AMD Ryzen 5000: Die Zen-3-Architektur im Detail
AMDs neue AM4-Prozessoren machen da weiter, wo die Vorgänger eigentlich nie aufgehört hatten: Mit der klaren Marktdominanz, insbesondere auch im High-End-Bereich. Aber wie wird die beachtliche Mehrleistung eigentlich erreicht, obwohl die Taktraten nur geringfügig steigen?

Auf dieser Seite
In den Augen von Endanwendern sind AMDs Zen-CPUs seit Vorstellung des Ryzen 1800X und seiner kleineren Brüder der Maßstab, an dem sich alle anderen Prozessoren messen lassen müssen - meist mit wenig erfreulichem Ergebnis für die Konkurrenz. Dabei werden Technik und Vermarktung aber gerne vermischt, denn das AMD seit bald vier Jahren in allen Preisklassen außer "überteuert" die besseren Prozessoren anbietet ist nur teilweise der genutzten Technik geschuldet. Die meiste Zeit wurden schlicht große, komplexe CPUs mit geringerer Marge verkauft als bei Intel üblich. Für Endkunden ist es dann natürlich erfreulich, wenn er einen überlegenen Acht- günstiger als einen Sechskerner bekommt oder ein Zwölfender ähnlich teure Achter schlägt. Die bessere Ingenieursarbeit liefert aber derjenige, der bei gleichem Aufwand mehr erreicht - und um diesen, erst mit Zen 3 durchgängig erreichten Zustand soll es im vorliegenden Artikel gehen: Was kann Ryzen 5000, was andere nicht können?
Zen-3-Architektur: Das SoC im Überblick
Schaut man einem 5950X unter den Heatspreader, könnte man zunächst meinen, nichts Neues zu sehen. Natürlich unterscheidet sich AMDs aktueller Chiplet-Ansatz radikal von älteren Prozessoren beziehungsweise von Intels monolithischen Core-i-Modellen, aber das alles ist keine Neuerung der Zen-3-CPUs (Codename Vermeer). Tatsächlich bestätigt AMD, dass der zentrale I/O-Chip (IOD) im Package unverändert von den Zen-2-Vorgängern (Matisse) übernommen wurde. Damit steht auch fest, dass sich an den externen Schnittstellen nichts ändert - Dual-Channel DDR4-3200, 20 freie PCI-Express-4.0-Lanes, vier USB-3.1-Ports und eine Reihe kleinerer Schnittstellen kennt man schon von Ryzen 3000.
 Quelle: AMD
Im Norden nichts Neues: Den IOD, der weitestgehend einer klassischen Northbridge entspricht, übernimmt Vermeer von Matisse. Aber die innere Organisation der CCD ist neu.
Quelle: AMD
Im Norden nichts Neues: Den IOD, der weitestgehend einer klassischen Northbridge entspricht, übernimmt Vermeer von Matisse. Aber die innere Organisation der CCD ist neu.
Selbst mit einem neuen I/O-Chip hätte AMD hier auch keine reichere Ausstattung bieten können, ohne einen neuen Sockel einzuführen, denn der AM4 soll auch den Einsteiger- und Budget-Markt bedienen. Seiner Komplexität sind also Preisgrenzen gesetzt, die beispielsweise die in allen CPU-Generation einschließlich des Ryzen-5000-I/O-Chips vorhandenen 32 PCI-Express-Lanes seit jeher auf die genannten 20 plus 4 für die I/O-Hubs beschränken. Selbige übernimmt Zen3 ebenfalls vom Vorgänger: X570, B550 und A520. B450- und X470-Mainboards sollen, mit Verzögerung und Einschränkungen, ebenfalls UEFI-Updates für Zen 3 erhalten, die 300er-Vorgängergeneration mit physisch nahezu identischem Silizium wurden dagegen von AMD für Ryzen-5000-inkompatibel erklärt. Technisch betrachtet sind alle Ryzen-Prozessoren aber weiterhin "systems on a chip" (oder besser: "on a substrate"), das heißt alle Basis-Funktionen sind im CPU-Package untergebracht, das unabhängig von etwaigen I/O-Hubs arbeiten kann. Letztere dienen lediglich als optionaler Schnittstellenvervielfältiger und alle assoziierten Eigenschaften jenseits der Zahl von USB-, SATA- und PCI-E-Schnittstellen können getrost der Vermarktungsstrategie zugeschrieben werden.
Zen-3-Architektur: Der neue CCX
Genug aber von dem, was gleichbleibt. Zen 3 bearbeitet vor allem in Spielen deutlich mehr Daten pro Takt als der Vorgänger und diese müssen irgendwo herkommen. Der gleichbleibende Speichercontroller liefert sie nicht, die Gesamt-Cache-Größe gibt AMD ebenso unverändert mit 4 MiB L3, 0,5 MiB L2 und 2× 32 KiB L1 pro Kern an. Neu ist aber die Organisation der dritten Cache-Stufe und damit auch der Kerne selbst. Seit Zen 1 gruppierte AMD je vier Kerne zusammen mit vier gemeinsam nutzbaren L3-Cache-Patitionen zu einem Compute Cluster (CCX). Je zwei dieser CCX wurden bei Zen 2 auf einem gemeinsamen Compute-Chip (CCD) platziert und bis zu zwei CCDs formten dann, zusammen mit dem IOD den Prozessor. Bei Zen 3 sitzen jetzt aber alle acht Kerne eines CCDs in einem gemeinsamen, doppelt so großen CCX.
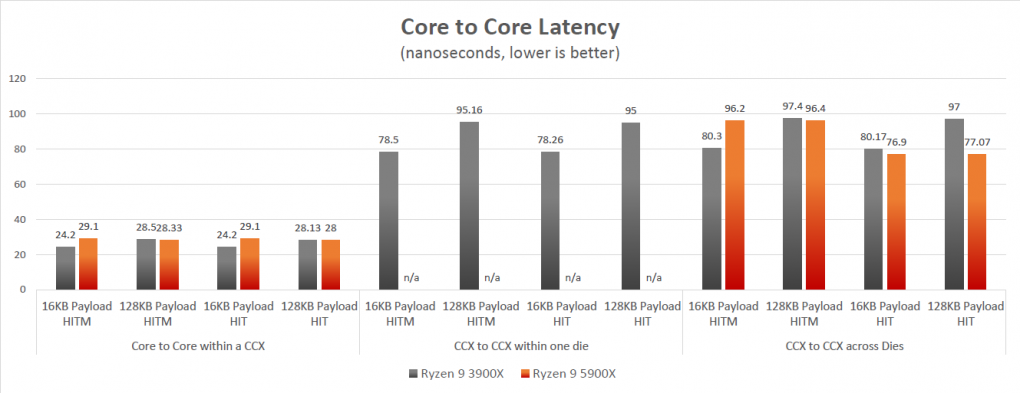 Quelle: AMD
Nein, der Zen-3-L3-Cache ist nicht schneller geworden – trotz seiner doppelten Größe aber auch kaum langsamer als bei Zen 2. Das Leistungsplus entsteht durch die Abwicklung von viel mehr Anfragen innerhalb eines CCX, erst jenseits von acht involvierten Kernen muss Zen 3 auf langsamere, externe Schnittstellen zurückgreifen, wie sie "zusammengeklebte" Multi-Cores spätestens seit dem Core 2 Quad plagen.
Quelle: AMD
Nein, der Zen-3-L3-Cache ist nicht schneller geworden – trotz seiner doppelten Größe aber auch kaum langsamer als bei Zen 2. Das Leistungsplus entsteht durch die Abwicklung von viel mehr Anfragen innerhalb eines CCX, erst jenseits von acht involvierten Kernen muss Zen 3 auf langsamere, externe Schnittstellen zurückgreifen, wie sie "zusammengeklebte" Multi-Cores spätestens seit dem Core 2 Quad plagen.
Dadurch ändert sich nichts an der Zahl der Recheneinheiten oder den Speichergrößen, aber massiv am Datenverkehr. Da jeder Kern innerhalb eines CCX direkt auf jede L3-Partition zugreift, können jetzt bis zu 32 MiB statt bislang 16 MiB L3 Cache für einen einzelnen Thread genutzt werden. Bei mehr als zwei (Achtkerner) beziehungsweise vier großen Threads (Zwölfkerner+) punktet das neue Konzept weiterhin mit einem beschleunigten Datenaustausch. Die Kommunikation von CCX zu CCX über das für den Datenaustausch zwischen Chips konzipierte Infinity Fabric, das gemessen an der Transfergeschwindigkeit innerhalb eines CCX ziemlich lahm ist. Mit nur halb so vielen CCX bei gleicher Kernzahl halbiert sich aber die Zahl der Datenabfragen, die diesen um bis zu Faktor 4 langsameren Weg gehen müssen.
Zen-3-Architektur: Das verbesserte Front-End
Schnellere Zugriffe auf größere L3-Bereiche versorgen die Kerne besser mit Daten, helfen aber nicht bei deren Bearbeitung. Deswegen hat AMD zusätzlich diverse Optimierungen an den Zen-Kernen der dritten Generation vorgenommen. Eher wage bleibt man bei der Befehlsaufbereitung. Die Sprungvorhersage soll nur wenig präziser, dafür aber deutlich schneller geworden sein. Letzteres betrifft sowohl die Zahl der Vorhersagen in einem gegebenen Zeitraum und deren Übergabe an folgende Pipeline-Stufen als auch den Wechsel zwischen bereits decodierten Instruktionen im Macro-Op-Cache einerseits und der energie- und zeitaufwendigen Decodierung neuer, also in den letzten Taktzyklen nicht verwendeter Befehle andererseits. Im Rahmen der üblichen Out-of-Order-Verarbeitung dürften Zen-3-Prozessoren demnach genauso häufig falsche Vorhersagen spekulativ ausführen wie ihre Vorgänger, sie müssen aber insgesamt seltener auf Befehle warten und können ihre Recheneinheiten somit häufiger auslasten. Begleitet wird die leistungsfähigere Instruktionsbearbeitung von einem verbesserten L1I-Prefetching - schließlich ist der verbesserte L3-Cache immer noch viel zu träge, um direkt Decoder bedienen zu können.
Zen-3-Architektur: Die verstärkten Ausführungseinheiten
Die Daten sind im Kern, die x86-Instruktionen sind in Macro-Ops übersetzt und diese dem Scheduler übergeben - aber (mehr) gerechnet wurde immer noch nicht. Die eigentliche Datenverarbeitung folgt erst im nächsten Schritt, den AMD traditionell in einen klassischen Ganzzahl-Teil und einen Co-Prozessor für Floating-Point sowie SIMD-INT-Operationen aufteilt. In ersterem finden sich bei Zen 3, wie bei Zen 2, vier ALUs, in letzterem je zwei Multiplizier- und zwei Addier-Pipelines. Kombiniert mit dem näherungsweisen gleichbleibenden Takt kann Zen 3 in der Spitze also genauso viele Daten bearbeiten, wie Zen 2. Damit der ganze Prozessor dennoch schneller wird, hat AMD bei den ergänzenden Pipelines für Verwaltungsaufgaben aufgestockt: Neben AGUs für speicherbezogene Befehle steht den Integer-ALUs jetzt auch eine spezialisierte BR-Pipeline zur Verarbeitung von Sprungbefehlen zur Seite; die erste ALU muss nur noch bei hohem Bedarf aushelfen. Zusätzlich können pro Takt zwei Store-Befehle parallel bearbeitet werden. Die Floating-Point-Mul- und -Add-Einheiten sind analog um zwei Spezialpipelines für Store-Befehle und Register-Moves ergänzt worden. Statt 7 + 4 können Ryzen-5000-Kerne also 10 + 6 Befehle in ihren Pipelines bearbeiten und dank dieser Verstärkung mit der gleichen Anzahl an Haupt-Recheneinheiten mehr Nutzarbeit leisten. Zusätzlich wurde die Bearbeitungszeit für kombinierte Multiplikations- und Akkumulations-Befehle (FMAC) um 20 Prozent verkürzt, was zwar den theoretischen Durchsatz der Pipeline nicht steigert, aber die Zahl der Leerläufe bei aufeinander aufbauenden Berechnungen reduziert. Umgekehrt hält Zen 3 Out-Of-Order-Befehle auch über größere Zeitfenster "in flight" und kann so Abhängigkeiten leichter ausweichen.
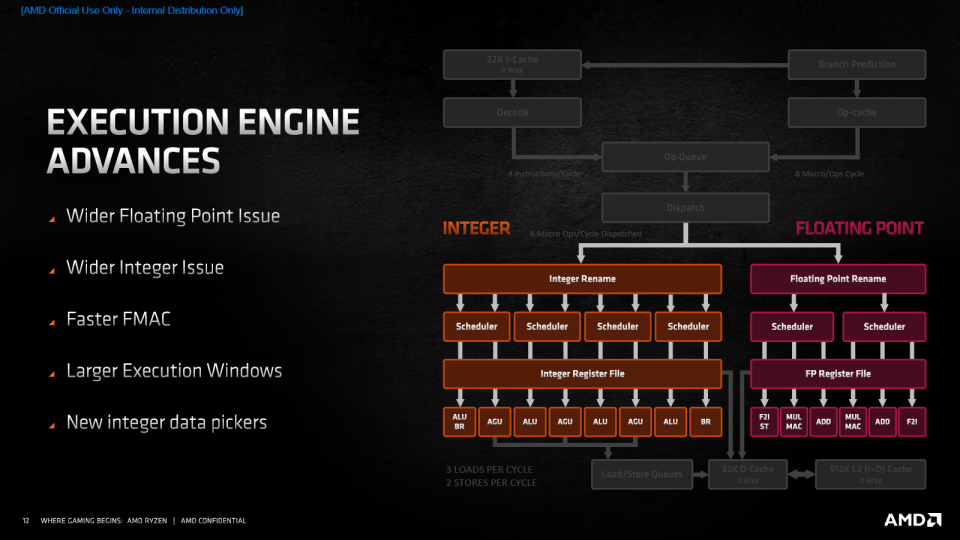 Quelle: AMD
Aus 7 + 4 Ports werden 8 + 6, die 10 + 6 Macro-Ops pro Takt abarbeiten können: Im Aufbau von Zen 3 betreibt AMD viel Fein-Tuning, dass die mit Zen 2 gesammelten Erfahrungen zu tatsächlichen Programm-Anforderungen widerspiegelt.
Quelle: AMD
Aus 7 + 4 Ports werden 8 + 6, die 10 + 6 Macro-Ops pro Takt abarbeiten können: Im Aufbau von Zen 3 betreibt AMD viel Fein-Tuning, dass die mit Zen 2 gesammelten Erfahrungen zu tatsächlichen Programm-Anforderungen widerspiegelt.
Zen-3-Architektur: Das überarbeitete Back-End
Die gleiche Philosophie der Leerlaufvermeidung finden wir in der letzten Pipeline-Stufe. Bereits bei Zen 2 konnten die Load-/Store-Einheiten zwei Lade- und einen Schreibvorgang pro Taktzyklus durchführen, je nachdem ob die Ergebnisse der Berechnungen neue Werte liefern oder aber die Basis für folgende Schritte ermittelt haben. Bei Zen 3 sind alternativ aber auch drei Loads oder ein Load und zwei Stores möglich, je nach Bedarf. Analog zum vergrößerten zeitlichen Befehlsfenster der Ausführungszeiten wurde auch der Schreibpuffer um 50 Prozent vergrößert, sodass am hinteren Ende der Pipeline kein Flaschenhals droht, und die Store-to-Load-Vorhersage-Latenz verbessert. STL-Forwarding verringert den Bedarf an Speichertransferrate zwischen CPU-Registern und Caches allgemein, in dem Ergebnisse gar nicht erst in den Cache ausgelagert werden, wenn sie ohnehin gleich wieder benötigt werden (könnten).
Zen-3-Architektur: Fazit
Quelle: AMD
Im Norden nichts Neues: Den IOD, der weitestgehend einer klassischen Northbridge entspricht, übernimmt Vermeer von Matisse. Aber die innere Organisation der CCD ist neu.
Wie gut AMDs Ryzen-5000-Prozessoren tatsächlich sind, sieht man natürlich am besten in den PCGH-Benchmarks. Deren Ergebnisse passen aber gut zu dem, was die technischen Veränderungen erwarten lassen: AMD hat den Umfang der Rechenressourcen soweit es ging unverändert gelassen, was sich positiv auf die Herstellungskosten auswirken dürfte, aber den Leistungsgewinn in Zen-2-freundlichen Szenarien gering hält, in denen es bislang keine Auslastungsprobleme gab. Dank zahlreicher Optimierungen in der Verwaltung jedes einzelnen CCD-Teils ist Zen 3 aber weitaus flexibler und jetzt nicht mehr auf gut parallelisierbare Aufgaben beschränkt, um seine wahre Stärke zu zeigen. Neue Rekorde in synthetischen Single-Thread-Benchmarks sind dabei eher kosmetisches Beiwerk - die Möglichkeit, 32 MiB Cache auf einen Cinebench-Thread zu konzentrieren, nützt im Alltag wenig, denn bereits mit zwei bis vier Threads kam auch bei Zen 2 der gesamte Zwischenspeicher zum Einsatz. Aus Spielersicht kaum zu überschätzen sind dagegen die beschleunigte Kommunikation zwischen den Kernen sowie die verkürzten Latenzen innerhalb der Pipelines, die viel Leerlauf vermeiden. Als Wermutstropfen bleibt die Kehrseite einer guten Auslastung: Wo bislang effizienter Teillastbetrieb vorherrschte, zeigt Zen 3 auch auf Seiten des Netzteils was es bedeutet, wenn 16 AMD-Kerne ihre brachiale Leistung voll entfalten können.










Aber ab wann und wie stark – wenn Ian mit seinen Diagnosemöglichkeiten nichts einkreisen konnte, habe ich auch keine Chance.
Hast du was davon mitbekommen, welche Netztopologie nun innerhalb eines CCX verwendet wird? Butter-Donut?
Ringbus?
Anandtech dazu:
Achieving this larger 32MB L3 cache didn’t come without compromises as latencies have gone up by roughly 7 cycles to 46 cycles total. We asked AMD about the topology of the new cache but they wouldn’t comment on it besides stating that it’s still an address-hash based system across the 8 cache slices, with a flat memory latency across the depth of the cache, from the view of a single core.