AMD Zen 1 bis 5: Speicheranalyse verrät spannende Details zu den Latenzen

Chips and Cheese hat die CPU-Architekturen Zen 2, Zen 4 und Zen 5 mit Blick auf ihre Speicherhierarchie und die daraus resultierenden Latenzen untersucht. Das bringt einige spannende Erkenntnisse zutage.
Für die Performance von Prozessoren ist nicht nur die Anzahl und Gestaltung der Rechenwerke entscheidend, sondern auch der Datentransport. Die Rechenkerne müssen kontinuierlich mit neuen Informationen versorgt werden. Hohe Latenzen können die Performance dabei deutlich reduzieren, da die Rechenwerke in dieser Zeit brach liegen. Alle modernen Prozessoren verfügen deshalb über mehrere Cache-Ebenen, die die Latenzen im Rahmen halten sollen. Gleichzeitig zeigen AMDs X3D-Chips, dass allein ein größerer Cache in manchen Anwendungen für deutlich mehr Leistung sorgen kann - und Intel sieht in den hohen Speicherlatenzen eine mögliche Ursache für die schwache Gaming-Performance von Arrow Lake.
Zen 4 hat ein Problem
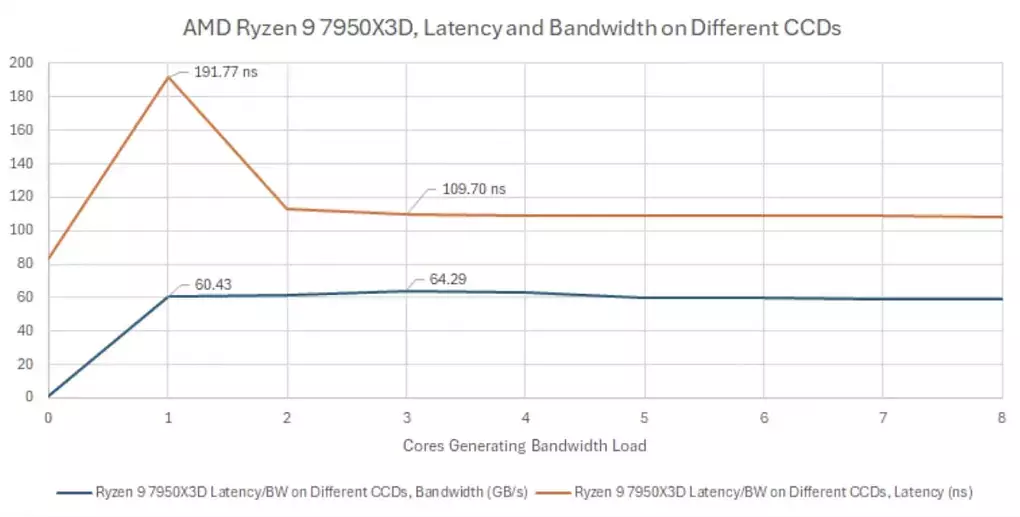
Dass die Latenz beim Anfordern von Daten in modernen Prozessoren keineswegs ein einfaches Thema ist, zeigt dabei aktuell eine Analyse von Chips and Cheese. Dort wurden mehrere Zen-Architekturen von AMD mit Blick auf das Speichersystem analysiert und so einige interessante Auffälligkeiten aufgedeckt. Ein Ryzen 9 7950X3D mit Zen-4-Kernen erreicht innerhalb eines CCD demnach eine minimale DRAM-Latenz von 83 ns, wenn nur ein Kern Daten anfragt. Mit zunehmender Kernzahl steigt diese Latenz hingegen deutlich auf bis zu 415 ns an, wenn fünf Kerne eine hohe Bandbreite anfordern. Grundsätzlich ist das nicht ungewöhnlich, da durch die vielen Speicheranfragen die Cache-Hierarchie mit Anfragen geflutet wird und latenzkritische Aufgaben sich somit einreihen müssen. Der Anstieg auf das knapp Fünffache ist aber auffällig groß und spricht für einen deutlichen Flaschenhals.
 Quelle: Chips and Cheese
Fragt ein Kern hohe Datenraten auf dem anderen CCD an, zeigt sich bei Zen 4 eine überraschende Latenzspitze
Tritt eine hohe Bandbreite hingegen auf dem anderen CCD auf, hat das laut Chips and Cheese hingegen einen deutlich geringeren Einfluss auf die Latenz. Zen 4 pendelt sich dann im Bereich um 110 ns ein - mit einer Ausnahme. Denn mit einem aktiven, Bandbreite-anfragenden Thread liegt die Latenz im anderen CCD bei rund 192 ns. Chips and Cheese vermutet hierbei, dass AMD mit mehreren Threads womöglich die Cache-Kommunikation anpasst und für weitere Threads Plätze in den Cache-Warteschlangen reserviert. Sicher ist das ohne tiefere Einblicke allerdings nicht.
Quelle: Chips and Cheese
Fragt ein Kern hohe Datenraten auf dem anderen CCD an, zeigt sich bei Zen 4 eine überraschende Latenzspitze
Tritt eine hohe Bandbreite hingegen auf dem anderen CCD auf, hat das laut Chips and Cheese hingegen einen deutlich geringeren Einfluss auf die Latenz. Zen 4 pendelt sich dann im Bereich um 110 ns ein - mit einer Ausnahme. Denn mit einem aktiven, Bandbreite-anfragenden Thread liegt die Latenz im anderen CCD bei rund 192 ns. Chips and Cheese vermutet hierbei, dass AMD mit mehreren Threads womöglich die Cache-Kommunikation anpasst und für weitere Threads Plätze in den Cache-Warteschlangen reserviert. Sicher ist das ohne tiefere Einblicke allerdings nicht.
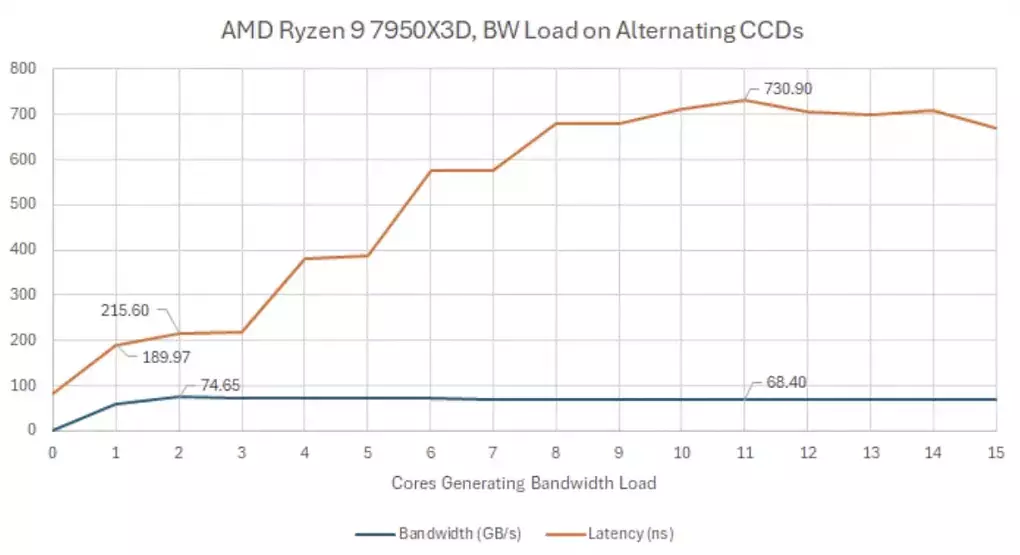
Dafür lässt das Ergebnis aber auf die ideale Arbeitsweise für Scheduler schließen: Threads mit hoher Bandbreite und Threads, die niedrige Latenzen erfordern, sollten bei Zen 4 idealerweise auf unterschiedlichen CCDs ausgeführt werden. Dringend vermeiden sollte man hingegen eine abwechselnde Ausführung von bandbreitenintensiven Aufgaben - dann steigt die Latenz im Extremfall sogar auf 731 ns.
 Quelle: Chips and Cheese
Laufen auf beiden CCDs Threads mit hohem Datenbedarf, steigt die Latenz bei Zen 4 drastisch an.
Bei Zen 5 sind derartige Probleme hingegen weniger kritisch. Auf einem CCD erreicht die Speicherlatenz im Test von Chips and Cheese einen Höhepunkt bei drei Kernen, der aber nur bei 152 ns liegt. Trennt man die Threads wieder in zwei Gruppen, erreicht Zen 5 sogar nur eine maximale Latenz von 86 ns - zudem ist die bei Zen 4 beobachtete, auffällige Latenzspitze nicht mehr anzutreffen. Und auch bei datenhungrigen Threads auf beiden Chiplets sind es nur noch 128 ns.
Quelle: Chips and Cheese
Laufen auf beiden CCDs Threads mit hohem Datenbedarf, steigt die Latenz bei Zen 4 drastisch an.
Bei Zen 5 sind derartige Probleme hingegen weniger kritisch. Auf einem CCD erreicht die Speicherlatenz im Test von Chips and Cheese einen Höhepunkt bei drei Kernen, der aber nur bei 152 ns liegt. Trennt man die Threads wieder in zwei Gruppen, erreicht Zen 5 sogar nur eine maximale Latenz von 86 ns - zudem ist die bei Zen 4 beobachtete, auffällige Latenzspitze nicht mehr anzutreffen. Und auch bei datenhungrigen Threads auf beiden Chiplets sind es nur noch 128 ns.
AMD hat hier mit der aktuellen Architektur also eine deutliche Verbesserung erreicht. Zen 4 scheint hier dabei besondere Schwierigkeiten gehabt zu haben, denn selbst bei der älteren Zen-2-Architektur konnte Chips and Cheese keine derartigen Latenzspitzen erzeugen. Als Ursache wird hier spekuliert, dass die alten Kerne schlicht keine so hohe Bandbreite anfordern können, dass es für das Speichersystem zum Problem wird.
Ebenso spannend: Intel-Analyse bei Mindfactory: 14700K verkauft sich häufiger als Arrow Lake insgesamt
In jedem Fall zeigt die Analyse, dass es zwischen AMDs Zen-Architekturen teils deutliche Unterschiede beim Umgang mit angefragten Daten gibt. Spannend dürfte in Zukunft außerdem eine geplante Analyse von Intel-Architekturen werden - insbesondere, da Arrow Lake hier offenbar Schwierigkeiten hat, denen man so womöglich auf den Grund gehen kann.
Woran könnten die auffälligen Latenzen bei Zen 4 erzeugt werden? Nutzen Sie die Kommentarfunktion und teilen Sie uns Ihre Meinung mit. Zum Kommentieren müssten Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie noch keinen Account haben, könnten Sie über eine Registrierung nachdenken, die viele Vorteile mit sich bringt. Beachten Sie beim Kommentieren aber bitte die gültigen Forenregeln.
Quelle: Chips and Cheese










Der RAM läuft mit DDR5-5600 (2800 MHz), also ignoriert man AMDs Empfehlung der 2:3-Regel für bessere Latenzen auf Kosten der IF-Bandbreite.
Bei DDR5-5600, also 2800 * 2 : 3, wären das 1866 MHz und bei DDR5-5800 1933 MHz.
EDIT
Zusammenfassend kann man sagen, dass die Kerne ab Zen 4 deutlich mehr Bandbreite brauchen um gefüttert zu werden. Dadurch wurden die Warteschlangen, also "Queue", verlängert, was aber unter Umständen die Latenz verlängert. Das passiert auch, weil Zen 4 bandbreitenintensive Aufgaben zu bevorzugen scheint.
Ab Zen 5 wurden wohl trotz gleichem I/O-Die intern pro CCX 2 unabhängige Warteschlangen für Cache-Misses eingeführt statt einer langen.
[Ins Forum, um diesen Inhalt zu sehen]
Laufen auf beiden CCDs Threads mit hohem Datenbedarf, steigt die Latenz bei Zen 4 drastisch an.
Quelle: Chips and Cheese
Bei Zen 5 sind derartige Probleme hingegen weniger kritisch. Auf einem CCD erreicht die Speicherlatenz im Test von Chips and Cheese einen Höhepunkt bei drei Kernen, der aber nur bei 152 ns liegt.
Anbei mal der Link.
Den und nen 3 Zeiler hatte man schreiben sollen. Mehr nicht.
Sehe hier Zen1 und Zen3 nicht. Gerade Zen3 mit den 8core CCX wäre interessant.
Außerdem wird nicht Zen1-5 analysiert, denn die Mobile Chips und APUs werden nicht beleuchtet, gerade die monolithische Bauweise hat bessere Latenzen. Sprich hier geht es nicht um Zen1-5, denn dann wären o.g. Chips dabei.
Die richtige Überschrift wäre eigentlich "Summit Ridge bis Granite Ridge ", denn dann wäre klar, dass es sich nur um die Desktop Varianten handelt und nicht allgemein um die Architektur wir hier suggeriert.
Macht den Quellenartikel aber nicht weniger interessant ^^