AMD Medusa Point: APUs mit bis zu 22 Zen-6-Prozessorkernen

AMDs nächste Generation der Mobilprozessoren, welche als APU basierend auf Zen 6, Zen 6c und RDNA 3.5 aller Voraussicht nach als Ryzen AI 500 ("Medusa Point") an den Start gehen, sollen bis zu 22 Prozessorkerne bieten.
AMDs nächste Generation der Mobilprozessoren, welche als APU basierend auf den Mikroarchitekturen Zen 6 ("Morpheus"), Zen 6c ("Monarch") und RDNA 3.5 ("GFX11.5") aller Voraussicht nach als Ryzen AI 500 ("Medusa Point") an den Start gehen, sollen bis zu 22 Prozessorkerne bieten. Diese neue Plattform, die als "Medusa Point 1" bezeichnet wird, soll einem hybriden Aufbau mit mehreren Chiplets folgen.
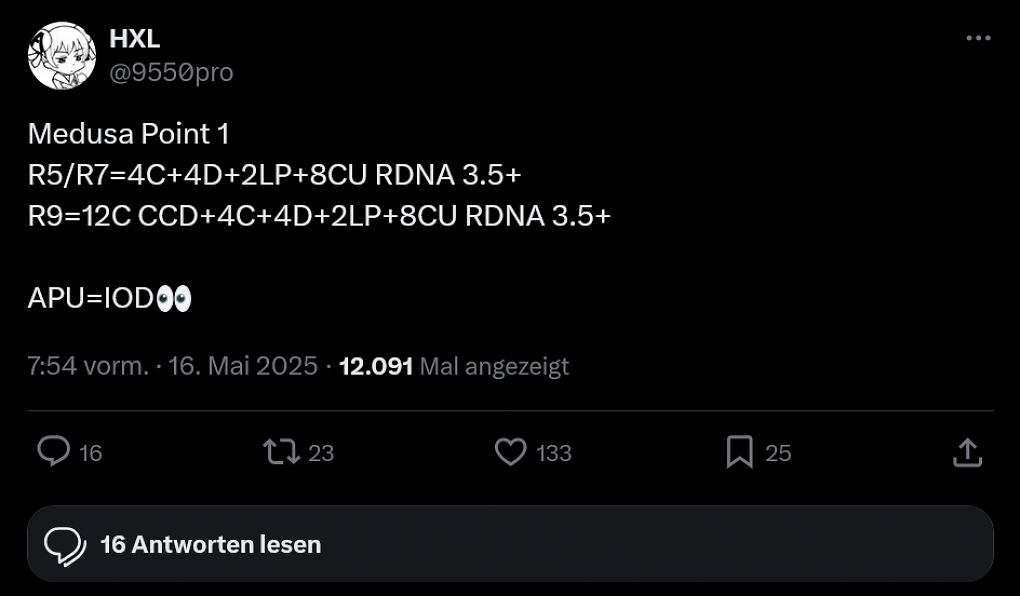
Wie HXL (@9550pro), welcher für seine oftmals zutreffenden Voraussagen bekannt ist, zu berichten weiß, sollen die APUs über bis zu zwei CCDs ("Core Complex Dies") verfügen, welche demnach folgendermaßen aufgebaut sein sollen.
- Ryzen AI 9 HX 500
- CCD 1
- 12 × Zen 6 ("Classic")
- CCD 2
- 4 × Zen 6 ("Classic")
- 4 × Zen 6c ("Dense")
- 2 × Zen 6LP ("Low Power")
- RDNA 3.5+
- CCD 1
- Ryzen AI 7 500 / Ryzen AI 5 500
- CCD 1
- 4 × Zen 6 ("Classic")
- 4 × Zen 6c ("Dense")
- 2 × Zen 6LP ("Low Power")
- RDNA 3.5+
- CCD 1
Neben den bis zu 22 Prozessorkernen und 44 Threads soll die Grafikeinheit auf einer optimierten Variante von RDNA 3.5 basieren, welche demnach als RDNA 3.5+ bezeichnet wird. RDNA 4 soll dedizierten GPUs vorbehalten bleiben.
 Quelle: HXL (@9550pro)
Im kommenden Jahr werden Zen 6 ("Morpheus") und UDNA ("GFX13XX") die nächste Generation der Ryzen-CPU und Radeon-GPUs von AMD antreiben und werfen bereits jetzt ihre Schatten voraus. Die PCGH-Redaktion hat sich diesem bereits im Januar dieses Jahres ausführlich gewidmet und die aktuellen Gerüchte entsprechend zusammengefasst und eingeordnet. Das Jahr 2026 verspricht Spannung.
Quelle: HXL (@9550pro)
Im kommenden Jahr werden Zen 6 ("Morpheus") und UDNA ("GFX13XX") die nächste Generation der Ryzen-CPU und Radeon-GPUs von AMD antreiben und werfen bereits jetzt ihre Schatten voraus. Die PCGH-Redaktion hat sich diesem bereits im Januar dieses Jahres ausführlich gewidmet und die aktuellen Gerüchte entsprechend zusammengefasst und eingeordnet. Das Jahr 2026 verspricht Spannung.
Erwartet werden dabei unter anderem AMD Ryzen X/10000 ("Olympic Ridge") und Ryzen X/10000X3D ("Olympic Ridge-X"), AMD Ryzen AI 500 ("Medusa Point") und Ryzen AI 500 Max ("Medusa Halo") sowie AMD Epyc 9006 ("Venice"), die dann allesamt auf Zen 6 ("Morpheus") und teils auf Zen 6c ("Monarch") setzen.
Ihre Meinung ist gefragt!
Wie stehen Sie zu diesem Thema? Die PCGH-Redaktion freut sich über Ihre fundierte Meinung in den Kommentaren zu dieser Meldung. Um zu kommentieren, müssen Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie bisher noch keinen Account haben, könnten Sie sich hier unverbindlich registrieren. Beachten Sie beim Kommentieren aber bitte die geltenden Forenregeln.
Quelle: @9550pro via VideoCardz









unten: Überhitzt, oben: Überhitzt
[Ins Forum, um diesen Inhalt zu sehen]: Asymmetrische CCD-Größe, CCD-basierte Mittelklasse APUs und Thread-Scheduling mit vier verschiedenen Kernklassen innerhalb einer CPU? Das klingt nach einem verdächtig großen Schritt. Würde mich nicht wundern, wenn da verschiedene Dinge vermischt wurden. 4+4+2 wäre plausibel für einen mobilen Monolithen, 12 volle Kerne gelten als gesetzt für das MCM-CCD.
Compute-on-Compute-Stacking ist halt auch ein heiliger Chiplet-Gral und das nicht ohne Grund: Schließlich sinkt dadurch die Packagefläche und obendrein ist es gut für die Latenzen zwischen den verschalteten CCXes.
Ich sehe nun auch ansonsten noch clevere Möglichkeiten zur Nutzung, die ich bislang noch gar nicht auf dem Schirm hatte:
[Ins Forum, um diesen Inhalt zu sehen]
Auf diese Art und Weise kann der V-Cache also hin und hergeschoben werden.