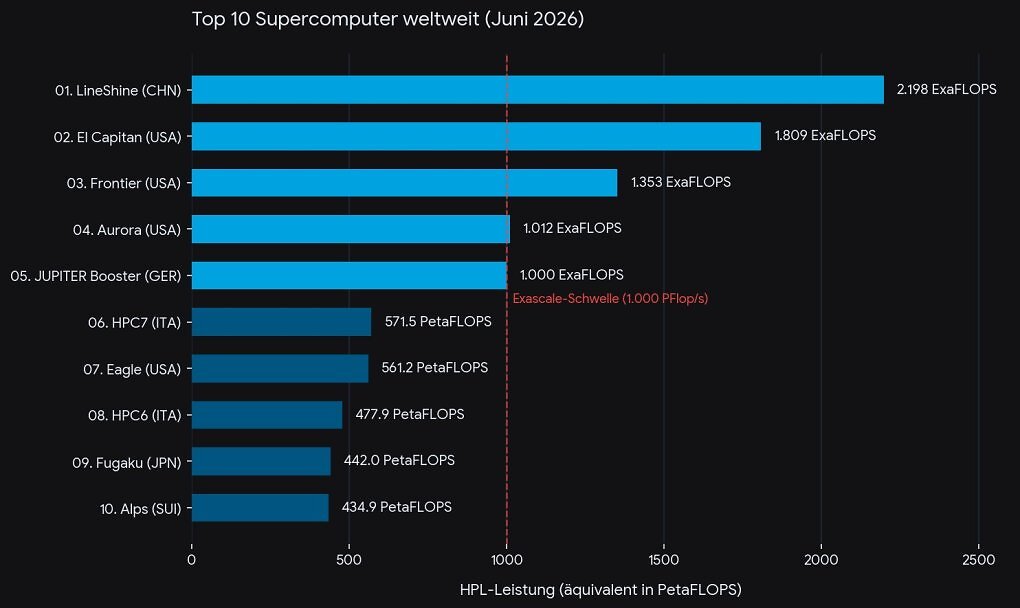
Supercomputer: LineShine aus China ist die neue Nummer 1

Die USA wollten Chinas KI-Aufstieg ausbremsen, doch Peking schlägt zurück: Mit dem Supercomputer LineShine und 2,4 Millionen Prozessorkernen von Huawei knackt das National Supercomputing Center die magische ExaFLOPS-Marke gleich doppelt.
Mit dem Supercomputer Lingsheng (灵晟, auch als "LineShine" bekannt) setzt das National Supercomputing Center in Shenzhen ("NSCC-SZ") jetzt ein nachdrückliches Ausrufezeichen im KI-Wettrüsten zwischen den Vereinigten Staaten von Amerika und der Volksrepublik China. Wie aus Berichten von Top500.org, FAZ und Golem sowie einer offiziellen Bekanntmachung des NSCC-SZ hervorgeht, durchbricht Chinas schnellster Supercomputer die magische "ExaFLOPS-Marke" gleich in doppelter Hinsicht und ist damit jetzt das schnellste System der Welt.
 Quelle: Sven Bauduin
Quelle: Sven Bauduin
Supercomputer erreicht 2 ExaFLOPS ganz ohne GPUs
Ganz ohne GPUs von Nvidia, AMD oder Intel: Ein begleitendes Forschungspapier attestiert Lingsheng alias "LineShine" eine konsistente Leistung von 1,54 ExaFLOPS ("BF16") mit Peaks von 2,1 ExaFLOPS beim Training eines riesigen KI-Modells mit insgesamt 6,3 Milliarden Parametern. Lu Yutong, Direktor des NSCC-SZ, spricht selbstbewusst von "vollständiger Souveränität und Kontrolle".
40.960 ARM-Prozessoren in zwei Ausbaustufen
Das Herzstück von Lingsheng bildet der eigens für HPC- und KI-Workloads entwickelte "LX2-Prozessor", den Jon Peddie Research dem chinesischen Tech-Riesen Huawei zuschreibt. Jede der 40.960 verbauten CPUs setzt auf zwei Compute-Chiplets mit insgesamt 304 ARMv9-Kernen, organisiert in acht Clustern zu je 38 Kernen.
- Über die beiden bekannten Arm-Erweiterungen SVE ("Scalable Vector Extension") und SME ("Scalable Matrix Extension") beschleunigt der Prozessor die Vektor- und Matrix-Operationen in FP64, FP32, BF16, FP16 und INT8, ein einzelner LX2 liefert dabei 60,3 TFLOPS in FP64 und 240 TFLOPS in BF16/FP16.
- Pro Sockel stehen 32 GiB HBM (4 TB/s) plus 256 GiB DDR5 bereit, vernetzt über das hauseigene LingQi-Netzwerk mit 1,6 Tb/s pro Knoten. Der Aufbau erfolgt offiziell in zwei Stufen:
- Auf eine Pilotphase mit 100 Huawei-Kunpeng-Servern und 12.800 Prozessorkernen folgte der Vollausbau mit 47.000 CPUs in 92 Compute-Schränken, 650 Petabyte Storage und 10 TB/s Bandbreite.
- LineShine kommt damit im Vollausbau auf 13.789.440 ARMv9-Prozessorkerne, welche mit einer Taktfrequenz von vergleichsweise niedrigen 1,55 GHz arbeiten.
- Das National Supercomputing Center in Shenzhen ("NSCC-SZ") hat für LineShine einen im High Performance Linpack erhobenen Wert von 2,198 ExaFLOPS (Rmax) vorgelegt und löst damit El Capitan als schnellsten Supercomputer der Welt ab.
Made in China: El Capitan im Visier
Strategisch ist Lingsheng ein Statement: Chips, Speicher, Interconnect, Storage und sogar das Betriebssystem (Anolis OS 8.9) stammen vollständig aus einer heimischen Fertigung. Bereits Ende 2025 bestätigte der stellvertretende NSCC-Direktor Huang Xiaohui eine "Spitzenleistung von 2 ExaFLOPS" - damit rückt das CPU-Monster in Schlagdistanz zum AMD-basierten El Capitan mit 1,74 ExaFLOPS ("Rmax") am Lawrence Livermore National Laboratory. Eine echte Kampfansage Chinas.
Bei der Effizienz hinter westlichen Systemen
Doch der Trumpf hat einen Haken: CPU-only-Systeme sind in aller Regel weniger energieeffizient und liefern eine geringere dichte KI-Rechenleistung als heterogene CPU+GPU-Architekturen - nicht ohne Grund setzen Marktführer wie xAI, OpenAI und Meta weiterhin auf hunderttausende Nvidia-Beschleuniger. Trotzdem zeigt Lingsheng eindrucksvoll, dass Pekings Streben nach digitaler Eigenständigkeit längst nicht mehr nur Theorie, sondern Wirklichkeit ist. Der Supercomputer aus China liest sich wie eine Unabhängigkeitserklärung an die USA und deren Big-Tech-Unternehmen. Für einen Supercomputer ohne GPU-Beschleuniger ist Platz 50 in den Green500 ebenfalls äußerst beachtlich und zeigt, was rein mit ARM-Prozessoren möglich ist.
Was die neue Liste für Jupiter aus Jülich bedeutet
Der JUPITER Booster am Forschungszentrum Jülich rutscht auf Rang fünf, bleibt mit 1.000 ExaFLOPS aber aktuell das einzige Exascale-System Europas im HPL. Das vom EuroHPC Joint Undertaking betriebene System aus Nordrhein-Westfalen verliert durch den Neueinsteiger LineShine sowie das italienische HPC7 zwei Plätze.
In der Energieeffizienz mischt Deutschland weiter vorn mit: Auf der Green500 belegt die GPU-Erweiterung des Systems Levante am Deutschen Klimarechenzentrum mit 69,43 GFLOPS/Watt Rang drei, hinter zwei französischen Anlagen.
Mitmachen und kommentieren
Wie stehen Sie zu diesem Thema? Die PCGH-Redaktion freut sich bereits über Ihre Meinung in den Kommentaren zu dieser Meldung. Sollten Sie hingegen noch keinen Extreme-Account haben, laden wir Sie zu einer Registrierung im Forum ein. Beachten Sie beim Kommentieren aber bitte die Forenregeln. Folgen Sie gerne PCGH bei 🔈 YouTube und 💬 WhatsApp und erhalten Sie Neuigkeiten zu CPUs, Grafikkarten und Gaming direkt in Ihrem Feed.
Quelle: Top500.org via Golem








