: Lautheit, Verbrauch, Effizienz
- Seite 6 Radeon RX 7900 XT(X) im Test: Zusammenfassung mit Fazit
- Seite 7 Bildergalerie
Die dritte RDNA-3-Generation hat das Ziel, maximalen Ertrag aus relativ wenig Siliziumfläche zu ziehen und soll günstig zu fertigen sein. Dieses Ziel erfordert Kompromisse - und diese sind bei Navi 31, dem ersten Produkt mit RDNA-3-Genen, sehr interessant. Bevor wir zu den Benchmarks kommen, möchten wir daher ein paar Worte zu den Gedanken dahinter sowie der Umsetzung ins Silizium verlieren. Achtung, es wird stellenweise sehr technisch, wenngleich wir mit Vereinfachungen arbeiten.
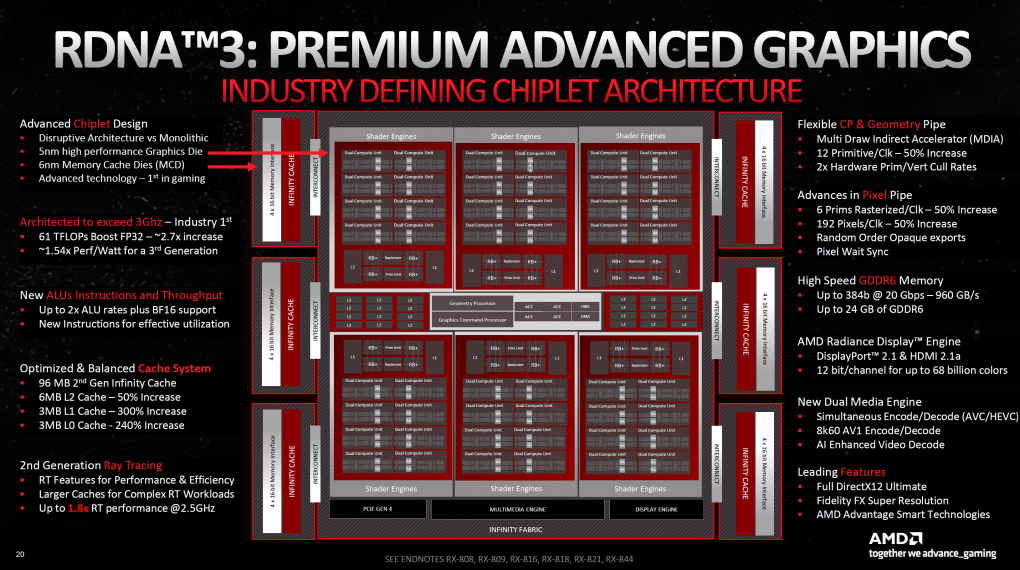
Den folgenden Zahlen ist eindeutig die Generation oder Radeon-"DNA" (= DNS, Erbgut) zu entnehmen. Navi 31 ist der erste Grafikprozessor einer neuen Serie, ihm werden im Laufe der kommenden Monate die GPUs Navi 32 und Navi 33 folgen. Je größer die zweite Ziffer, desto kleiner der Chip der jeweiligen Generation - hier sind sich AMD, Intel und Nvidia einig. Beginnen wir mit der Zusammenfassung von RDNA 3, welche alle Errungenschaften gegenüber RDNA 2 zeigt:
 Quelle: AMD
AMD RDNA 3 Chip Overview
Quelle: AMD
AMD RDNA 3 Chip Overview
Navi 31: Der Shader-Core
RDNA 3 ist der Technik-Nachfolger der Ende 2020 veröffentlichten RDNA-2-Mikroarchitektur. Diese baut wiederum auf dem Meilenstein RDNA, auch bekannt als Navi (1x), welche Mitte 2019 die viele Jahre genutzte "Graphics Core Next"-Architektur (GCN) ablöste. Ein aufgeräumter Shader-Core, bei AMD Compute Unit (CU) genannt, ermöglichten es Navi in Gestalt der Radeon RX 5700 (XT), pro Takt die Schlagkraft von Nvidias Turing-Chips zu erreichen. Dieser Schritt war überfällig, denn GCN trat in Sachen Instructions per Clock (IPC-Rate) jahrelang mehr oder minder auf der Stelle.
AMD hat mit RDNA die IPC-Rate der Compute Units (CU) genannt, deutlich erhöht, sodass mehr Netto vom Brutto übrigbleibt. Der wichtigste Punkt widmet sich den sogenannten "Waves" (AMD-Sprech) respektive "Warps" (Nvidia-Jargon). Aus Sicht eines Grafikchips entspricht eine Wave einem Bündel Rechenaufgaben mit 32 oder 64 Elementen ("Work Items"). Diese Aufgaben erreichen den Grafikchip über die Programmierschnittstelle (API), etwa DirectX oder Vulkan, und werden von einem Vorarbeiter - dem Scheduler - an eine Gruppe von Rechenwerken weitergereicht. Diese mehrheitlich arithmetisch-logischen Einheiten der GPU, kurz ALUs, kümmern sich um Shader-Kalkulationen wie Multiply & Add (Multiplikation & Addition; kurz MADD), meist im Gleitkommaformat FP32 (Floating Point mit 32 Bit Genauigkeit), beherrschen jedoch auch andere Datenformate wie INT32 (Integer, Ganzzahlen).
Jede Shader-Engine beinhaltet eine gewisse Anzahl Lanes, von AMD "Stream Processor" und von Nvidia "CUDA Core" genannt. Was sich zwischen GCN und RDNA unterscheidet, sind die Gruppierung der ALUs und die Granularität der Daten. Anstatt wie GCN alle vier Takte ein Wave64-Instruktionspaket zu bearbeiten, kommt Navi dank seiner doppelt so breiten SIMD32-Units und pro CU doppelt anwesendem Scheduler mit zwei Takten aus. Zwei entsprechende Blöcke stecken in jeder Compute Unit, welche daher seit RDNA als Dual Compute Unit oder Work Group Processor (WGP) bezeichnet wird. Die wichtigste Neuerung bei Navi geht noch einen Schritt weiter und wird standardmäßig genutzt: Der Shader Compiler kann die Daten im Wave32-Format anliefern, wobei Navi hier pro Takt ein Ergebnis ausspuckt. Auf diese effiziente Berechnungsweise setzt auch Nvidia (Warp32).
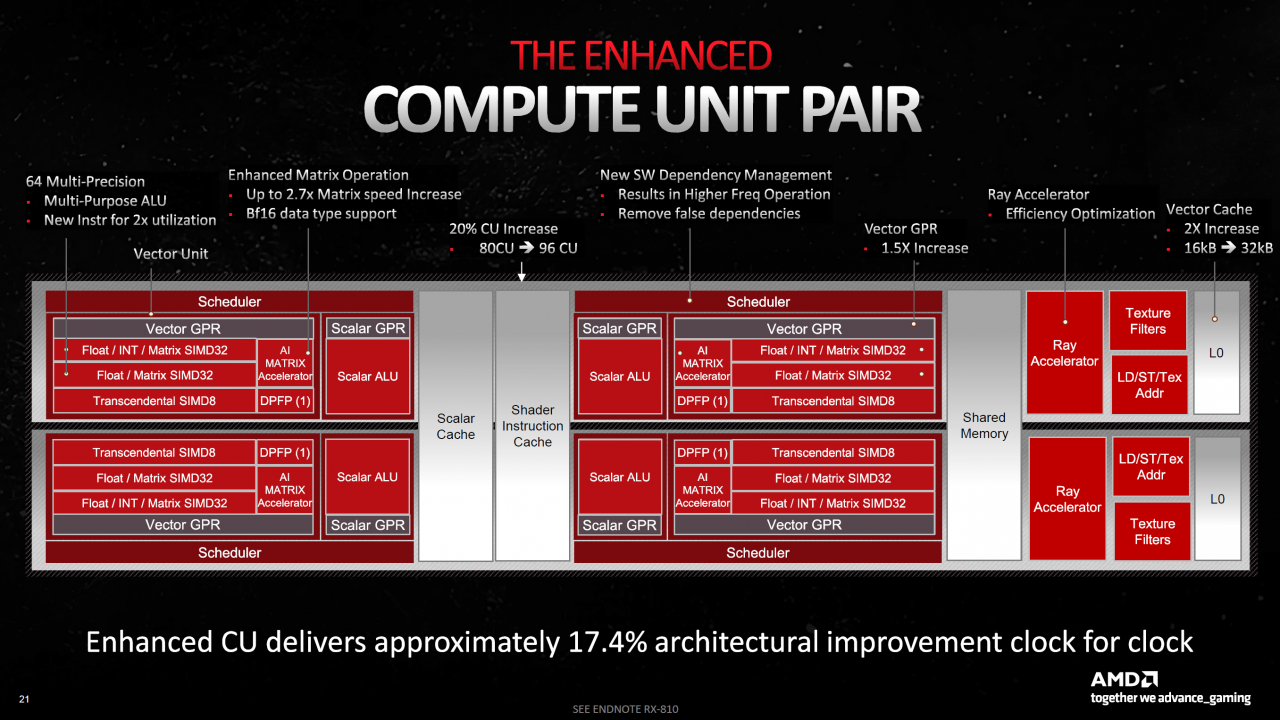

Wie bereits auf der vorigen Seite erwähnt, hat AMD die Compute Units bei RDNA 3 erneut aufgebohrt, um den größtmöglichen Nutzen aus der gegebenen Siliziumfläche zu ziehen. AMD spricht von einer rund 20-prozentigen Verbesserung gegenüber RDNA 2 und circa 17 Prozent mehr Leistung pro Compute Unit und Takt. Die wichtigste neue Funktion auf dem Weg dorthin hört auf die Bezeichnung "Dual Issue" und bezieht sich auf die gleichzeitig verdaubaren Waves. Folgt man den Schaubildern von AMD, weist RDNA 3 tatsächlich die doppelte Menge an FP32-Einheiten und Scheduler auf, allerdings spricht AMD dennoch nicht von der verdoppelten EInheitenmenge. Stattdessen ist mehrfach zu hören und lesen, dass RDNA 3 pro Takt bestenfalls die doppelte FP32-Rate von Navi 21 erreicht. Kein uns vorliegendes Tool bescheinigt Navi 31 annähernd die theoretisch abrufbaren 43 (XT) bis 57 TFLOPS (XTX), stattdessen sind Werte im hohen 30er-Bereich normal. Die Gaming-Benchmarks ab der folgenden Seite bestätigen, dass Dual Issue offenbar besondere Liebe aufseiten der Software respektive des Shader Compilers im Treiber bedarf. AMD nennt in diesem Kontext besondere, neue Instruktionen, um das Feature abzurufen. Möglicherweise limitieren bei RDNA 3 auch die Register, ähnlich wie bei Nvidias Ampere, doch das ist — Stand jetzt - nur eine Vermutung. Wir versuchen, weitere Informationen dazu aufzutreiben.


RDNA 3: World's first chiplet GPU
Was bei Prozessoren schon seit Jahren gemacht wird, hält nun auch bei Grafikkarten Einzug: RDNA 3 ist die erste GPU-Generation auf Basis von Chiplets. Damit ist die Herangehensweise gemeint, anstelle eines großen, monolithischen Chips mehrere kleine zu koppeln. Diese Idee schwirrt schon lange in den Köpfen der Ingenieure, erforderte jedoch zunächst reichlich Grundlagenarbeit. Chiplets sollen gleich mehrere Probleme umschiffen, darunter das dringendste: Transistoren lassen sich nicht mehr so einfach schrumpfen wie in den Pioniertagen des Computers, zusätzliche Rechenwerke führen daher zu immer größeren Chips. Je größer der Chip, desto größer auch das Risiko für einen Defekt innerhalb der Fertigung - hier liegt einer der Gründe, warum nur wenige High-End-Grafikkarten den jeweiligen, wertvollen GPU-Vollausbau tragen. AMDs erstes GPU-Chiplet, der Graphics Compute Die (GCD) von Navi 31, misst lediglich 300 mm² und damit nicht einmal die Hälfte von Nvidias AD102. Der GCD beinhaltet diverse SRAM-Caches bis inklusive Level 2 und läuft bei TSMC in moderner N5-Fertigung vom Band. Letztere ist wichtig, denn Logik-Transistoren profitieren von jedem Shrink. Die Schaltungen werden kleiner und erlauben daher mehr Einheiten pro Fläche und Watt (bzw. Joule). Durch seine geringe Größe sichert der GCD eine hohe Ausbeute auf den Wafern mit reduzierten Fertigungsfehlern, sprich: relativ günstige Preise.

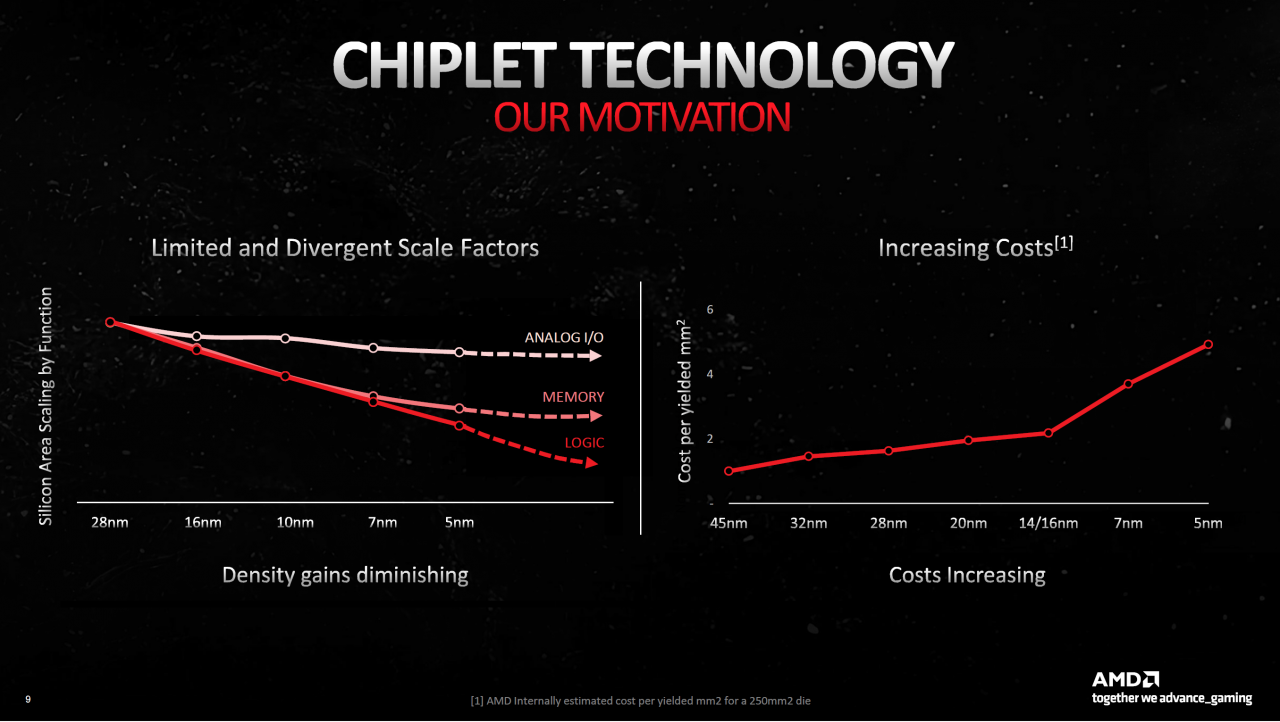
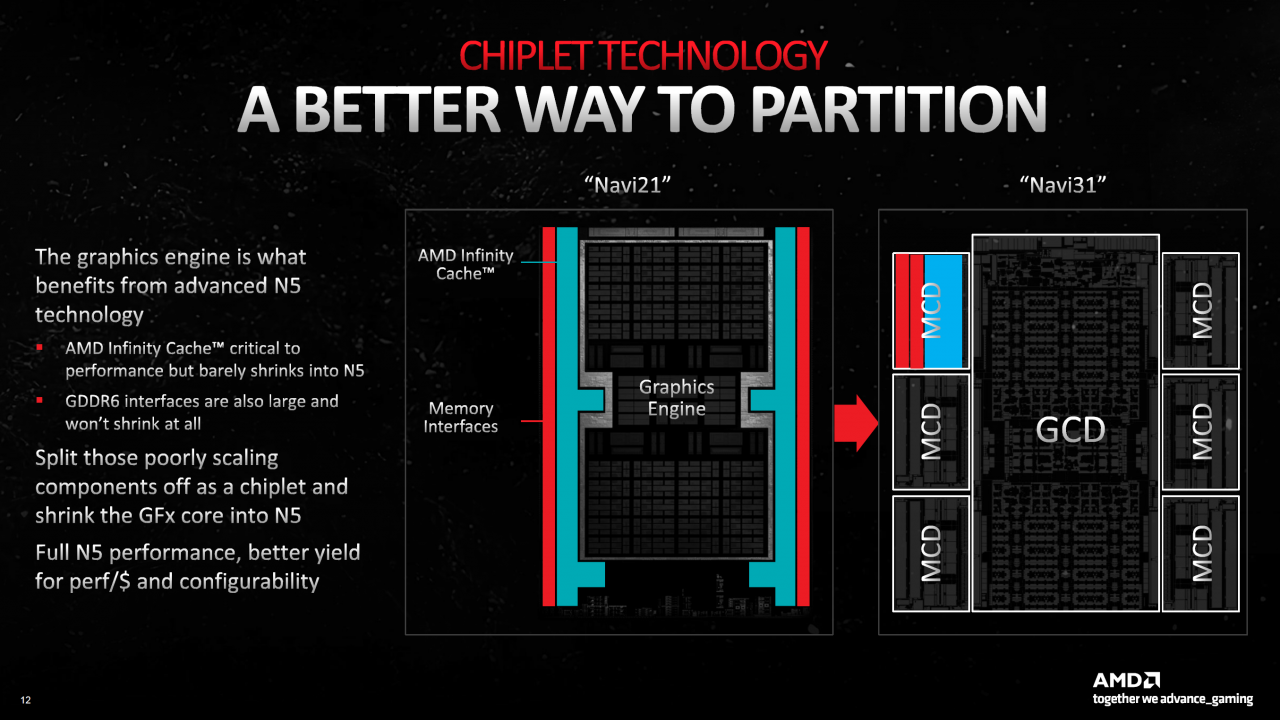




Der Clou ist die Anbindung zusätzlicher Memory Cache Dies (MCDs). Ein jeder MCD beinhaltet nicht nur die Speicher-Controller, welche mit dem anschließenden GDDR6-DRAM kommunizieren, sondern auch jeweils 16 MiByte SRAM - den "Infinity"-Level-3-Cache zweiter Generation (mehr dazu unten). Basierend auf der Erfahrung, dass Speicher-Controller (PHY) nur schlecht mit besserer Fertigung skalieren, wird der MCD im sprichwörtlich "gut abgehangenen" N6-Prozess gefertigt. Dank entsprechender Bibliotheken wird dennoch eine gute Packdichte erreicht - jeder MCD ist rechnerisch knapp 37 mm² groß - und spart gegenüber der N5-Fertigung Kosten ein. Allerdings müssen GCD und die sechs MCDs am Ende noch verheiratet werden, was einen gewissen Verdrahtungsaufwand und eine gemeinsame Trägerplatine (Interposer) erfordert. High-Bandwidth Memory (HBM) lässt grüßen, mit dem AMD seit 2015 Erfahrungen sammelt. Interessant ist, dass sechs MCDs laut AMD auf 220 mm² kommen, was zusammen mit dem 300-mm²-GCD die gleiche Gesamtgröße wie bei Navi 21 ergibt (520 mm²). Genaue Zahlen nennt AMD nicht (nur für CPUs), allerdings ist davon auszugehen, dass sich der nicht unbeträchtliche Aufwand gegenüber einem großen, monolithischen Chips gleicher Größe finanziell lohnt.
RDNA 3: Infinity Cache 2. Generation
RDNA 2 führte vor zwei Jahren den Infinity Cache ein, welcher damals direkt im Kern, zwischen L2-Cache und den DRAM-Controllern, platziert wurde. Dieser adaptiert das Wissen aus der Zen-Prozessor-Entwicklung, welche sich bereits seit Jahren mit großen und möglichst dicht gepackten Level-3-Caches auseinandersetzt. Zwar verschweigt AMD die Größe des 128 MiByte großen SRAM-Bereichs, milchmädchenhaft hochgerechnet nimmt der Infinity Cache in Navi 21 jedoch 102 mm² ein - ein großer Anteil des insgesamt 520 mm² großen Chips. Die Zugriffe auf den Cache sind nicht nur sehr schnell, jeder Umweg über den Speicher-Controller zum großen "Datengrab" DRAM kostet auch wesentlich mehr Energie. AMD gab zum RDNA-2-Launch an, dass man mit dem Infinity Cache Hitraten zwischen 58 und 80 Prozent erreiche. Das bedeutet vereinfacht ausgedrückt, dass viele Daten, die bereits aus dem knappen L2-Cache geschmissen wurden, im Infinity (L3-)Cache landen und die nächsten Berechnungen somit kaum verzögert werden. Man spricht dabei auch von einem Victim Cache, da dieser alle "Opfer"-Daten auffängt, die zu lange nicht abgefragt wurden und daher nicht mehr in der ersten Reihe sitzen (Eviction). Dabei gilt es zu beachten, dass jede Cache-Abfrage ein paar Zyklen Zeit kostet. Kommt es zu einem Fehlschlag (Miss), etwa weil die Daten nicht mehr im L3-Cache, sondern bereits im Grafikspeicher vorliegen, war die Aktion für die Katz und die Pipeline "stallt" kurz.


Bei RDNA 3 hat AMD die Größe des Level-3-Cache zwar von 128 auf 96 MiByte reduziert, dafür wurden die übrigen Caches im GCD um 50 bis 300 (!) Prozent aufgestockt und auch die Datenpfade zum DRAM um 50 Prozent erweitert (384 statt 256 Bit). AMD gibt an, dass man die Hit Rate (Erfolgsquote, im L3-Cache die richtigen Daten zu finden) verbessert habe, allerdings ist zu vermuten, dass weniger Cache auch weniger Erfolg bedeutet. Dies wird durch die größeren Zwischenspeicher L0 (+240 %), L1 (+300 %) und L2 (+50 %) abgefedert. Dank der um knapp 88 Prozent höheren Speichertransferrate ist eine Radeon RX 7900 XTX außerdem weniger anfällig für Cache-Misses als eine Radeon RX 6900 XT oder 6800 XT. Mit anderen Worten: Hohe Datenaufkommen, etwa in Ultra HD und darüber hinaus, sowie beim Raytracing, werden von Navi 31 besser weggesteckt als von Navi 21.
 Quelle: Wild_C via Twitter
AMD Navi 33, 32 und 31: AMDs kleinste RDNA-3-GPU wird laut aktuellem Kenntnisstand als einzige auf MCDs verzichten (Symbolbild für den Aufbau, einige der Daten stimmen nicht).
Quelle: Wild_C via Twitter
AMD Navi 33, 32 und 31: AMDs kleinste RDNA-3-GPU wird laut aktuellem Kenntnisstand als einzige auf MCDs verzichten (Symbolbild für den Aufbau, einige der Daten stimmen nicht).
Weitere Errungenschaften
Neben diesen Tweaks und Ergänzungen, die der generellen Leistung zugutekommen, hat AMD auch an die Zukunft der Grafik gedacht. RDNA 3 führt eine Reihe Verbesserungen ein, um Raytracing zu beschleunigen. Ein Teil davon kommt durch die erhöhte Compute-Leistung generell sowie die größeren Caches, ein anderer durch die Ray Accelerators zweiter Generation. Die entsprechenden Einheiten sind weiterhin pro Compute Unit einmal vorhanden (-> 96 in Navi 31 XTX, 84 in Navi 31 XT) und versierter beim Durchstöbern der Datenstruktur, was speziell komplexe Szenen beschleunigen soll. AMD nennt hier (bis zu) den Faktor 1,8 gegenüber RDNA 2. Außerdem verfügt RDNA 3 explizit über zwei "AI Matrix Accelerator" pro Compute Unit (-> 192 in Navi 31 XTX, 168 in Navi 31 XT), welche diverse für KI/Inferencing hilfreiche Berechnungen besonders schnell abarbeitet. Vermutlich wird FSR 3, AMDs Antwort auf DLSS 3, diese Rechenwerke zur Beschleunigung nutzen, derzeit ist das jedoch nur Spekulation.
 Quelle: AMD
AMD RDNA 3: Raytracing-Verbesserungen
Ferner unterstützt die RX-7000-Reihe, wie bereits RX 6000 und RX 5000, PCI-Express 4.0 - der von modernen Prozessor-Plattformen bereitgestellte 5.0-Standard hat es nicht in Navi 31 geschafft. Dafür bieten die Radeon RX 7900 XT/X als bisher einzige Grafikkarten Unterstützung für Displayport 2.1, um damit kommende Displays mit sehr hohen Auflösungen und Bildwiederholraten mit einem Kabel anzusteuern. Interessant ist auch, dass die Radeon RX 7900 XT/X, zumindest in Gestalt der AMD-Referenzkarten (MBA), weiterhin einen USB-C-Port alias Virtual Link anbieten. Dieser Standard erleichtert die Kommunikation mit VR-Headsets, indem Strom und Daten über ein einzelnes USB-C-Kabel übertragen werden. Auch Nvidia führte diesen Anschluss einst an der I/O-Blende, nämlich bei der RTX-20-Serie, entfernte diesen aber bei RTX 30 wieder. Davon ab beherrscht Navi 31, wie Arc und Ada mit geeigneter Software-Umgebung sowohl die En- als auch Dekodierung von AV1-Videomaterial. Dies geschieht auf Wunsch auch mit zwei Streams parallel, hier zieht AMD mit Nvidia gleich.
Quelle: AMD
AMD RDNA 3: Raytracing-Verbesserungen
Ferner unterstützt die RX-7000-Reihe, wie bereits RX 6000 und RX 5000, PCI-Express 4.0 - der von modernen Prozessor-Plattformen bereitgestellte 5.0-Standard hat es nicht in Navi 31 geschafft. Dafür bieten die Radeon RX 7900 XT/X als bisher einzige Grafikkarten Unterstützung für Displayport 2.1, um damit kommende Displays mit sehr hohen Auflösungen und Bildwiederholraten mit einem Kabel anzusteuern. Interessant ist auch, dass die Radeon RX 7900 XT/X, zumindest in Gestalt der AMD-Referenzkarten (MBA), weiterhin einen USB-C-Port alias Virtual Link anbieten. Dieser Standard erleichtert die Kommunikation mit VR-Headsets, indem Strom und Daten über ein einzelnes USB-C-Kabel übertragen werden. Auch Nvidia führte diesen Anschluss einst an der I/O-Blende, nämlich bei der RTX-20-Serie, entfernte diesen aber bei RTX 30 wieder. Davon ab beherrscht Navi 31, wie Arc und Ada mit geeigneter Software-Umgebung sowohl die En- als auch Dekodierung von AV1-Videomaterial. Dies geschieht auf Wunsch auch mit zwei Streams parallel, hier zieht AMD mit Nvidia gleich.

- Seite 1 Radeon RX 7900 XT(X) im Test: Spezifikation
- Seite 2 Radeon RX 7900 XT(X) im Test: Technik-Details
- Seite 3 Radeon RX 7900 XT(X) im Test: Benchmarks
- Seite 4 Radeon RX 7900 XT(X) im Test: Raytracing-Benchmarks
- Seite 5 Radeon RX 7900 XT(X) im Test: Lautheit, Verbrauch, Effizienz
- Seite 6 Radeon RX 7900 XT(X) im Test: Zusammenfassung mit Fazit








Aber wie weit reicht dir das?
Wenn du mit gelegentlichen Unschärfe und böses Ghosting leben kannst, kommst du mit einer heute gekauften 4080 + doch wohlmöglich bis innert den nächsten 2 Jahren klar !mit Raytracing!, versteht sich.
Hier drin bin ich jedoch nicht der Massstab. Mir sind beide zu teuer.
PS: will noch anmerken, ich bin AMD Fan und von der RX7000er recht entäuscht.
Probleme mit VR, Idle Power und HDR Recording. Rückblickend, nicht super tragisch aber auch kein Grund zum Lob.
Und beide haben eine Ewigkeit keine Mainstream Karten der aktuellen Generation raus gebracht und somit den Markt ausgepresst!
Ich bin zwar schon gedeckt, aber begrüsse den Entscheid, keine Highend Karte raus zu bringen ala RX8000XTXSuperExtrem.
Dem Kollegen habens die RTX Adds angetan und jetzt will Er den Braten probieren.
Cyberpunk2077 ist NVs Game und da muss man nichts mehr sagen.
Aber wenn es eine Zeit geben soll nach Cyberpunk2077 würde ich auch zur 7900xtx tendieren, ist diese doch immer noch günstiger und schneller im Normalfall als auch immer noch brauchbar für Raytracing.
So wie das aber mit Pathtracing voran getrieben wird, bringen es beide nicht mehr bei den kommenden Projekten.
Dem Kollegen habens die RTX Adds angetan und jetzt will Er den Braten probieren.
Cyberpunk2077 ist NVs Game und da muss man nichts mehr sagen.
Aber wenn es eine Zeit geben soll nach Cyberpunk2077 würde ich auch zur 7900xtx tendieren, ist diese doch immer noch günstiger und schneller im Normalfall als auch immer noch brauchbar für Raytracing.
So wie das aber mit Pathtracing voran getrieben wird, bringen es beide nicht mehr bei den kommenden Projekten.
Es gibt nur ein paar wenige Spiele, die auch meist von AMD unterstützt wurden, wo das Raytracing auf den Radeons besser oder zumindest gleich schnell berechnet wird. Aber das sind dann immer nur einfache RT-Effekte - bspw. Schatten.
AMD ist sich des Rückstands bewusst, und das sie daran etwas ändern müssen, aber das funktioniert nicht durch Treiber-Updates, das erfordert neue Hardware. Bleibt abzuwarten ob bereits mit RDNA4, oder erst mit RDNA5 der Abstand deutlich verringert werden kann - hoffentlich nicht noch später.
Wem aktuell hohe Raytracing-Details wichtig sind, der sollte zu einer RTX-40 greifen.
Letztendlich hängt es natürlich vom Budget ab, denn es kann vorkommen das eine Radeon eine vergleichbare RT-Leistung für einen ähnlichen bis geringeren Preis zu bekommen ist. An eine 4080 kommt derzeit jedoch keine Radeon heran.
Im Falle der XTX müsste der Preis auf das Preisniveau der 4070 TI fallen ... Man könnte bei der XTX ein leichten Aufpreis als gerechtfertigt ansehen - wie viel, muss jeder für sich selbst beantworten -, der doppelte Grafikspeicher lässt sich schließlich nicht wegdiskutieren ...
PS: AMDs Gegenstück zu DLSS ist FSR, und zu Frame Generation (FG) ist es Fluid Motion Frames (FMF).