
Radeon RX 6800 (XT) im Test: Techniktauchgang
RDNA 2 vs. RDNA 1: In diesem Artikelabschnitt werfen wir einen genauen Blick unter die Haube von RDNA 2 respektive Big Navi.
Auf dieser Seite
Was RDNA brachte ...
AMDs Wechsel von GCN auf RDNA vor bald 1,5 Jahren war ein großer, wichtiger Schritt - vergleichbar mit dem einschneidenden Wechsel von TeraScale (VLIW; 2007) auf GCN (SIMD; 2011). Mit RDNA 2 entwickelt AMD das 2019 gelegte Fundament an entscheidenden Punkten weiter und hievt es somit erfolgreich auf das modernste Tech-Level. In diesem Artikelabschnitt entfernen wir die Haube und schauen in den Motor. Achtung, es wird technisch, wenngleich wir mit vereinfachter Darstellung arbeiten. Die gar nicht so graue Theorie hilft beim Colorieren der anschließenden Benchmarks.
 Quelle: AMD
AMD Radeon RX 6800 und RX 6800 XT im Test: Sind die RTX 3070 und RTX 3080 geschlagen? (36)
Spätestens seit Intels Pentium 4 wissen wir, dass Takt nicht alles ist. Der Fähigkeit eines Prozessors, pro Zyklus möglichst viele Dinge zu erledigen, wird heutzutage eine wesentlich wichtigere Rolle zuteil. Im Pflichtenheft für das Navi-Projekt stand daher der Punkt "Instructions per clock" (IPC; Instruktionen pro Takt) ganz oben. AMD hat mit RDNA bzw. Navi 10 die IPC-Rate der Shader-Einheiten, Compute Units (CU) genannt, deutlich erhöht, sodass mehr Netto vom Brutto übrigbleibt. Das genügte, um in der Mittel- und Oberklasse konkurrenzfähig zu sein, ließ Nvidia jedoch im High-End-Bereich ungestört regieren. Doch der Reihe nach.
Quelle: AMD
AMD Radeon RX 6800 und RX 6800 XT im Test: Sind die RTX 3070 und RTX 3080 geschlagen? (36)
Spätestens seit Intels Pentium 4 wissen wir, dass Takt nicht alles ist. Der Fähigkeit eines Prozessors, pro Zyklus möglichst viele Dinge zu erledigen, wird heutzutage eine wesentlich wichtigere Rolle zuteil. Im Pflichtenheft für das Navi-Projekt stand daher der Punkt "Instructions per clock" (IPC; Instruktionen pro Takt) ganz oben. AMD hat mit RDNA bzw. Navi 10 die IPC-Rate der Shader-Einheiten, Compute Units (CU) genannt, deutlich erhöht, sodass mehr Netto vom Brutto übrigbleibt. Das genügte, um in der Mittel- und Oberklasse konkurrenzfähig zu sein, ließ Nvidia jedoch im High-End-Bereich ungestört regieren. Doch der Reihe nach.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 30
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 30
Der wohl wichtigste Punkt widmet sich den sogenannten "Waves" (AMD-Sprech) respektive "Warps" (Nvidia-Jargon). Aus Sicht eines Grafikchips entspricht eine Wave einem Bündel zugeschickter Rechenaufgaben mit 64 Elementen ("Work Items"). Diese Aufgaben erreichen den Grafikchip über die Programmierschnittstelle (API), etwa DirectX oder Vulkan, und werden von einem Vorarbeiter - dem Scheduler - an eine Gruppe von Rechenwerken weitergereicht. Diese mehrheitlich arithmetisch-logischen Einheiten der GPU, kurz ALUs, kümmern sich um Shader-Kalkulationen wie Multiply & Add (Multiplikation & Addition; kurz MADD), meist im Gleitkommaformat FP32 (Floating Point mit 32 Bit Genauigkeit), beherrschen jedoch auch andere Datenformate wie INT32 (Integer, Ganzzahlen).
Jede Shader-Engine beinhaltet eine gewisse Anzahl Lanes, von AMD "Stream Processor" und von Nvidia "CUDA Core" genannt. Jede Compute Unit, egal ob RDNA 1 oder RDNA 2, beinhaltet 64 dieser Lanes. Was sich zwischen GCN und RDNA unterscheidet, sind die Gruppierung der ALUs und die Granularität der Daten. Anstatt wie GCN alle vier Takte ein Wave64-Instruktionspaket zu bearbeiten, kommt Navi dank seiner doppelt so breiten SIMD32-Units und pro CU doppelt anwesendem Scheduler mit zwei Takten aus. Zwei entsprechende Blöcke stecken in jeder Compute Unit, welche daher seit RDNA als Dual Compute Unit oder Work Group Processor (WGP) bezeichnet wird. Die wichtigste Neuerung bei Navi geht noch einen Schritt weiter und wird standardmäßig genutzt: Der Shader Compiler kann die Daten im Wave32-Format anliefern, wobei Navi hier pro Takt ein Ergebnis ausspuckt. Auf diese Berechnungsweise setzt auch Nvidia (Warp32).
... und was RDNA 2 bringt
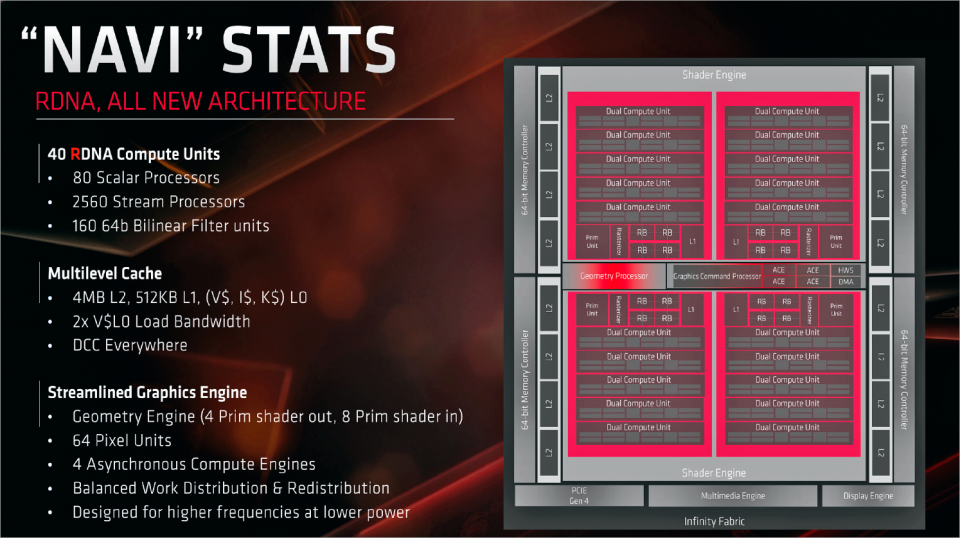
Auf Einheiten-Ebene erfindet RDNA 2 das Rad nicht neu, sondern bringt in erster Linie mehr Quantität und auch etwas mehr Qualität. Sieht man sich die Blockdiagramme von Navi 10 und Navi 21 an, entspricht Letzterer zu weiten Teilen einem verdoppelten Navi 10. Die Shader Engine (SE), die größten Funktionsblöcke innerhalb eines AMD-Grafikchips, sind nun vier- anstatt zweimal vorhanden. Damit einher geht die Verdopplung der Compute Units mit allen darin enthaltenen Rechenwerken: 80 CUs, 5.120 FP32-Shader-ALUs und 320 Textureinheiten sind im "Full Fat"-Vollausbau von Navi 21 vorhanden. Doch nicht alles wurde verdoppelt. Da wäre die bei vielen vorherigen AMD-Generationen stiefmütterlich behandelte Geometrieleistung, deren Pro-Takt-Output nicht angefasst wurde. Hier verlässt sich AMD offenbar rein auf die neue Mesh-Shader-Funktion, welche jedoch eine explizite Implementierung durch Spieleprogrammierer benötigt, um ihre wundersame Wirkung zu entfalten - im Gegensatz zu Vega und dessen Primitive Shaders jedoch mit deutlich besseren Zukunftsaussichten. Außerdem beläuft sich die Anzahl der Asynchronous Compute Engines nach wie vor auf vier, welche nun doppelt so viele Compute Units unter ihren Fittichen haben. Bei der Anzahl der Raster-Endstufen, von AMD Render Backends oder allgemein ROPs genannt, sieht es wieder besser aus. Ihre Anzahl wurde nicht nur auf 128 verdoppelt, sondern auch einige Formate beschleunigt.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 11
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 11
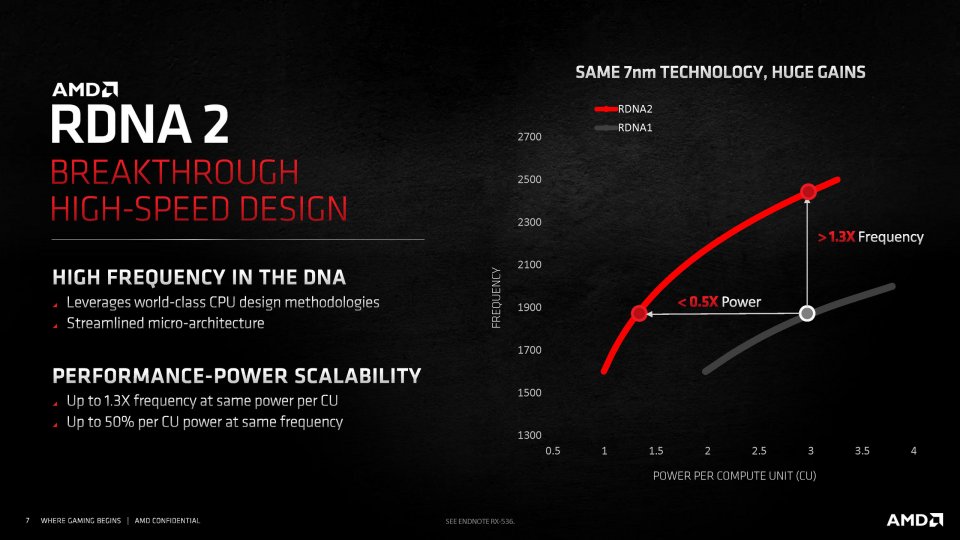
Verdopplungen der Einheiten führen bestenfalls zu verdoppeltem Durchsatz, sofern die Auslastung gewährleistet ist. Was der Leistung immer hilft und eines der Designziele für RDNA 2 war, ist Takt. AMD verkündet nicht ohne Stolz, dass eine RDNA-2-CU pro Watt Navi 21 boostet tatsächlich auf bis zu 2,5 GHz.
entweder um 30 Prozent schneller takten kann, oder bei RDNA-1-Taktraten nur die Hälfte der Energie brauche. Das sind beeindruckende Zahlen angesichts des weitgehend gleichen Fertigungsprozesses, kommen jedoch nicht ohne Opfer. AMD gibt auf PCGH-Nachfrage zu Protokoll, dass die Pipeline an einigen Stellen verlängert wurde, um die hochgesteckten Taktziele zu erreichen. Da ist er wieder, der Pentium 4 - doch keine Sorge, abgesehen davon erinnert RDNA 2 zu keiner Zeit an Netburst. Wundern Sie sich jedenfalls nicht, wenn Sie in den folgenden Benchmarks keine einzige Taktrate unter 2 GHz erblicken - Navi 21 boostet als Radeon RX 6800 XT in unseren Tests tatsächlich auf bis zu 2,5 GHz. Der hohe Takt führt zu rascher Abarbeitung aller Aufgaben und steigert auch die Leistung jener Komponenten, die gegenüber Navi 10 nicht verdoppelt wurden. Zu den in Spielen erreichten Frequenzen später mehr.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 07
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 07
Cache, Cache, Cache!
Die schnellsten Rechenwerke sind nutzlos, wenn sie nicht zeitnah mit Daten gefüttert werden können und daher ständig warten müssen. Hier kommen die rasanten Zwischenspeicher, Caches genannt, zum Zuge. Die meisten Grafikchips, darunter die älteren AMD-GPUs Vega und Polaris, verfügen pro Shader-Cluster über einen 16 KiByte fassenden Level-1-Cache, zusätzlich teilen sich alle Compute Units einen 4 MiByte großen L2-Cache. Hierarchisch betrachtet fungiert der bei diesen Grafikkarten als letztes angeschlossene Grafikspeicher als "off-chip L3-Cache" - die Daten verlassen den Kern, was energie- und zeitaufwendige Anfragen zur Folge hat.
RDNA-Chips verfügen über eine weitere Cache-Stufe dazwischen: Was bei Vega und Polaris der L1-Cache ist, entspricht bei Navi dem "L0". Hier teilen sich stets zwei Compute Units eine Cache-Partition, welche mit doppelter Transferrate angebunden ist. Den anschließenden L1-Cache teilen sich jeweils fünf Dual Compute Units. Diese Zwischenablage dient dazu, die Daten möglichst nah bei den Rechenwerken zu halten, anstatt in den langsameren L2-Cache auszulagern. Letzterer ist seit mehreren AMD-Generationen 4 MiByte groß, Navi 21 bricht nicht mit dieser Tradition (und auch die RTX 3070 verfügt über diese Menge, doch das nur am Rande). Dadurch, dass Navi 21 nun doppelt so viele Shader-ALUs beherbergt wie Navi 10, steht pro Einheit weniger L2-Cache zur Verfügung - die Lösung dieses Problems finden Sie im folgenden Absatz. Unterstützung beim Vorhaben, die Daten schnell intern zu bearbeiten, kommt durch die erneut verbesserte Delta Color Compression (DCC). Diese verlustfreie Kompression funktioniert nun innerhalb der kompletten Grafik-Pipeline und reduziert den Bandbreitenbedarf - nicht aber die Belegung. Bedauerlicherweise ging AMD auf Nachfrage nicht ins Detail, wo sich RDNA 1 und RDNA 2 unterscheiden, offiziell gab es jedoch minimale Verbesserungen, sodass die Kompression nun tatsächlich überall aufrechterhalten wird.
Die wahre Innovation mit "Game Changer"-Potenzial wurde laut AMD vor etwa drei Jahren erdacht: Navi 21 verfügt über einen 128 MiByte großen SRAM mit der Bezeichnung "Infinity Cache", welcher direkt im Kern - zwischen L2-Cache und den DRAM-Controllern - platziert wird. Dieser adaptiert das Wissen aus der Zen-Prozessor-Entwicklung, welche sich bereits seit Jahren mit großen und möglichst dicht gepackten Level-3-Caches auseinandersetzt. Ein Core Complex in Zen 2 (Ryzen 3000) bringt, so AMD, 32 MiByte L3-Cache auf lediglich 27 mm² unter - und Navi 21 folgt diesem Pfad. Zwar verschweigt AMD die Größe des nunmehr 128 MiByte großen SRAM-Bereichs und die genutzten Bibliotheken, milchmädchenhaft hochgerechnet nimmt der Infinity Cache in Navi 21 jedoch 102 mm² ein. Das entspricht, ausgehend von den offiziellen (rund) 520 mm², immerhin fast einem Viertel des gesamten Kerns. AMD hätte dieses Unterfangen kaum gewagt, wenn es sich nicht lohnen würde.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 09
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 09
Egal ob Radeon RX 6900 XT, RX 6800 XT oder RX 6800, sie alle verfügen über die vollen 128 MiByte Infinity Cache. Eine Radeon RX 6900 XT mit ihren vollständig aktiven 80 Compute Units verfügt somit Chip-weit über ~143 MiByte Zwischenspeicher direkt neben den Ausführungseinheiten. Zum Vergleich: Eine Geforce RTX 3090 bringt es auf gerade einmal ~20 MiByte. Die große Datenablage direkt neben den Rechenwerken resultiert in kurzen Signalwegen und somit geringer Latenz. Die Kommunikation erfolgt über das ebenfalls aus Dies resultiert in einer Chip-internen Maximaltransferrate von beinahe 2 TByte/s.
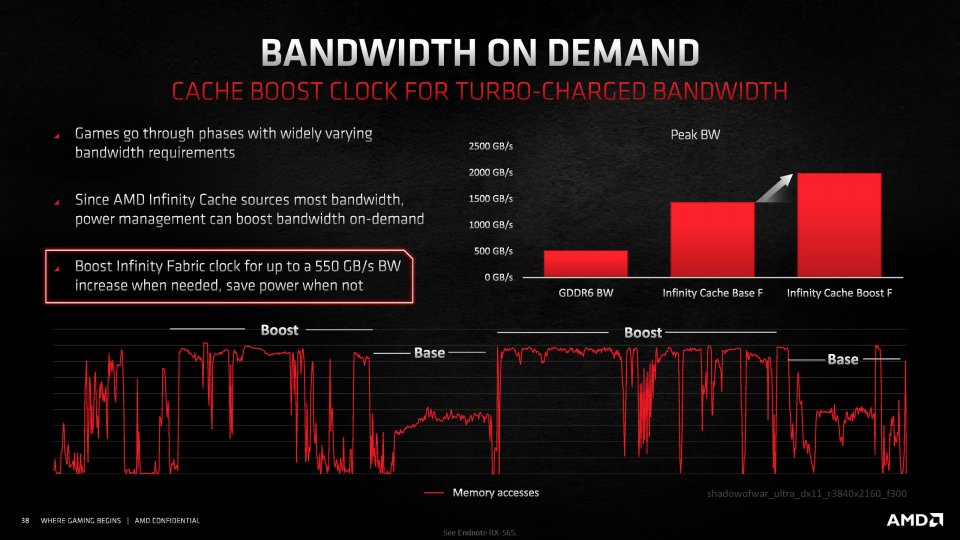
dem CPU-Bereich adaptierte Infinity Fabric (wie schon bei Navi 1x) - in Navi 21 neuerdings mit dynamischer, lastabhängiger Frequenz. Mit anderen Worten: Cache und Datenbahn arbeiten mit einer eigenen, vom Rest des Kerns entkoppelten Taktdomäne (SoC Clock). 16 jeweils 64 Bit breite Interfaces, ergo 1.024 Bit insgesamt, takten in bandbreitenlastigen Szenarien mit maximal 1,94 GHz. Dies resultiert in einer Chip-internen Maximaltransferrate von beinahe 2 TByte/s - viermal so viel wie der am Ende angebundene GDDR6-Grafikspeicher. Da Spiele, so AMD, zur Laufzeit sehr unterschiedliche Anforderungen an die Bandbreite stellen, erfolge die Taktung des Infinity Fabric kontextabhängig. Ist auf dem Datenpfad wenig los, taktet das Gebilde aus energetischen Gründen mit rund 1,4 GHz (-> 1,44 TByte/s), bei vielen Anfragen hingegen mit besagten 1,94 GHz (-> 1,99 TByte/s). Inwiefern der Treiber in das Geschehen eingreifen kann und ob sich der Infinity-/SoC-Takt zwischen den RX-6000-Modellen unterscheidet, ist derzeit unbekannt. Eine andere PCGH-Frage beantwortete AMD klar und deutlich: Diese spezielle Taktdomäne lässt sich nicht durch GPU-Overclocking anheben. Diese Maßnahme sichert ein besseres OC-Potenzial, ohne dass ein Bandbreitenlimit zu befürchten ist.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 38
Der große On-Chip-Cache ist nicht bloß schnell, sondern hat die zweite wichtige Aufgabe, energieaufwendige Transfers in den GDDR6-Grafikspeicher abzufangen. Somit schlägt die Idee zwei Fliegen mit einer Klappe: Die Abhängigkeit zum klassischen Grafikspeicher nimmt drastisch ab (wenngleich das Gros der Daten immer noch dort vorliegt) und die Effizienz steigt. Laut AMD erreiche man in der Praxis mit dem Infinity Cache Hitraten zwischen 58 und 80 Prozent. Das bedeutet vereinfacht ausgedrückt, dass viele Daten, die bereits aus dem knappen L2-Cache geschmissen wurden, im Infinity (L3-)Cache landen und die nächsten Berechnungen somit kaum verzögert werden. Dies helfe laut AMD vor allem modernen Spielen, welche viele Daten unmittelbar spatial und temporal wiederverwenden. Man spricht dabei auch von einem Victim Cache, da dieser alle "Opfer"-Daten auffängt, die zu lange nicht abgefragt wurden und daher nicht mehr in der ersten Reihe sitzen (Eviction). Dabei gilt es zu beachten, dass jede Cache-Abfrage ein paar Zyklen Zeit kostet. Kommt es zu einem Fehlschlag (Miss), etwa weil die Daten nicht mehr im L3-Cache, sondern bereits im Grafikspeicher vorliegen, war die Aktion für die Katz und die Pipeline stallt kurz. Laut AMD habe man in Simulationen festgestellt, dass 128 MiByte den besten Kompromiss aus Machbarkeit und Nutzwert darstellen. Mehr Cache ist natürlich aus Leistungssicht immer besser, allerdings erhöhen die SRAM-Zellen die Fertigungskosten und bergen ein Risiko: GPUs, die einen Defekt in Cache-Transistoren haben, können nicht als Radeon RX 6900 XT, RX 6800 XT oder Radeon RX 6800 verwendet werden. Angemessene Redundanzen sichern laut AMD die Ausbeute an nutzbaren Chips.
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 38
Der große On-Chip-Cache ist nicht bloß schnell, sondern hat die zweite wichtige Aufgabe, energieaufwendige Transfers in den GDDR6-Grafikspeicher abzufangen. Somit schlägt die Idee zwei Fliegen mit einer Klappe: Die Abhängigkeit zum klassischen Grafikspeicher nimmt drastisch ab (wenngleich das Gros der Daten immer noch dort vorliegt) und die Effizienz steigt. Laut AMD erreiche man in der Praxis mit dem Infinity Cache Hitraten zwischen 58 und 80 Prozent. Das bedeutet vereinfacht ausgedrückt, dass viele Daten, die bereits aus dem knappen L2-Cache geschmissen wurden, im Infinity (L3-)Cache landen und die nächsten Berechnungen somit kaum verzögert werden. Dies helfe laut AMD vor allem modernen Spielen, welche viele Daten unmittelbar spatial und temporal wiederverwenden. Man spricht dabei auch von einem Victim Cache, da dieser alle "Opfer"-Daten auffängt, die zu lange nicht abgefragt wurden und daher nicht mehr in der ersten Reihe sitzen (Eviction). Dabei gilt es zu beachten, dass jede Cache-Abfrage ein paar Zyklen Zeit kostet. Kommt es zu einem Fehlschlag (Miss), etwa weil die Daten nicht mehr im L3-Cache, sondern bereits im Grafikspeicher vorliegen, war die Aktion für die Katz und die Pipeline stallt kurz. Laut AMD habe man in Simulationen festgestellt, dass 128 MiByte den besten Kompromiss aus Machbarkeit und Nutzwert darstellen. Mehr Cache ist natürlich aus Leistungssicht immer besser, allerdings erhöhen die SRAM-Zellen die Fertigungskosten und bergen ein Risiko: GPUs, die einen Defekt in Cache-Transistoren haben, können nicht als Radeon RX 6900 XT, RX 6800 XT oder Radeon RX 6800 verwendet werden. Angemessene Redundanzen sichern laut AMD die Ausbeute an nutzbaren Chips.
Die Alternative zum Infinity Cache war laut AMD unter anderem ein hochtaktender GDDR6-PHY mit 512 Bit Breite, um vergleichbare Transferraten zu erreichen. Ein solcher Aufbau sei jedoch sehr komplex zu routen und signifikant energiehungriger. AMD spricht vom Faktor 6 bis 8 pro Bit gegenüber der Navi-21-Lösung und nickt damit subtil seinem 512-bittigen Hawaii-Chip zu, welcher auch wegen seiner Heißblütigkeit zu Ruhm gelangte. Am Rande ließ man fallen, dass High Bandwidth Memory (HBM) noch besser gewesen wäre als GDDR6. Da Letzterer jedoch die größtmögliche Flexibilität hinsichtlich Anbietern und Verdrahtung biete, habe man sich dafür entschieden. Möglicherweise sehen wir ja in naher Zukunft RDNA-3-Grafikkarten mit 256 MiByte L3-Cache und 16 GiByte HBM gen2?
Randnotiz: Die Idee, besonders große Caches zu installieren, ist nicht neu, in diesem Umfang jedoch ein Novum. Erinnern Sie sich an Intels Broadwell-Chips mit eDRAM als L4-Cache? Letzterer verhalf der integrierten Iris-Grafikeinheit zu ungeahnter Performance. Damals wurde der Zwischenspeicher aber nicht direkt im Kern platziert, sondern als getrennter Cache-Die günstig gefertigt und neben dem Logik-Die auf einem Substrat platziert.
Strahlenbeschleuniger
Das Beste kommt zum Schluss: Mit RDNA 2 alias Navi 2x implementiert auch AMD endlich dedizierte Rechenwerke zur Raytracing-Beschleunigung in seine GPU-Hardware. Raytracing, die virtuelle Nachbildung von Lichtstrahlen, ist der "Heilige Gral" des Renderings. Wie das Trinkgefäß aus der Artus-Sage soll Raytracing die Gemeinschaft von Problemen befreien und stattdessen Glückseligkeit bringen. Rasterisierung, wie sie 99,99 Prozent der Spiele verwendet, erzielt nur mithilfe von Tricks und guten Künstlern ein realistisches Bild. Der damit erzielten Präzision sind Grenzen gesetzt - bei genauem Blick fallen die Tricks auf und das Kartenhaus zusammen. Die Idee des Raytracings wurde bereits Ende der 1960er-Jahre im Kontext der Computergrafik diskutiert. In den Folgejahren fanden immer wieder dedizierte Raytracing-Beschleuniger den Weg auf den Markt. Beim Offline-Rendering, etwa für Animationsfilme, ist Raytracing seit Jahren der Goldstandard und auch beim professionellen Design wird die Technologie genutzt, um möglichst nah an der Realität zu modellieren. Bei Spielen, in denen es auf Interaktion und somit hohe Bildraten und niedrige Latenz ankommt, scheiterte es bislang an der Leistung beziehungsweise den richtigen Ideen, wie man Raytracing mit Rasterisierung kombiniert.
Mit RDNA 2 schließt AMD folglich zu Nvidia auf, welche bereits Mitte 2018 entsprechende Schaltungen in ihre Grafikkarten implementierten. Dies beinhaltet eine wichtige Software-Komponente, deren Grundstein längst gelegt ist: Der AMD-Treiber bietet erstmals Kompatibilität zum Industriestandard DXR, kurz für DirectX Raytracing. Dabei handelt es sich um eine Windows-10-exklusive Schnittstelle und einen Bestandteil von DirectX 12, welchen AMD zusammen mit Nvidia, Intel, Microsoft und weiteren Gremiumsmitgliedern definiert und verabschiedet hat. Während der Kontakt zur Software standardisiert ist, bleibt die Implementierung auf Transistorebene die Sache der Hersteller.
Aus einer High-Level-Perspektive betrachtet, erinnern AMDs neue "Ray Accelerators" (RA) frappierend an Nvidias "RT Cores". Bei beiden handelt es sich um Fixed-Function-Units, spezialisierte Einheiten, die sich primär um die Nachverfolgung der Strahlen kümmern. Ihre Aufgabe ist es, festzustellen, welche Strahlen wo auf Objekte und somit Polygone stoßen - es gilt sprichwörtlich, eine Nadel im Heuhaufen zu finden. Dabei kommt eine wegweisende Vereinfachung zum Einsatz: Anstatt einer pixelweisen, sehr zeitaufwendigen Suche des Polygons wird der Raum zunächst in größere Würfel aufgeteilt, die mithilfe effizienter Algorithmen schneller Aufschluss über darin enthaltene Polygone geben. Vereinfacht gesagt schaut man zunächst in eine große Kiste, die vom Strahl im ersten Schritt getroffen wurde. In dieser Kiste befinden sich weitere, immer kleinere Kisten. Nach einigen Schritten hat man das entsprechende Polygon relativ schnell gefunden und kann mit dem Shading beginnen, während eine pixelweise Suche womöglich immer noch keine Referenz zu diesem Polygon ergab. Wer's genauer wissen will, füttert eine Suchmaschine mit dem Begriff "Bounding volume hierarchy" (BVH).
Die beiden Grafikspezialisten sind sich auch über die für gute Ergebnisse nötige Anzahl an RT-Einheiten einig: eine pro Compute Unit (AMD) respektive Shader Multiprocessor (Nvidia). Angeführt wird stets der Vergleich mit einer Berechnung "in Software", also ohne spezialisierte Hardware-Einheiten, sondern mithilfe der Shader-ALUs. Bei durchschnittlich mehreren Tausend Instruktionen pro Strahl benötigen konventionelle Rechenwerke verhältnismäßig lange für das BVH Traversal, da sich diese Aufgabe nicht parallelisieren lässt. Ray Accelerators und RT Cores beschleunigen diese Arbeit um den Faktor 10 - auch hier sind sich AMD und Nvidia einig - und arbeiten parallel zu den Shader-ALUs. Ist also alles gleich zwischen AMD und Nvidia? Nein, wenngleich die grundlegende Idee von der Berechnungsweise vorgegeben wird. Nach wie vor lautet das Ziel, klassische Rastergrafik mithilfe von gezielt aufgetragenen Raytracing-Effekten realistischer umzusetzen, weshalb man von Hybrid-Raytracing spricht. "Volles" Raytracing würde beim Detailreichtum aktueller Spiele um Faktoren zu lange dauern und bleibt daher weiter Zukunftsmusik. Mehr dazu im Benchmark-Teil dieses Artikels.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 10
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 10
Navi 21 verfügt im Vollausbau über 80 Ray Accelerators, Ampere im GA102-Silizium über 84 RT Cores. Das wirkt auf den ersten Blick besser vergleichbar als es ist, denn die Schlagkraft pro Einheit unterscheidet sich zwischen den Architekturen. Maßgeblich ist die sogenannte Triangle Intersection Rate, also das Aufspüren von Polygonen im Raum. Nvidia hat diese Metrik in Ampere just verdoppelt, ohne die Anzahl der RT-Cores anzuheben, während ein Direktvergleich mit AMD derzeit nicht zu bekommen ist. Die Radeon-Macher geben immerhin an, dass die Leistung pro Ray Accelerator entweder 4 Box-Intersections oder eine Triangle Intersection pro Takt erreicht und ebenfalls vom Infinity Cache profitiert, da dieser viele der unmittelbar wichtigen Daten parat halten kann. Ferner gibt man auf Nachfrage zu Protokoll, dass es sich beim Raytracing um reine Compute Shader Launches handelt. Shading, Texture Fetching und BVH Traversal (die mit Abstand teuerste Komponente) laufen in Navi 21 stets parallel.
 Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 37
Quelle: AMD
Radeon RX 6000 Series Tech Day Breakout RDNA 2 Deep Dive M. Mantor A. Pomianowski S. Naffziger Embargoed until Nov. 18 at 9am ET Seite 37








