
Radeon RX 5700 (XT) im Test: Techniktauchgang
RDNA? GCN? OMG! In diesem Artikelabschnitt werfen wir einen Blick unter die Haube von Navi 10.
Auf dieser Seite

[/h3]
Radeon RX 5700 (XT) im Test: Technik-Tauchgang für Turbonerds
Navi 10 mag nur eine Mittelklasse-GPU sein, doch ein Blick unter die Haube offenbart große Änderungen gegenüber seinen Vorgängern. Tatsächlich ist RNDA, so der neue Architekturname, die größte und interessanteste Umstellung seit "Graphics Core Next" (GCN) Anfang 2012. In diesem Artikelabschnitt entfernen wir die Haube und schauen in den Motor. Achtung, es wird technisch - die graue Theorie hilft jedoch beim Colorieren der anschließenden Benchmarks.
 Quelle: AMD
AMD Radeon RX 5700 und RX 5700 XT im Test: Erfolgreicher Angriff auf die Geforce-RTX-Phalanx (25)
Handelt es sich bei Navi nun um eine neue Mikroarchitektur oder nicht? Laut AMD schon, denn der Hersteller bezeichnet alle Chips seit Tahiti als "GCN", mit Vega als Spitze der Entwicklung (GCN 1.4). Navi wird hingegen als neue RDNA-Architektur vermarktet. Letztlich ist es eine Frage der Auslegung. Die Instruction Set Architecture (ISA) mit ihrem Mix aus Vektor- und Skalar-Instruktionen wird von GCN übernommen, die federführende Hardware geht die Arbeit jedoch anders an.
Quelle: AMD
AMD Radeon RX 5700 und RX 5700 XT im Test: Erfolgreicher Angriff auf die Geforce-RTX-Phalanx (25)
Handelt es sich bei Navi nun um eine neue Mikroarchitektur oder nicht? Laut AMD schon, denn der Hersteller bezeichnet alle Chips seit Tahiti als "GCN", mit Vega als Spitze der Entwicklung (GCN 1.4). Navi wird hingegen als neue RDNA-Architektur vermarktet. Letztlich ist es eine Frage der Auslegung. Die Instruction Set Architecture (ISA) mit ihrem Mix aus Vektor- und Skalar-Instruktionen wird von GCN übernommen, die federführende Hardware geht die Arbeit jedoch anders an.
Stellen Sie sich vor, Sie hätten vier Arme und wie praktisch das beim Schleppen von Einkäufen wäre.
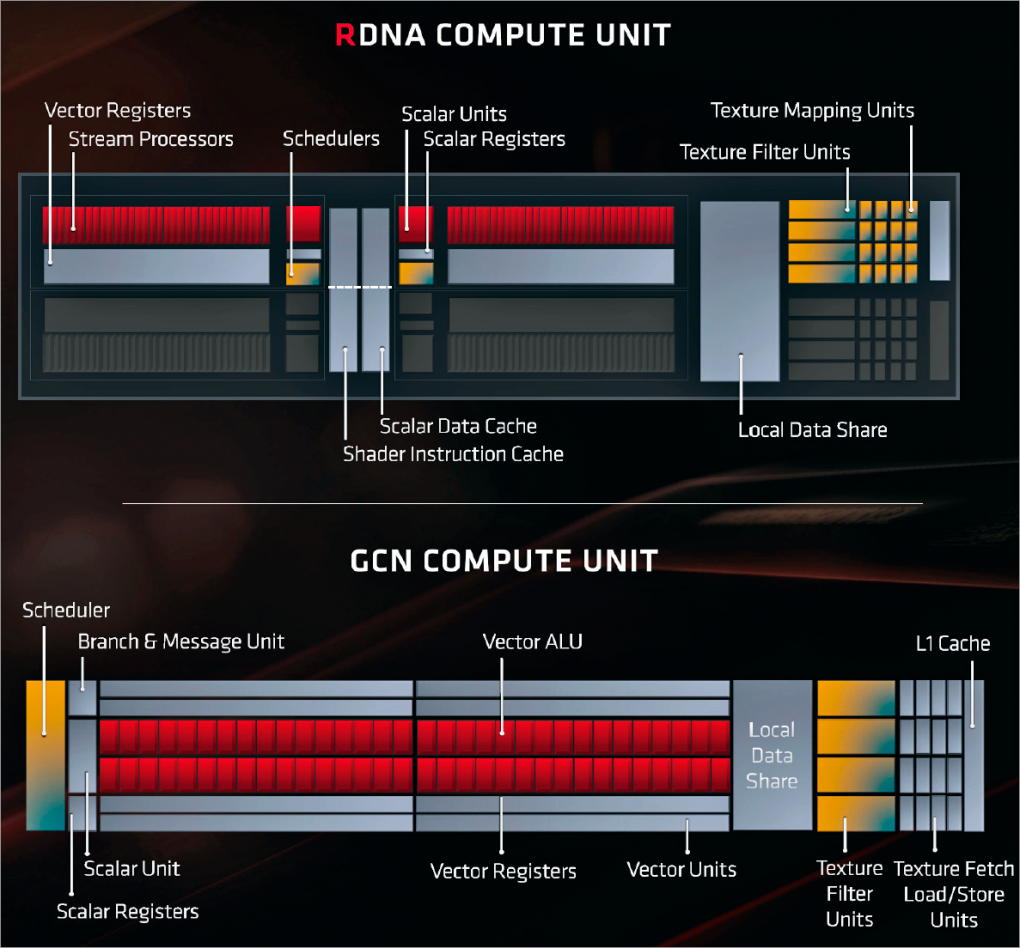
Spätestens seit Intels Pentium 4 wissen wir, dass Takt nicht alles ist. Der Fähigkeit eines Prozessors, pro Zyklus möglichst viele Dinge zu erledigen, wird heutzutage eine wesentlich wichtigere Rolle zuteil. Im Pflichtenheft für das Navi-Projekt stand daher der Punkt "Instructions per clock" (IPC; Instruktionen pro Takt) ganz oben. AMD hat die IPC-Rate der Shader-Einheiten, Compute Units genannt, erhöht, anstatt weiter in die Breite zu gehen. Letzteres war die bisherige Marschrichtung der Radeon Technologies Group: mehr Rechenkerne gleich mehr Leistung. Nun geht der Fokus auf "mehr Arbeit auf einmal", Navi 10 stemmt pro Zyklus mehr Instruktionen als seine Vorgänger. Stellen Sie sich vor, Sie hätten vier Arme und wie praktisch das beim Schleppen von Einkäufen wäre. Schnellere Ergebnisse und bessere Auslastung sind die Stichworte. Die komplette Arbeitsweise einer GPU zu erklären, würde diesen Artikel sprengen, daher behandeln wir nur die wichtigsten, von AMD genannten Punkte.
Der wohl wichtigste Punkt widmet sich den sogenannten "Waves" (Nvidia nennt sie "Warps"). Aus Sicht eines Grafikchips entspricht eine Wave einem Bündel zugeschickter Rechenaufgaben mit 64 Elementen ("Work Items"). Diese Aufgaben werden von den Shader-ALUs, also den arithmetisch-logischen Einheiten der GPU, abgearbeitet. Um ganz genau zu sein: Bei den ALUs handelt es sich um Vector Execution Units, die sich um Shader-Kalkulationen wie Multiply & Add (Multiplikation & Addition; kurz MADD) im FP32-Format kümmern. Jede Einheit beinhaltet eine gewisse Anzahl Lanes, von AMD "Stream Processor" und bei Nvidia "CUDA Core" genannt. Jede Compute Unit beinhaltet 64 dieser Lanes. Was sich zwischen GCN und RDNA unterscheidet, ist die Aufteilung bzw. Granularität. Bisherige AMD-GPUs arbeiten nach dem Wave64-Prinzip, widmen sich folglich 64 Instruktionen auf einmal, bis ein Ergebnis vorliegt und das Programm weiterläuft. Diese grobkörnige Abarbeitung funktioniert gut, wenn der Code keine Verzweigungen ("Branches") respektive Abhängigkeiten enthält. Kommen diese vor, muss die Arbeit auf mehrere Zyklen aufgeteilt werden - mit fatalen Folgen für Auslastung und somit die Nettoleistung. Bisherige AMD-GPUs mit ihren "16-wide" SIMD-Einheiten (SIMD16) benötigen für eine 64er-Welle insgesamt 4 Zyklen, erst danach widmet man sich folgenden Instruktionsblöcken. AMD beziffert die IPC-Rate auf Work-Item-Basis daher mit 0,25 (1/4).
AMDs neuer Chip Navi arbeitet feinkörniger. Anstatt alle vier Takte ein Wave64-Instruktionspaket zu bearbeiten, kommt er dank seiner doppelt so breiten SIMD32-Units und pro CU doppelt anwesendem Scheduler mit zwei Takten aus. Zwei entsprechende Blöcke stecken in jeder Compute Unit. Die wichtigste Neuerung bei Navi geht noch einen Schritt weiter: Der Shader Compiler kann die Daten optional auch im "mundgerechten" Wave32-Format anliefern, beispielsweise wenn die Applikation viele voneinander abhängige Kalkulationen anfordert. Navi spuckt hier pro Takt ein Ergebnis aus. Der Wave32-Betrieb hilft folglich dabei, die Rechenwerke besser auszulasten, gleichzeitig wird aufgrund der kleineren Datenhappen weniger Platz in den GPU-internen Speichern belegt. Die IPC-Rate beträgt ergo 0,5 (1/2) oder bestenfalls 1 - Faktor 4 gegenüber GCN. Es sind jedoch auch unoptimierte Fälle denkbar, wo all das schiefläuft und die IPC-Rate sinkt.
Schnelltest: ALU-Latenz
Wir wollten die ALU-Latenz für eine MADD-Operation genauer wissen und haben daher ein spezielles Testprogramm dazu befragt. Eine Möglichkeit der Überprüfung ist, einen komplexen Shader über ein einziges Pixel zu jagen und dabei die Zeit zu messen. Gesagt, getan. Bitte beachten Sie, dass das Tool bereits einige Jahre auf dem Buckel hat und daher nicht der Weisheit letzter Schluss ist. Interessant ist das RDNA benötigt in diesem speziellen Fall 5 Zyklen, bis das Ergebnis vorliegt.
Ergebnis jedoch allemal: RDNA in Form der Radeon RX 5700 (XT) benötigt in diesem speziellen Fall 5 Zyklen, bis das Ergebnis vorliegt. Die ebenfalls herangezogenen Geforce-Modelle RTX 2070 und RTX 2070S spucken nach 4 Takten ein Ergebnis aus. 4 Zyklen benötigen auch die GCN-basierten Modelle Radeon RX Vega 64 sowie Radeon R9 Fury X, wohingegen eine Pascal-Geforce wie die GTX 1080/1070 sich sogar 6 Takte Zeit lassen. Navi kann ergo auch langsamer sein als Vega & Co., in der Praxis wird dies jedoch so gut es geht umschifft und mithilfe hoher Taktfrequenzen kaschiert. Wir werden weitere Tests anstellen, um der Sache auf den Grund zu gehen.
 Quelle: AMD
AMD Radeon RX 5700 und RX 5700 XT im Test: Erfolgreicher Angriff auf die Geforce-RTX-Phalanx (22)
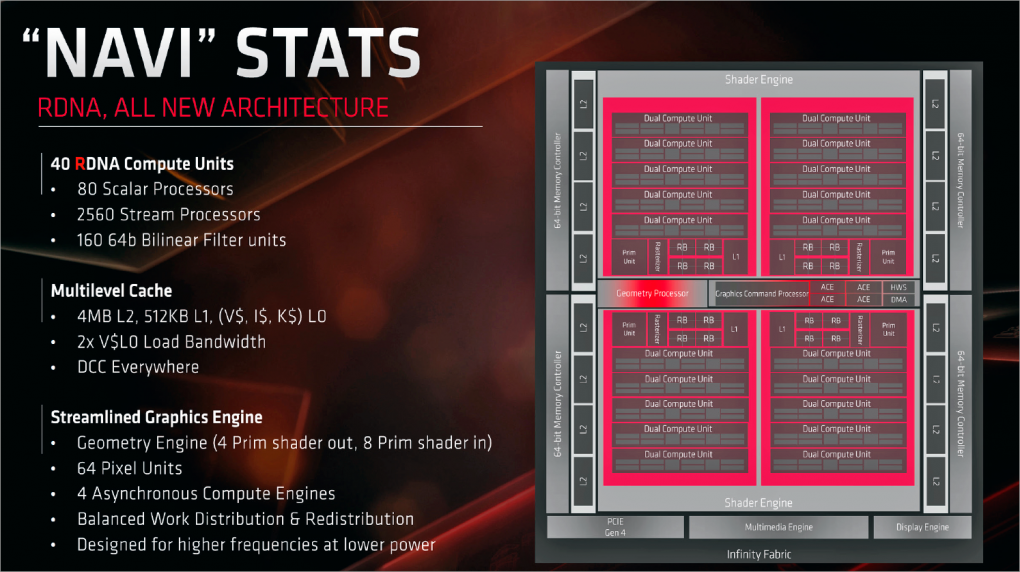
Klasse statt Masse, könnte man insgesamt sagen. Bei den größten GCN-Chips gilt das Gegenteil "Masse statt Klasse": Sie verfügen nicht bloß über ein breites Shader Array mit insgesamt 64 Compute Units, auch die Schnittstelle zum Speicher folgt dem Prinzip. AMD installiert im Falle von Fiji und Vega 20 ein 4.096-Bit-Interface für eine hohe Transferrate zum Grafik-DRAM. Im Vergleich mit den GPU-internen Zwischenspeichern, den Caches, ist jedoch selbst das langsam und vor allem latent. Navi widmet sich auch dieser Baustelle und führt eine neue Cache-Hierarchie ein, um die Datenlokalität innerhalb der GPU zu erhöhen. Werfen wir zunächst einen Blick auf Vega: Er verfügt pro Compute Unit über einen 16 KiByte fassenden Level-1-Cache (= 1 MiB SRAM im ganzen Chip), zusätzlich teilen sich alle CUs einen 4 MiByte großen L2-Cache. Hierarchisch betrachtet fungiert der als letztes angeschlossene Grafikspeicher als "off-chip L3-Cache".
Quelle: AMD
AMD Radeon RX 5700 und RX 5700 XT im Test: Erfolgreicher Angriff auf die Geforce-RTX-Phalanx (22)
Klasse statt Masse, könnte man insgesamt sagen. Bei den größten GCN-Chips gilt das Gegenteil "Masse statt Klasse": Sie verfügen nicht bloß über ein breites Shader Array mit insgesamt 64 Compute Units, auch die Schnittstelle zum Speicher folgt dem Prinzip. AMD installiert im Falle von Fiji und Vega 20 ein 4.096-Bit-Interface für eine hohe Transferrate zum Grafik-DRAM. Im Vergleich mit den GPU-internen Zwischenspeichern, den Caches, ist jedoch selbst das langsam und vor allem latent. Navi widmet sich auch dieser Baustelle und führt eine neue Cache-Hierarchie ein, um die Datenlokalität innerhalb der GPU zu erhöhen. Werfen wir zunächst einen Blick auf Vega: Er verfügt pro Compute Unit über einen 16 KiByte fassenden Level-1-Cache (= 1 MiB SRAM im ganzen Chip), zusätzlich teilen sich alle CUs einen 4 MiByte großen L2-Cache. Hierarchisch betrachtet fungiert der als letztes angeschlossene Grafikspeicher als "off-chip L3-Cache".
Navi verfügt über eine weitere Cache-Stufe dazwischen: Was bei Vega und Polaris der L1-Cache ist, entspricht bei Navi dem "L0". Hier teilen sich stets zwei Compute Units eine Cache-Partition (Datenaustausch zwischen den Einheiten ist möglich), welche nun mit doppelter Transferrate angebunden ist. Den neuen L1-Cache teilen sich jeweils fünf Dual Compute Units, chipweit stehen somit 512 KiByte zur Verfügung. Diese Zwischenablage dient dazu, die Daten möglichst nah bei den Rechenwerken zu halten, anstatt in den langsameren L2-Cache auszulagern. Letzterer ist mit 4 MiByte unverändert groß, allerdings steht jeder Compute Unit ein größerer Bereich zu als bei Vega. Letzteres ergibt sich automatisch dadurch, dass Navi nur 40 anstelle von (bis zu) 64 CUs beherbergt. Weitere Unterstützung beim Vorhaben, die Daten schnell intern zu bearbeiten, kommt durch die erneut verbesserte Delta Color Compression (DCC). Diese verlustfreie Kompression funktioniert nun innerhalb der kompletten Grafik-Pipeline und reduziert den Bandbreitenbedarf - nicht aber die Belegung.
GPU-interne SRAM-Datentransfers erweisen sich stets als energieeffizienter als der Umweg über den Speicher-Controller zum DRAM. Über eine hohe Transferrate zu Letzterem verfügt Navi in den Varianten RX 5700 und 5700 XT dennoch, AMD installiert vier 64-Bit-Controller, ergo eine 256-Bit-Schnittstelle, welche mit GDDR6-Speicher kommuniziert. Beide Modelle arbeiten mit 14 Gigatransfers pro Sekunde (GT/s), resultierend in 448 GByte/s Datendurchsatz - exakt so viel wie bei der RTX 2080/2070(S)/2060S. Dass all das im Zusammenspiel funktioniert, haben wir in ersten synthetischen Benchmarks festgehalten: Der GPGPU-Test des Tools AIDA64 bescheinigt Navi 10 eine hervorragende effektive Transferrate, welche natürlich (oder gerade) Spielen zu Gute kommt.
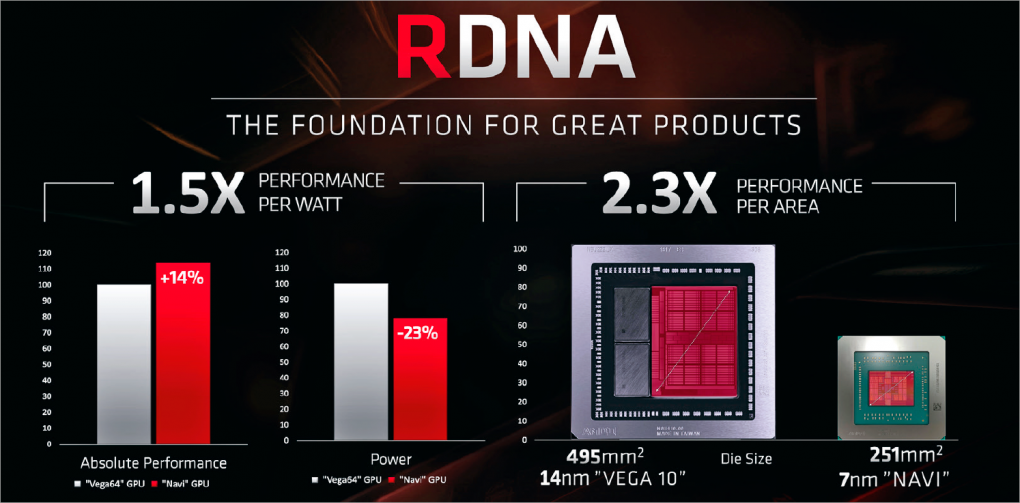
Neben den genannten Änderungen der nun "Dual Compute Unit" genannten Shader-Rechenwerke gibt es weitere Änderungen in Navi 10 respektive RDNA zu vermelden. Da wären die nunmehr 64 ROPs (Render-Backends alias Raster-Endstufen) anstelle von nur 32 bei Polaris, die nun (hoffentlich) funktionierenden Primitive Shaders zur effizienteren Geometrieberechnung sowie die aufgebohrten Texturfiltereinheiten. Hinzu kommt die Unterstützung der neuen Schnittstelle PCI-Express 4.0, sofern der Unterbau mitspielt - ein X570-Mainboard nebst Ryzen-3000-Prozessor ist hierfür Stand jetzt Pflicht.
 Quelle: AMD
AMD Radeon RX 5700 und RX 5700 XT im Test: Erfolgreicher Angriff auf die Geforce-RTX-Phalanx (23)
Quelle: AMD
AMD Radeon RX 5700 und RX 5700 XT im Test: Erfolgreicher Angriff auf die Geforce-RTX-Phalanx (23)









Geb ich meinem Mieter, der zockt gern X Box
Außerdem läuft die VII den Karten auch in Titeln mit Bandbreitenskalierung noch ne ganz weile davon. Die VII hat einfach die geileren Frametimes, vor allem gepimpt ist das schon erstklassig.
8GB ist echt nichts, selbst bei Assasins Creed Odyssey bin ich gerade bei 7,5GB VRAM Auslastung, würd ich jetzt noch paar Grafik Mods installieren bin ich locker über den 8GB VRAM... das kann ich mir wohl erstmal stecken...
Dadurch das ich die Vega 64 ja auch so günstig bekommen hab ist das bei der noch nicht mal nen Minus geschäft.
Schön wäre halt auch noch eine Aktion von Asus/MSI oder Sapphire mit der 5700XT das von AMD mit diesem Game Pass haut mich jetzt ehr nicht vom Hocker und interessiert mich auch 0...
https://www.pcgameshardwa...
AMD scheint die Karte schon beerdigt zu haben weil man eben meistens bei Navi mit weniger Aufwand das selbe Ergebnis schafft.
Aber anscheinend noch nicht ganz offiziell.
https://www.pcgameshardwa...
AMD scheint die Karte schon beerdigt zu haben weil man eben meistens bei Navi mit weniger Aufwand das selbe Ergebnis schafft.
Aber anscheinend noch nicht ganz offiziell.
Außerdem läuft die VII den Karten auch in Titeln mit Bandbreitenskalierung noch ne ganz weile davon. Die VII hat einfach die geileren Frametimes, vor allem gepimpt ist das schon erstklassig.