
FSR 3 in der Praxis
Wie funktioniert AMDs FSR in der Praxis? PCGH macht den Test
In diesem Artikel
AMDs FSR 3 in der Praxis
Was AMD in ihrem (endlich erschienenen) FSR-3-Blog beschreiben, ist im Grunde, dass FSR 3 ab mindestens 60 Fps genutzt werden sollte und die gleichmäßigste Bildausgabe bei zugeschaltetem Vsync zu erwarten ist. Dann allerdings entsteht ein "Sägezahnmuster" bei den Frametimes, da der Monitor eine Art Warteschlange (Anmerkung: Back- und Front-Buffer analog zu Double-Buffer-Vsync) induziert, in der die Bilder vor der Ausgabe auf dem Display "geparkt" werden, bis der Monitor einen Refresh durchlaufen hat und ein neuer Frame angezeigt werden kann. Dies kann die maximale Performance verringern und potenziell Lag induzieren.
Anmerkung: Beachten Sie bei den FSR-3-Benchmarks, dass die Percentil-Werte mit unseren üblichen Mess-Werkzeugen nicht korrekt erfasst werden! Durch das Auslesen vor(!) den Frame-Pacing sind diese nicht mit den DLSS-3.0-Werten vergleichbar. Die Durchschnitts-Fps sind indes korrekt.
Die performanteste und gleichmäßigste Methode, die AMD beschreibt, ist ein hohes Framelimit zu nutzen. Bei hochfrequenten Monitoren auch in Kombination mit Vsync, indem die Bildraten-Begrenzung auf die Hälfte der Display-Frequenz gesetzt wird, bei einem 120-Hz-Display also 60. Mit zugeschalteter Frame Generation werden darauf 60 Bilder voll berechnet (das Framelimit wird also mit "echten" Frames ausgeschöpft), die generierten, interpolierten Frames machen darauf die restlichen 60 Bilder aus.
Bei unseren Testspielen Immortals of Aveum und Forspoken - das jüngst erschienene Lords of the Fallen hat leider bislang keinen Support für FSR 3 erhalten, trotz Ankündigung vor dem Launch - funktionierte FSR 3 bereits gut. Allerdings unterscheiden sich die Ergebnisse etwas, allein schon deshalb, weil Forspoken zwingend ein Framelimit nutzt und Immortals im Grafikmenü abseits Vsync nicht mal eins anbietet. FSR 3 existiert mittlerweile außerdem als Implementierung in die Unreal Engine 5 und kann dort auf einige Features zurückgreifen. Darunter etwa, das User Interface nativ, also ohne Frame Generation, rendern zu lassen, um Anzeigefehler an Elementen der Nutzeroberfläche zu vermeiden. Dieserart Artefakt war besonders anfangs sehr deutlich bei Nvidias DLSS 3.0 zu beobachten. Ob Immortals of Aveum allerdings bereits die in die UE5 eingeflossene FSR-3-Implementierung nutzt oder diese von den Entwicklern spezifisch in das Spiel integriert wurde, können wir nicht eindeutig beantworten. Die User-Interfaces sind allerdings in beiden Beispielen auch mit FSR-3-Bildinterpolation auffallend stabil und sauber.
 Quelle: PC Games Hardware
Forspoken - FSR 3 Aufmacher, 4K native maxed
Quelle: PC Games Hardware
Forspoken - FSR 3 Aufmacher, 4K native maxed
Ja, per Photo-Mode geschossen hat das Bild gewisse Bullshot-Qualitäten - gerade betreffend der mangelnden Bewegung (aufgrund der Time-Stop-Funktion des Screenshot-Modus).
An Filtern, Auflösung, Qualität etc. haben wir allerdings nichts geändert. Die optische Qualität von FSR 3 macht bislang einen erstaunlich guten Eindruck, bedarf allerdings weiterer Prüfung in bestenfalls mehr als nur zwei Test-Titeln.
Mit Nvidia-GPUs wirkt die Bildausgabe bei beiden Titeln etwas unrund - auch wenn in Forspoken ein passendes Framelimit gewählt oder in Immortals Vsync aktiviert wird. In letztem Fall wirkt das Bild allerdings weitgehend geschmeidig. Vereinzelt scheint unser Held bei Fortbewegung allerdings ein wenig aus dem Tritt zu geraten - wieder fühlt es sich ein wenig an, als gäbe es einen winzigkleinen Rubberbanding-Effekt respektive eine hin und wieder unsaubere Bildausgabe. Ohne Vsync wirkt das Bild tendenziell mit einer Geforce etwas unruhiger und unsauberer als ohne, doch ist dieser Umstand aktuell schwierig zu ermessen.
Mit AMD-GPUs funktioniert FSR 3 im Grunde gut. Die Bildausgabe wirkt - bei korrektem Nutzen eines Framelimits - insbesondere in Forspoken sauber. Auch in Immortals of Aveum funktioniert FSR 3 mit Radeon-GPUs gut, auch ohne Bildratenbegrenzung. Das im Radeon-Treiber einstellbare Framelimit ist bei FSR 3 offenbar ohne Funktion (und ist inkompatibel mit den FMF, mehr zu den Fluid Motion Frames folgt in Kürze). Mit Vsync wirkt die Bildausgabe tatsächlich glatter, bei Frameraten über unserer maximalen Display-Frequenz von 144 Hz zeigt sich allerdings wieder das weiter oben von AMD angesprochene "Sägezahnmuster" in den per AMD-Tool ausgelesenen Frametimes.
Die vielfältigen Messprobleme
Sie fragen sich vielleicht, weshalb wir im Text gehäuft Formulierungen wie "es wirkt, als ob" nutzen, von "gefühlter Performance" oder von "Schwierigkeiten zu ermessen" sprechen. Dies hat einen trefflichen Grund, den wir an dieser Stelle nur kurz anschneiden möchten: Unsere bevorzugten Mess-Tools, darunter das famose CapFrameX, aber auch andere Messinstrumente funktionieren mit FSR 3 und AMDs Fluid Motion Frames nicht wie angedacht. Das Problem ist im Grunde, dass unsere Tools die Frametime und jene Zeit messen, welche die Frame Generation für die Erzeugung eines interpolierten Bildes benötigt. Die Tools lesen also die Berechnungs- und Erzeugungszeiten von FSR 3 und FMF aus, NICHT(!) aber, wie die Bilder darauf gepaced an das Display geliefert werden. CapFrameX und Co. messen also die Berechnungszeit aus BEVOR(!) das weiter oben von AMD beschriebene Pacing respektive die Angleichung und Anpassung an die Display-Frequenz stattgefunden hat.
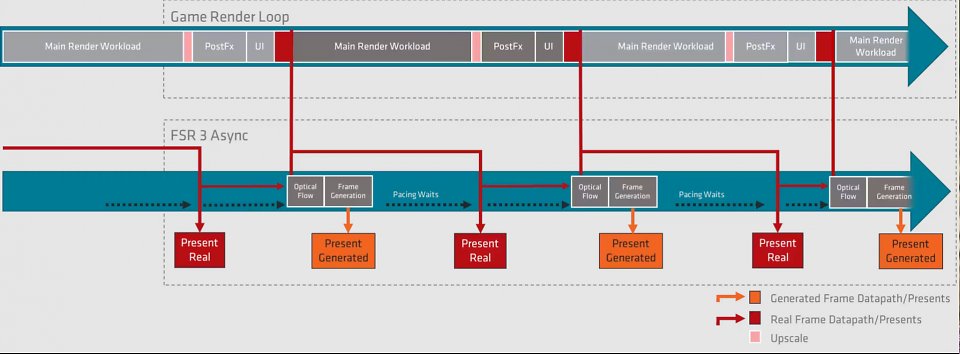 Quelle: AMD
Die Renderpipeline von FSR 3.
Quelle: AMD
Die Renderpipeline von FSR 3.
Wichtig, aber von unseren Mess-Tools teils nicht korrekt erfasst: Nach der Berechnung und Generierung der Frames werden die Bilder gestaffelt respektive aneinander angeglichen oder "gepaced". Während dieser Wartezeit kann dank asnychroner Herangehensweise bereits wieder andere Arbeit übernommen werden, es geht also keine Performance verloren, wenn die generierten und berechneten Frames vor der Ausgabe an das Display zeitlich angeglichen werden.
Unsere aktuellen Schwierigkeiten, was Messungen beim Einsatz von FSR 3 betrifft, wollen wir an dieser Stelle allerdings nicht weiter ausführen und verweisen auf die kommende PCGH 12/2023. Dort gehen wir neben Performance- und Frametime-Messungen sowie erste Latenzuntersuchungen auch auf die Schwierigkeiten bei den Messungen ein. Zumindest zum Teil lässt sich FSR 3 mithilfe des in den Radeon-Treiber integrierten Messwerkzeugen untersuchen. Doch auch hierbei gibt es einige Einschränkungen und natürlich lassen sich mit dem AMD-Performance-Tool im Radeon-Treiber keine Geforce-Grafikkarten untersuchen. Wir planen, uns in näherer Zukunft weiter mit der Thematik zu beschäftigen und im Zweifelsfall auch andere Mess-Tools probeweise zu verwenden; aus Zeitgründen bislang nicht geprüft haben wir unter anderem Tools wie den MSI Afterburner oder OCAT. Von Letzterem existiert eine jüngst erschienene AMD-Variante auf GPUOpen, welche sich laut AMD auch für Messungen mit FSR 3 eignen soll.
Wir wollen stattdessen das zweite, im gewissen Sinne mit FSR 3 verwandte, neue AMD-Feature ansprechen, die Fluid Motion Frames oder (A)FMF. Offiziell erscheinen sollen die via Radeon Software zuschaltbaren Fluid Motion Frames erst Anfang des Jahres 2024, doch hat der Grafikkarten-Hersteller bereits mehrere Preview-Treiber veröffentlicht, mit denen sich das Feature schon heute antesten lässt. Werfen wir also im Rahmen der AMD-Frame-Generation nach FSR 3 nun einen Blick auf die spannende Treiber-Bildinterpolation, die sie im Radeon-Treiber zuschalten und somit in einer Vielzahl Spiele nutzen können.









[Ins Forum, um diesen Inhalt zu sehen]
Ich mag dieses Ausgewaschene nicht, ich steh auf scharfe Texturen und wenn diese Treppchen bilden von mir aus immer noch besser als ein Bild durch eine unscharfe Brille zu betrachten (nichts anderes ist AA, FSR und DLSS)
und bei dgpus…. Was spricht gegen diese Option . Man hat heute auch 120-360hz Monitore, ist doch schön wenn man auch mit den Fps in die Bereich kommt.
Je besser dlss und fsr werden desto mehr merke ich wie natives bild überschätzt wird. Mal abgesehen davon dass dich sowieso nichts am Spiel echt ist. Es ist sowieso alles künstlich generiert.
Wieviel Prozent der Hardware einer modernen Karte sind spezielle KI-Cluster? Wenn die restlichen Komponenten also nicht mehr so wichtig werden, sollte die Hardware, also die nächsten physischen Karten, nicht mehr groß teurer werden. Da die Preise aber heftig gestiegen sind, für einen geringen Teil an KI, steht das für viele nicht mehr im Verhältnis zueinander. Also Preis und Hardware. Jetzt bleibt die Rasterperformance, also der grundsätzliche Rechendurchsatz aber die Grundlage für die KI-Ausgabeleistung. Sprich, wenn da zehn mal mehr gehen würde, dann hätte die darauf aufbauende KI eben auch viel mehr Möglichkeiten und das Ergebnis wäre größer.
Deshalb sollte die Rasterperformance immer weiter im Fokus stehen.
Ist doch auch klar. Aktuelle Spiele laufen nativ als Diashow. Stellt man DLSS/FSR ein, wird die Auflösung reduziert und mehr Bilder berechnet. Diese sähen grottig aus, würde die KI das Bild nicht nachberechnen/aufbereiten. Kommen wir so beispielsweise erst von 15 auf 60 fps, würde bei mehr Rasterperformance eben auch das Gesamtergebnis um den gleichen Faktor steigen. Im Beispiel x10, würden wir also von 150 auf 600fps kommen. Einfach nur mehr KI bringt aktuell nicht viel, wenn die Datenausgangslage (Raster) nicht mit steigt.
Viele haben sich beispielsweise von MCM versprochen dass diese Grundleistung wieder signifikant gesteigert wird. Warum nicht wieder mehrere GPUs auf einer Platine, oder beidseitig bestückt, oder wie zu Zeiten der 7950GX2 gar mehrere Platinen miteinander verbinden und die KI nutzen um die Probleme mit der Bildsynchronisierung von früher in den Griff zu bekommen?
Meiner ganz persönlichen Meinung nach, entwickelt sich die Nutzung von KI aktuell für uns enduser zu einer uns melkenden cashcow, ohne dass klassische Probleme angegangen, oder gar beseitigt werden die eine einfache Leistungssteigerung ermöglichen würden. Ja klar, aktuell steigert man hauptsächlich den ki Part, aber das eben zu Preisen die eine Verdoppelung, oder gar Vervierfachung der Hardware früher mitbrachten. Irgendwann kommt aber wieder der Punkt wo man die Hardware deutlich erweitern muss und dann haben wir uns an Preise gewöhnt die uns so schon nicht schmecken.
Man darf halt nicht vergessen, dass die Entwicklung eine KI echt teuer ist, aber wenn sie dann einmal steht und so wie hier, sich selbst trainiert und erweitert, sie eben kein Brot mehr frisst. Aktuell feiert man Kyi dafür, sich bessere und effizientere Chipdesigns auszudenken und auch hier spart man also fortwährend Kosten. Warum bitte wird diese Ersparnis also nicht durch krasse Leistungssteigerung zum gleichen Preis, oder durch gleiche Leistung zu günstigeren Preisen nicht bei uns umgesetzt?
Die Antwort ist klar.
Deshalb ist für uns Kunden die grundsätzliche Rechenleistung immer bessere/wichtiger als die der KI. Letztere ist vorrangig ein Werkzeug uns mit möglichst wenig Einsatz weiter und stärker zu schröpfen, leider.
Ich kenne kaum eine produzierende branche die so hohe margen hat.....
Sie verlangen schlichtweg mehr geld, weil sie gemerkt haben, dass sie es sich leisten können, weil wir dummen trottel ja trotzdem zu langen.
Dass die rasterisierung so langsam am ende ist hat übrigens auch nichts damit zu tun, dass KI einfach cooler ist. Man erreicht einfach so langsam das physikalische limit und muss daher zwangsläufig neue bessere technologien finden.... Die Transistoren sieht man doch heutzutage nur noch unter dem Mikroskop... Wie klein möchtest du es noch werden lassen?
[Ins Forum, um diesen Inhalt zu sehen]
Man darf also gespannt sein wie sich das entwickelt und in wieweit AMD hier noch verbessern kann. Optical Flow is sicher nicht ideal und Motionvectors sind immer besser, aber das Ende der Entwicklung bei optical flow Ansätzen wie Treiber AFMF ist natürlich noch nicht erreicht.
Ich hab mir heute mal diverse Researchpaper von AMD angeschaut und von GPT4 erklären lassen. Sehr interessant. Grade die Verbesserungen bei Raytracing und Denoising. Man hört ja immer nur von nvidia darüber und grade der Channel auf YouTube "TwoMinutePaper" scheint mir total nvidia biased zu sein..
Dabei hat AMD jede Menge interessante Research zu Denoising, Raytracing, Pathtracing und "Rayreconstruction" ähnlichen Ansätzen.
[Ins Forum, um diesen Inhalt zu sehen]
"Real-Time Rendering of Glossy Reflections Using Ray Tracing and Two-Level Radiance Caching" z.B.
[Ins Forum, um diesen Inhalt zu sehen]
Oder "Fused BVH to Ray Trace Level of Detail Meshes"
[Ins Forum, um diesen Inhalt zu sehen]
Die haben jede Menge Research da.