Intel Xeon Phi: Folien zu Knights Landing aufgetaucht - auch als Standalone-CPU mit 72 Silvermont-Kernen
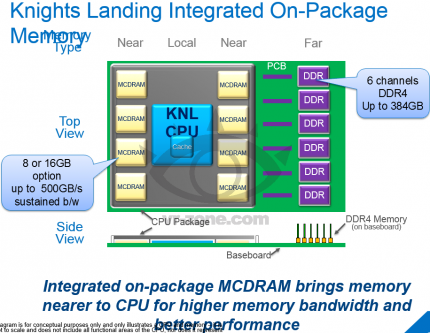
Auf VR-Zone sind einige Folien mit den Spezifikationen zu Intels kommender Xeon-Phi-Ausbaustufe mit Codenamen Knights Landing geleakt, dessen Veröffentlichung als Co- sowie Standalone-Variante 2015 anstehen soll. Pro CPU werden 72 Kerne auf Silvermont-Basis sowie sechs DDR4-Channel mit bis zu 384 GiByte Kapazität vereint. Zusätzlich sind bis zu 16 GiByte MCDRAM verbaut, der mit 500 GB/s arbeitet. Als Double-Precision-Leistung werden pro Prozessor 3 TFLOPs angegeben.
Bisher gab es mehr Spekulationen denn Fakten zu Intels neuen Xeon-Phi-Ausbaustufe Knights Landing, was sich mit einem umfassenden - authentisch wirkenden - Leak auf VR-Zone zu ändern scheint. Dabei werden die bisherigen Annahmen bestätigt, dass die Prozessoren für Supercomputer auf der Silvermont-Mikroarchitektur basieren werden, welche aktuell bei den Atom-Pendants zum Einsatz kommt und auf Effizienz optimiert ist. Bis zu 72 solcher Rechenherzen werkeln pro CPU, wobei der Speichercontroller sechs DDR4-Channel mit 1.200 MHz (DDR4-2400) verwalten kann - insgesamt sind so bis zu 384 GiByte Arbeitsspeicher möglich. Um die langsamere Bandbreite von DDR4 gegenüber dem bisherigen GDDR5-RAM zu kompensieren, werden zusätzlich 8 respektive 16 GiByte MCDRAM verbaut.
 Quelle: VR-Zone
Letztere soll Übertragungsraten von bis zu 500 GB/s ermöglichen, womit GDDR5 um über 50 Prozent eingeholt wird. Bei der Konfiguration des MCDRAMs soll es drei verschiedene Möglichkeiten geben: Entweder kann der komplette Speicher als Cache für den DDR4-RAM dienen oder als die ersten 8 respektive 16 GiByte des Arbeitsspeichers und somit direkt adressiert werden. Als dritte Variante können die beiden Varianten kombiniert werden, indem 4 GiByte als Cache und die verbleibende Kapazität als adressierbarer MCDRAM zur Verfügung stehen.
Quelle: VR-Zone
Letztere soll Übertragungsraten von bis zu 500 GB/s ermöglichen, womit GDDR5 um über 50 Prozent eingeholt wird. Bei der Konfiguration des MCDRAMs soll es drei verschiedene Möglichkeiten geben: Entweder kann der komplette Speicher als Cache für den DDR4-RAM dienen oder als die ersten 8 respektive 16 GiByte des Arbeitsspeichers und somit direkt adressiert werden. Als dritte Variante können die beiden Varianten kombiniert werden, indem 4 GiByte als Cache und die verbleibende Kapazität als adressierbarer MCDRAM zur Verfügung stehen.
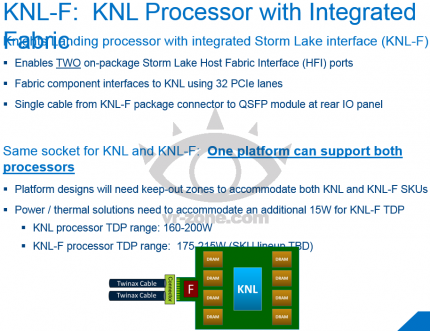
Pro Kern kommen indes zwei 512-bittige Integer-Einheiten sowie vier Threads zum Einsatz, Befehlssätze wie AVX-512 sind somit mit an Bord. Die Single-Precision-Performance wird pro CPU mit 6 TFLOPs angegeben, die doppelte Genauigkeit mit 3 TFLOPs. Das 2-zu-1-Verhältnis braucht sich hierbei nicht vor der Konkurrenz zu verstecken. Die TDP von Knights Landing soll Dank der 14-nm-Fertigung nur noch 200 Watt betragen. Zum Vergleich: Die bisherigen Xeon Phis haben 300 Watt Leistung aufgenommen. Die neue Ausbaustufe wird es erstmals auch als Standalone-Version geben, wobei weiterhin Co-Prozessoren in Form der Erweiterungskarten angeboten werden sollen.
 Quelle: VR-Zone
Über den Storm-Lake-Interconnect mit einer Bandbreite von 100 Gb/s können Letztere außerdem mit einem Knight-Landing-Hauptprozessor verbunden werden. Intel wird die Plattform modular anbieten, sodass sie nach den Präferenzen des jeweiligen Unternehmens aufgebaut werden kann. In einer zweiten Ausbaustufe Knights Landing-F soll noch der Cray-Interconnect-Controller integriert werden, mit dem ein zweiter Channel mit weiteren 100 Gb/s zur Verfügung stehen wird. Dafür werden 32 der 36 vorhandenden PCI-Express-3.0-Lanes benötigt. Dabei soll der Backplane-Switch mit einer optischen Verbindung, beispielsweise Glasfaser, angeschlossen werden.
Quelle: VR-Zone
Über den Storm-Lake-Interconnect mit einer Bandbreite von 100 Gb/s können Letztere außerdem mit einem Knight-Landing-Hauptprozessor verbunden werden. Intel wird die Plattform modular anbieten, sodass sie nach den Präferenzen des jeweiligen Unternehmens aufgebaut werden kann. In einer zweiten Ausbaustufe Knights Landing-F soll noch der Cray-Interconnect-Controller integriert werden, mit dem ein zweiter Channel mit weiteren 100 Gb/s zur Verfügung stehen wird. Dafür werden 32 der 36 vorhandenden PCI-Express-3.0-Lanes benötigt. Dabei soll der Backplane-Switch mit einer optischen Verbindung, beispielsweise Glasfaser, angeschlossen werden.
Quelle: VR-Zone
| Modell | Fertigung | Kerne | Interface | Speicher | TDP | Rechenleistung |
|---|---|---|---|---|---|---|
| Knights Ferry | 45 nm | 32 | 256 Bit | 2 GiByte GDDR5 | 300 Watt | ~ 400 DP-GFLOPs |
| Knights Corner | 22 nm | 62 (64) | 512 Bit | 16 GiByte GDDR5 | 300 Watt | 1.220 DP-GFLOPs |
| Knights Landing | 14 nm | 72 | 512 Bit | 8/16 GiByte MCDRAM + 384 GiByte DDR4 | 200 Watt | ~ 3.000 DP-GFLOPs |
 da gucken AMD und Nvidia leider (aktuell) ein wenig blöd aus der Wäsche
da gucken AMD und Nvidia leider (aktuell) ein wenig blöd aus der Wäsche  aber wer weiß was sich bis 2015 so ändert.
aber wer weiß was sich bis 2015 so ändert.







Würde es mal im Home Bereich so schnell weitergehen.
immerhin 3000 GFlops zu 1220Gflops...
in maximaler aussbaustufe 400Gibyte ram
Zu hohe Anzahl an gemeinsamen Zugriffen killt dich aber eh bei so ner Architektur. Du musst da einfach schon von Grund auf davon ausgehen, dass sowas einfach nicht passiert, und was eh nicht passieren darf, um das muss man sich auch nicht sooo große Gedanken machen bzgl Optimierung.
Ich würde bei jetztigen Präsentationen auch nicht davon ausgehen, dass die Grafiken jedes technische Detail akkurat wiedergeben. Zum jetzigen Zeitpunkt präsentiert Intel nur die Eckdaten, die Grafiken dienen weniger der Wissensvermittlung und mehr der abstrakten Illustration. Ggf. weiß der Erstellende nicht einmal, wie die on-DIE-Interconnects aussehen.
An sich haut das Ding ziemlich genau in die gleiche Kerbe wie der Tilera was den Interconnect anbelangt.
Man handelt soch sogar genau die gleichen Probleme ein mit den geteilten Memory-Pools und den daraus resultierenden Problemen des "geschickten" Prozessmapping aus die Cores, damit man nicht durch das gesamte Netzwerk immer und immer wieder die Daten schleusen muss... Das bricht so einer Architektur schnell das Genick. Man braucht einfach wieder ne hohe Datenlokalität.
Unterm Strich aber wohl dennoch noch immer die beste Lösung, da man so die Wege halbwegs minimieren kann durchs Netzwerk und eben übers Mapping einiges noch retten Kann. Bei Speicher nur auf einer Seite wirds halt doof für die Cores die wieter weg vom Speicher sitzen.
Der interessanteste Punkt ist aber eigentlich der 100Gbit/s Interconnect mit Connector ON PACKAGE! Das seh ich echt Problematisch. Wenn Sie, wovon ich ausgehe, eben den Cray-Interconnect direct mit auf den Chip packen, inkl Connector, dann brauchste eigentlich kein anderes Netzwerk mehr... Eigentlich ist es klar, dass so was kommen musste, aber ich habe ehrlich gesagt nicht erwartet, das es so schnell kommt und vor allem von Intel
Die ganzen Hardwareausrüster wird das wohl Bauchschmerzen machen... Man hat halt praktisch nur noch ein Board von Intel, wo alles drauf ist und fertig. Intel nutzt da massiv ihre Größe aus.