Grafikkarten im Chiplet-Design: Patent von AMD aufgetaucht

Einem Patent nach plant AMD, einen schon durch Ryzen-3000- und 5000-Prozessoren bekannten Chiplet-Aufbau für Grafikkarten zu verwenden. AMD betont die Komplexität des Unterfanges, glaubt aber auch, dass die unterschiedlichen Einheiten mittels High Bandwidth Crosslinks effizient miteinander kommunizieren.
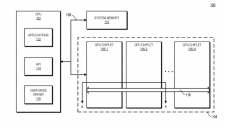
Gerüchte machen schon länger die Runde, nun ist ein einschlägiges Patent beim "United States Patent and Trademark Office" aufgetaucht. AMD beschreibt dort einen modular aufgebauten Grafikprozessor, ähnlich dem Chiplet-Design aktueller Ryzen-Prozessoren. Eine solche GPU würde sich aus mehreren Chiplets zusammensetzen, jeweils mit eigenen Compute Units und Cache. Allerdings übernimmt nur das "Primary Chiplet" die Kommunikation mit dem Hauptprozessor.
High Bandwidth Crosslinks für optimale Parallelisierung
Laut AMD sei ein modulares Design bei GPUs ebenso aufwendig wie kostspielig. Außerdem arbeite es wenig effizient, weil sich Last und Speicherinhalte nicht gut parallelisieren lassen. Zumindest nach derzeitigem Stand der Technik. Richten sollen es Treiberoptimierungen und das "Primary Chiplet", vor allem aber sogenannte High Bandwidth Crosslinks. Dahinter steckt eine passive Schnittstelle, die alle L3-Caches miteinander verbindet. Jedes Chiplet soll dadurch auf den Cache und die VRAM-Anbindung der anderen zugreifen können.
Ebenfalls interessant: Intel-CPUs: Exzessive Nutzung von Chiplets geplant, Start mit 7-nm-Fertigung
Offen bleibt, ob diese Bauweise auch bei Gaming-Grafikkarten Einzug hält oder (zunächst) nur bei profesionellen Lösungen, etwa einem CDNA-Nachfolger, wie zuletzt gemunkelt wurde. Außerhalb des Patents haben sich die Amerikaner jedenfalls noch nicht zu einer Chiplet-GPU geäußert. Falls es entsprechende Gaming-Grafikkarten geben sollte, was alles andere als gesetzt ist, könnte das frühestens bei RDNA 3 der Fall sein. Diese Architektur erscheint aktuellen Roadmaps nach im Jahr 2022.
Quelle: freepatentsonline
 . Jede Partie endet nämlich weit bevor ich aufhören würde, weil der 3600 nur noch 1-2 FPS liefert.
. Jede Partie endet nämlich weit bevor ich aufhören würde, weil der 3600 nur noch 1-2 FPS liefert.







Middleware im Jahr 2020 bedeutet, dass man Unreal Engine mit allen erdenklichen Plugins und Texturpaketen lizenziert. Middleware der Zukunft ist, dass man z.B. eine Version der Alpha Engine von Google lizenziert, die all die Dinge übernimmt, die jetzt eine CPU mit 100W auffressen. Google, Nvidia, Microsoft, Facebook, die würden da gerne alle die Player sein, die so eine Middleware vertreibt. Ki, World State Simulation, Bildschirmphysik, sind alles Aufgaben die in Zukunft von der CPU nicht mehr gemacht werden. Tensor Cores, KI Cores, nennt es wie ihr wollt, spezialisierte Kerne die man mit auf die GPU oder das Chiplet packt und mit CPU sehr wenig zu tun haben.
Es ist ja schön, wenn du glaubst bei zukünftigen Spielen wird das anders sein. Aber erstens glaubst nur du das und zweitens spiele ich jetzt und beende jetzt meine Partien vorzeitig.
Übrigens würde auch ein 10700k oder eine HEDT Maschine das Problem nur etwas hinauszögern. 500k Einwohner in Anno oder C:S sind auch da utopisch, aber ich würde auch in hunderten Stunden Millionenstädte bauen, wenn es den liefe.
Und all die tolle Middleware wird eben genau für die sein, die du nennst: die Big Player. Nun ist ein Großteil meiner Spiele aber nicht AAA, Paradox bspw. wird so schnell keine fremde Engine bekommen, die tut was in deren Spielen nötig ist. Warum auch? Nur für einen Entwickler wird die Unreal Engine oder ähnliches nicht 10 mal komplexere Berechnungen können und 100 mal mehr Modifikationen enthalten. Genug Indie aentwickler bedienen eine spezifische Nische mit ihrer eigenen Engine. Selbst wenn die mal alle von einer grossen, vereinten SuperEngine ersetzt werden können (GreatUnifiedEngine xD), ist es auf jeden Fall noch Zukunftsmusik und nichtmal nahe.
Ich jedenfalls spiele Heute und rede über die Zustände Heute. Unter Umständen auch über gestern und die nähere Zukunft, aber was du nennst steht in meinen Spielen jedenfalls nicht gerade vor der Tür.
Als alter Pessimist glaube ich es nur nicht.
Dafür wurden schon zuviele Patente auf triviale Ideen angemeldet, die sich nicht oder erst Jahre später umsetzen ließen. Was dann teilweise in Patemttrolling endete, wenn nicht der anmelde Nichtskönner, sondern jemand anderem (ohne Wissen über das Patent) die Umsetzung gelang. Leider führt das auch dazu, dass Firmen wie AMD, die nun nicht gerade als Patenttroll bekannt sind, dazu motiviert werden, jeden Fliegenschiss selbst anzumelden nur um sicherzugehen, dass das nicht jemand anders macht und später die Entwicklung behindert.
Keine Ahnung, wer so etwas als erster gebaut hat, aber unter den x86-Nachzüglern fand man es erstmals bei Dual-Pentium-Pro- beziehungsweise, wenn du auf größere Zahlen bestehst, Quad-Xeon-Slot-2-Systemen. Damals hieß das Interface noch "FSB" und die Recheneinheiten trugen ein "C" statt einem "G" vor dem PU und niemand hatte "Chiplet" in eine Ecke gekritzelt. Aber auf die Idee, dass es "schnell" und "machbar" sein sollte, war man bereits gekommen. Und spätestens mit der Voodoo 5 hat jemand die Idee auch schon mal auf einem gemeinsamen Substrat, ohne zentralen I/O-Chip und für 3D-Rendering umgesetzt. Das sind alles antike Ideen. Genauso Punkt-zu-Punkt Interfaces für die Verbindung gleichberechtigter Chips (x86-Markt seit dem ersten Multi-CPU-Opteron, bei IBM oder Cray afaik schon vorher) oder Si-Interposern für zusammenarbeitende Chip-Cluster (z.B. bei Xilinx schon 2011).
Spannend wäre: Wie baut man denn jetzt so einen Interconnect, der so schnell und so latenzarm ist, wie das heutige Rendering-Engines erfordern und zugleich auch noch energieeffizient und so günstig, dass ein Netto-Vorteil gegenüber einer größeren GPU bleibt? Das versucht man seit mindestens 15 Jahren und bislang ist man jedes mal gescheitert. Aber dazu steht im Patent nichts. Erinnert mich an Star-Trek-Autoren: "Wie funktioniert der Heisenbergkompensator?" "Danke der Nachfrage, er funktioniert gut."
Disclaimer: Letzterer Satz soll AMD nicht unterstellen, hier etwas vorzutäuschen, was sie gar nicht bauen können. Er soll nur unterstreichen, dass sie bislang nirgendwo verraten, wie sie die denn den heiligen Gral gefunden haben. Aber das wäre das einzig spannende, denn danach Suchende gibt und gab es zu genüge.