Nvidia Geforce RTX 2080 (Ti)/2070: Turing-Technik-Dossier mit allen Informationen
Nvidia enthüllt sämtliche technische Daten der Geforce RTX 2080 Ti, RTX 2080 und RTX 2070. Ab dem 20. September wird die neue Geforce-Generation mit dem Codenamen Turing offiziell in den Händlerregalen stehen. Die Grafikkartenreihe Geforce RTX 2000 führt unzählige Neuerungen ins Feld, welche wir an dieser Stelle zusammenfassen - die konkreten Produkte Geforce RTX 2080 Ti, RTX 2080 und RTX 2070 behandeln wir in gesonderten Artikeln.

Einstieg: Geforce RTX 2080 (Ti) / RTX 2070
Der Startschuss für Turing ist gefallen. Nvidia lud die versammelte Weltpresse bereits Ende August zu einer umfangreichen Informationsveranstaltung nach Köln ein, welche auch PC Games Hardware wahrnahm. Traditionell unterliegen die Informationen derartiger Events einer sogenannten Verschwiegenheitsvereinbarung, englisch Non-Disclosure Agreement oder kurz NDA. Diese wirkt bis zu einem vom Veranstalter festgelegten Datum und garantiert allen Beteiligten einen fairen Start - Fragen können im Rahmen des Zeitfensters geklärt, die Software kann optimiert und die Hardware kann ausgeliefert werden.
Ein solches NDA hat auch PCGH unterschrieben, um Ihnen zum Start der neuen Geforce-Generation alle Informationen zu liefern. An dieser Stelle sei Ihnen erneut versichert, dass die Vereinbarung keinerlei Bedingungen enthält, die einen objektiven Umgang mit dem Thema verhindern. Sprich, Nvidia hat keine Tabus ausgesprochen und wir schildern die Fakten so neutral wie menschenmöglich. NDAs sind übrigens seit Jahrzehnten üblich und keine Erfindung der Neuzeit.
Was folgt, ist eine sprichwörtliche "Wall of text". Bitte nehmen Sie sich die Zeit, alles aufmerksam durchzulesen und stellen Sie erst dann Ihre Fragen im PCGHX-Forum. Vielen Dank!
Der heutige 14. September markiert den Anfang einer Informationsflut. Man könnte das, was auf Sie und uns zukommt auch einen Tsunami nennen, denn Nvidia präsentiert nicht nur eine brandneue Grafikchip-Architektur, sondern auch unzählige Software-Innovationen. Und hat man all das besprochen, steht noch der Test konkreter Produkte an. Die Geforce RTX 2080 Ti, Geforce RTX 2080 und Geforce RTX 2070 sind jedoch nicht Gegenstand dieses Artikels. Entsprechende Testberichte folgen gestaffelt: Die Geforce RTX 2080 und RTX 2080 Ti sind beide am 19. September fällig, die Geforce RTX 2070 erst im Laufe des Oktobers.
Turing-Grafikchips, Neuerungen, Blockdiagramm
Falls Sie die vergangenen Wochen nicht unter einem Stein oder auf dem Mond verbracht haben, wissen Sie's bereits: Nvidias neue Prozessor-Architektur hört auf den Codenamen Turing, benannt nach dem britischen Mathematiker Alan Turing. Dieser war unter anderem maßgeblich daran beteiligt, dass die von den Nationalsozialisten per Enigma-Maschine verschlüsselten Botschaften geknackt werden konnten. Die Turing-Architektur löst Pascal (Geforce GTX 10) auf lange Sicht in allen Märkten ab, wenngleich zum Start keine Produkte für mittlere und niedrige Preisbereiche verfügbar sind. Wann sich das ändert, ließ Nvidia offen.
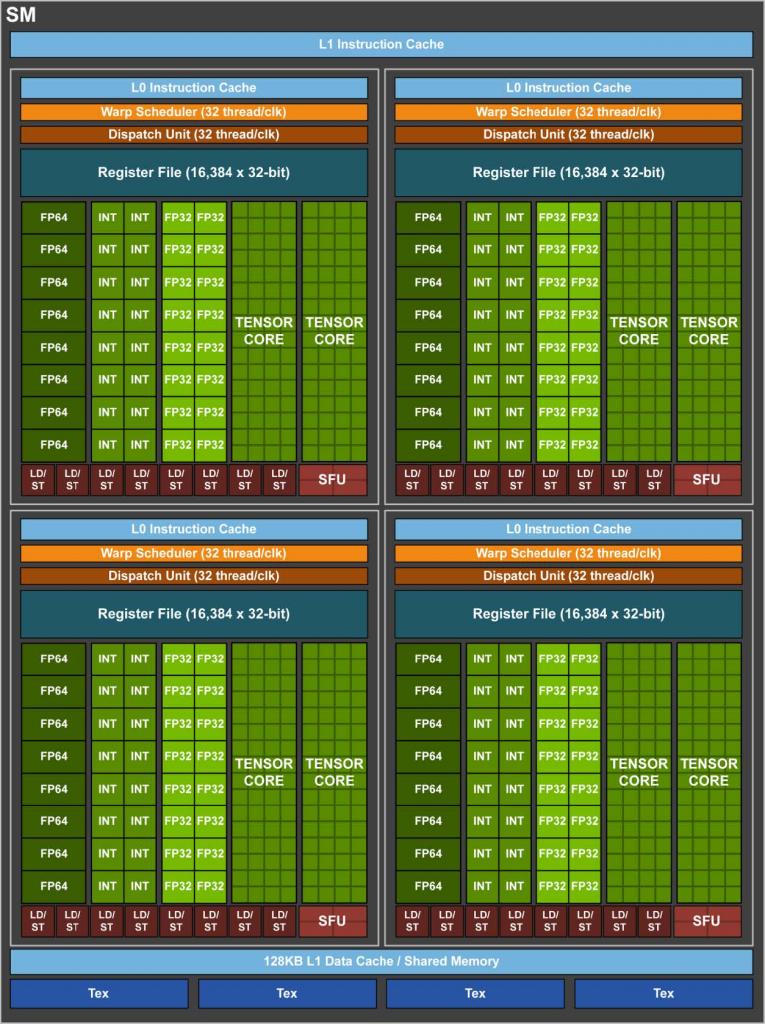
Turing ist laut Nvidia der größte Architekturschritt seit dem legendären G80, welcher seinerzeit vereinheitlichte Shader und DirectX 10 in Hardware einführte. Nvidias Produkte auf Basis dieses Chips, die Geforce 8800 GTX und Ultra, waren selbst eine halbe Dekade später noch spieletauglich. Mit Turing gießen die Kalifornier die seit mehr als zehn Jahren durchgeführten Forschungsergebnisse in Hardware. Das Versprechen lautet nicht weniger, als die "Grafik neu erfunden" zu haben. Dafür hat Nvidia die Module des Chips, den Shader-Multiprozessor (SM), deutlich umgebaut.
Turing: Viel Volta, viel Neues, etwas Pascal
Mit der Volta-Architektur nahm Nvidia bereits einige Änderungen gegenüber Pascal vor. Jeder Volta-SM (im GV100) beherbergt neben 64 FP32-Einheiten ("CUDA cores") auch 64 INT32-Einheiten, sodass der Chip beide Berechnungen gleichzeitig mit voller Geschwindigkeit durchführen kann (concurrent execution). Dazu kommen beim GV100 je 32 FP64-ALUs für doppeltgenaue Berechnungen (SP-DP-Verhältnis 2:1) und acht Tensor-Cores für Deep-Learning-Workloads. Obwohl Volta ein Prozessor für das High Performance Computing ist, hat Nvidia hier erstmals eine bei Gaming-Chips längst etablierte Unterteilung der SMs in Vierergruppen vorgenommen, um die Auslastung pro SM zu erhöhen.


Turing-Rechenwerke im Detail
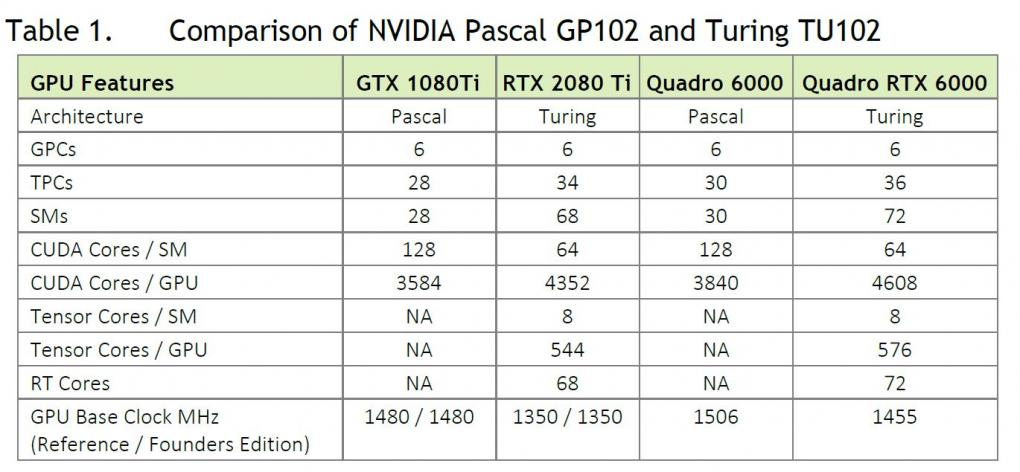
Die Turing-GPU-Familie umfasst derzeit drei Mitglieder: den TU102, den TU104 und den TU106. Der Nvidia-Tradition folgend, handelt es sich beim TU102 um das größte und beim TU106 um das kleinste Modell. Die Abwesenheit eines TU100 ist interessant, denn alle vorherigen Architekturen wurden von einem speziellen Profi-Chip mit glatter Hunderterzahl angeführt (zuletzt Volta GV100, zuvor Pascal GP100).
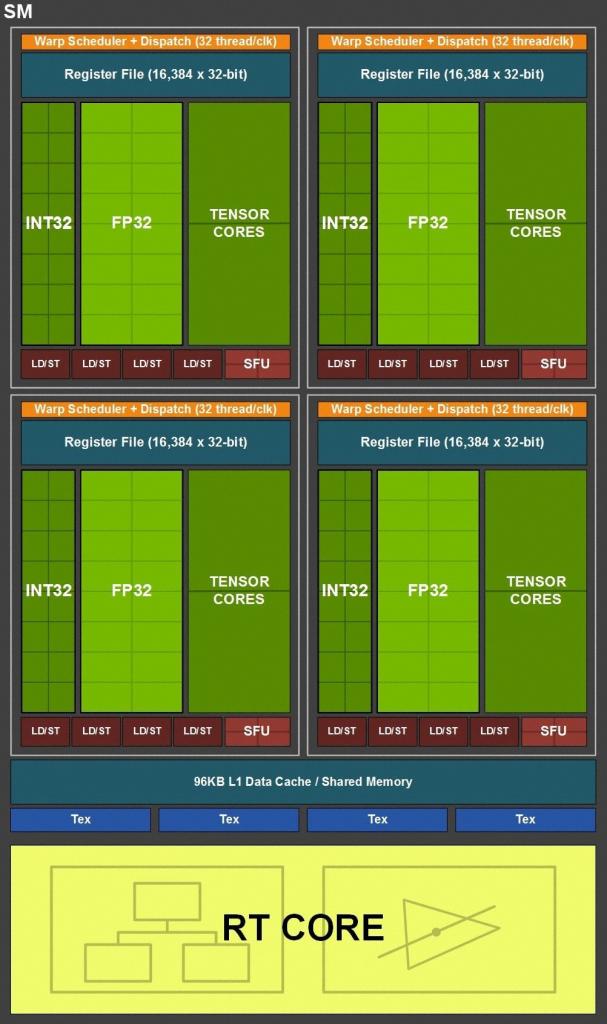
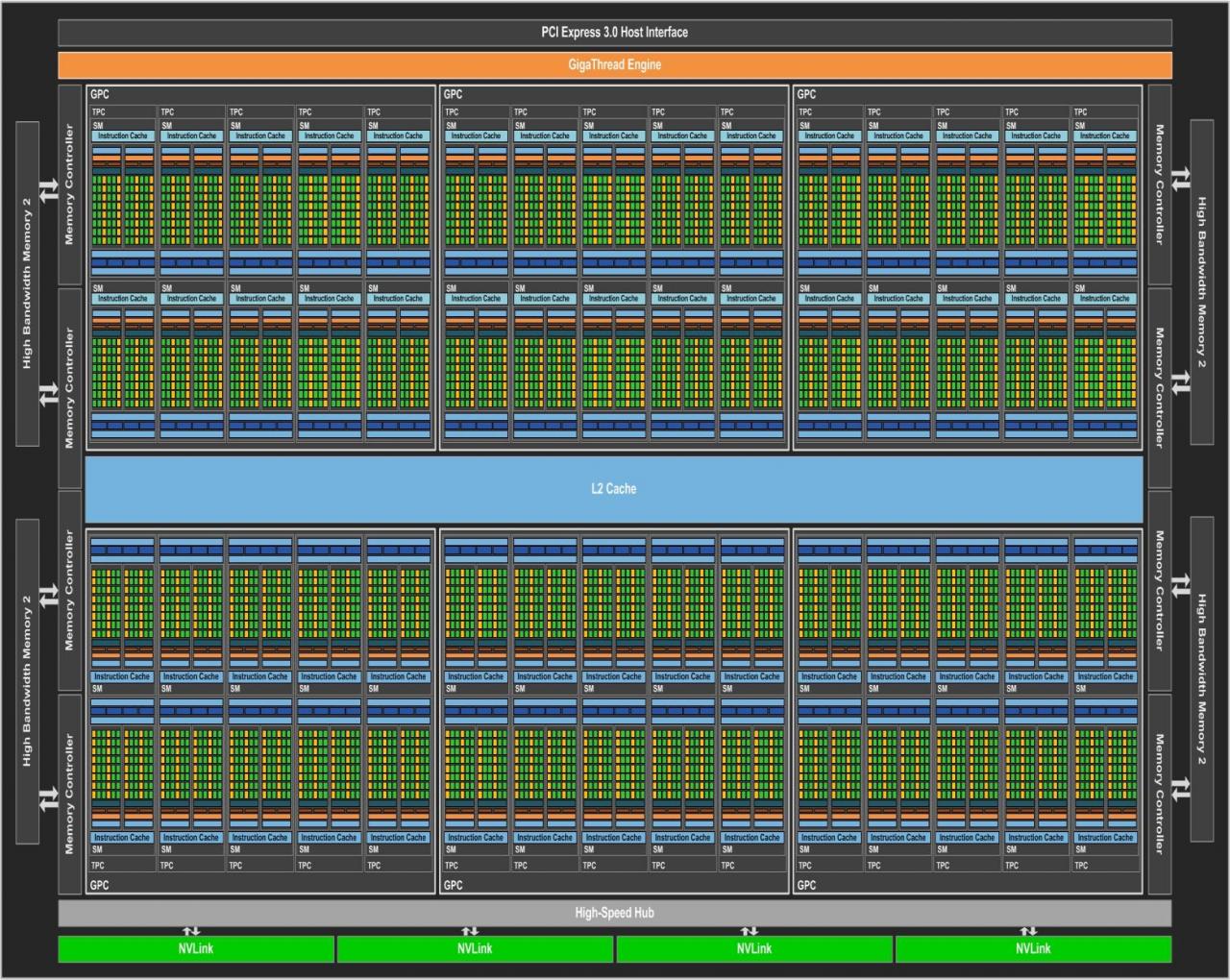
Turing fußt auf dem Volta-Fundament und verfeinert dieses für die angestrebten Einsatzzwecke. Nvidia möchte mit Turing auf drei Hochzeiten gleichzeitig tanzen: Gaming, Künstliche Intelligenz und Raytracing. Da die drei Bereiche jeweils unterschiedliche Anforderungen haben, beherbergt Turing entsprechende Einheiten. Wie vorherige Nvidia-GPUs besteht auch ein Turing-Chip aus verschiedenen Modulen. Die größte Untergruppe ist der Graphics Processing Cluster (GPC). Ein jeder beinhaltet eine Raster-Engine, sechs Texture Processing Cluster (TPC) und jeder TPC zwei Shader-Multiprozessoren (SM). Der Grundaufbau mit 64 FP32-ALUs pro SM, unterteilt in vier Einheitengruppen (4 × 16), folgt Volta. Das Pascal-Topmodell GP102 ist noch anders angeordnet, hier ist nur ein SM pro TPC vorhanden, dafür jedoch doppelt so viele FP32-ALUs (insgesamt 128 statt 64). Die Umstellung soll die Effizienz pro Einheit erhöhen.
 Quelle: nvidia
Pascal GP102 neben Turing TU102
Quelle: nvidia
Pascal GP102 neben Turing TU102
Turing verfügt über zwei FP64-ALUs pro SM und erreicht somit ein SP-DP-Verhältnis von 1:32.
Das Turing-Topmodell TU102 bietet im Vollausbau 6 GPCs mit 72 SMs auf. Das führt zu 4.608 FP32-ALUs, 288 Textureinheiten, 96 Raster-Endstufen, 576 Tensor-Kernen sowie 72 RT-Cores. Interessant ist, dass Nvidia im schematischen Blockdiagramm keinerlei FP64-Einheiten für doppeltgenaue FP-Operationen ausweist, welche bei wissenschaftlichen Kalkulationen gefragt sind. Wir haben nachgehakt: Turing verfügt über zwei FP64-ALUs pro SM und erreicht somit ein SP-DP-Verhältnis von 1:32. Das ist mager, aus Spieler-Sicht aber verschmerzbar, da kein PC-Spiel DP-Leistung heranzieht. Hält man sich die vielen anderen Rechenwerke Turings vor Augen, ist der Verzicht auf zahlreiche FP64-ALUs ein nachvollziehbarer Design-Kompromiss.
Die Tensor-Kerne fanden sich bereits in Volta, wurden laut Nvidia in Turing jedoch verbessert - dazu später mehr. In Gaming-Produkten sind die Tensor Cores ein Novum, weder Pascal noch irgendeine Radeon verfügen darüber. Diese Rechenwerke sind auf Matrixmultiplikation spezialisiert, wie sie beim Deep Learning (Neuronale Netzwerke -> Training -> Künstliche Intelligenz) zuhauf anfällt. Selbstverständlich können auch auch "normale" Shader-ALUs multiplizeren, allerdings um Größenordnungen langsamer als die Tensors. Da Nvidia bereits mit Volta eine Programmierung und somit Nutzung der Tensor-Kerne ermöglichte, verfügen diverse Programmierstudios und Forschungsgruppen bereits über Erfahrung mit diesen Einheiten. Acht von ihnen befinden sich in jedem der insgesamt 72 Shader-Multiprozessoren. Die Geforce RTX 2080 Ti basiert jedoch nicht auf dem TU102-Vollausbau, sondern muss auf vier SMs und somit 32 Tensor-Kerne verzichten. Mehr zu den Tensor-Kernen erfahren Sie im entsprechenden Abschnitt dieses Artikels.

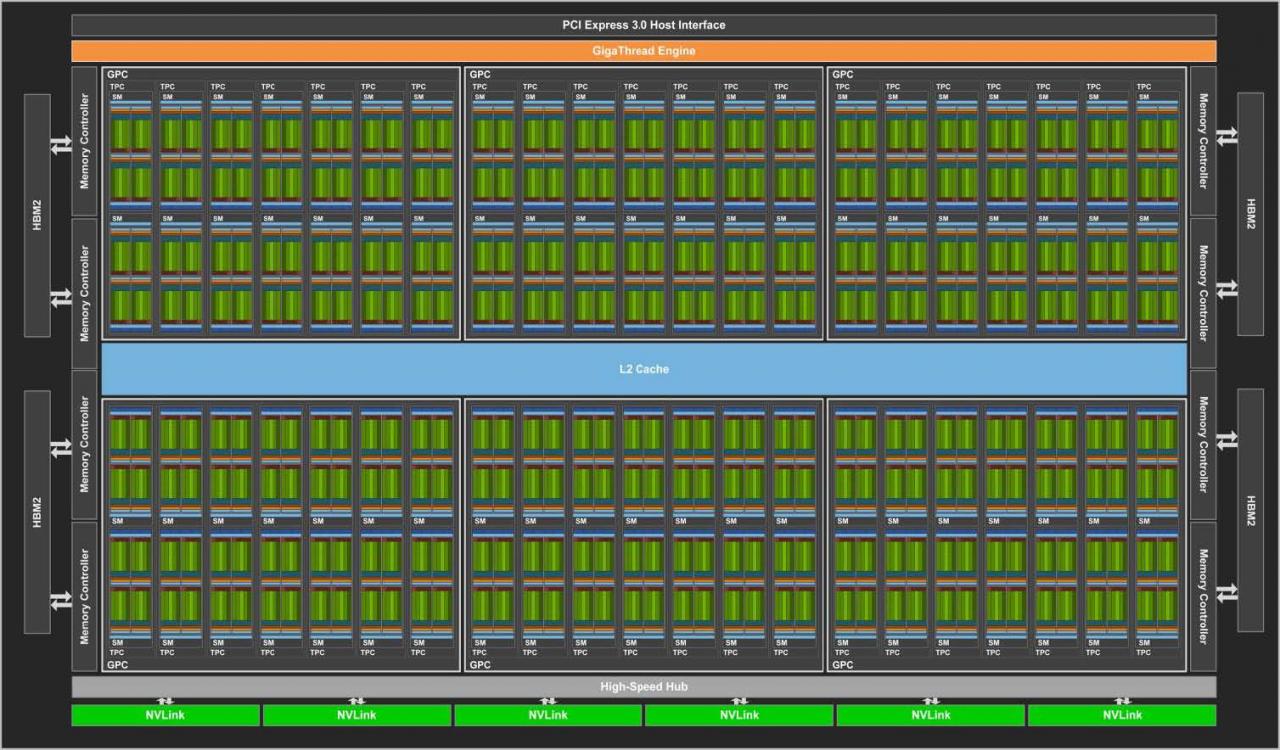
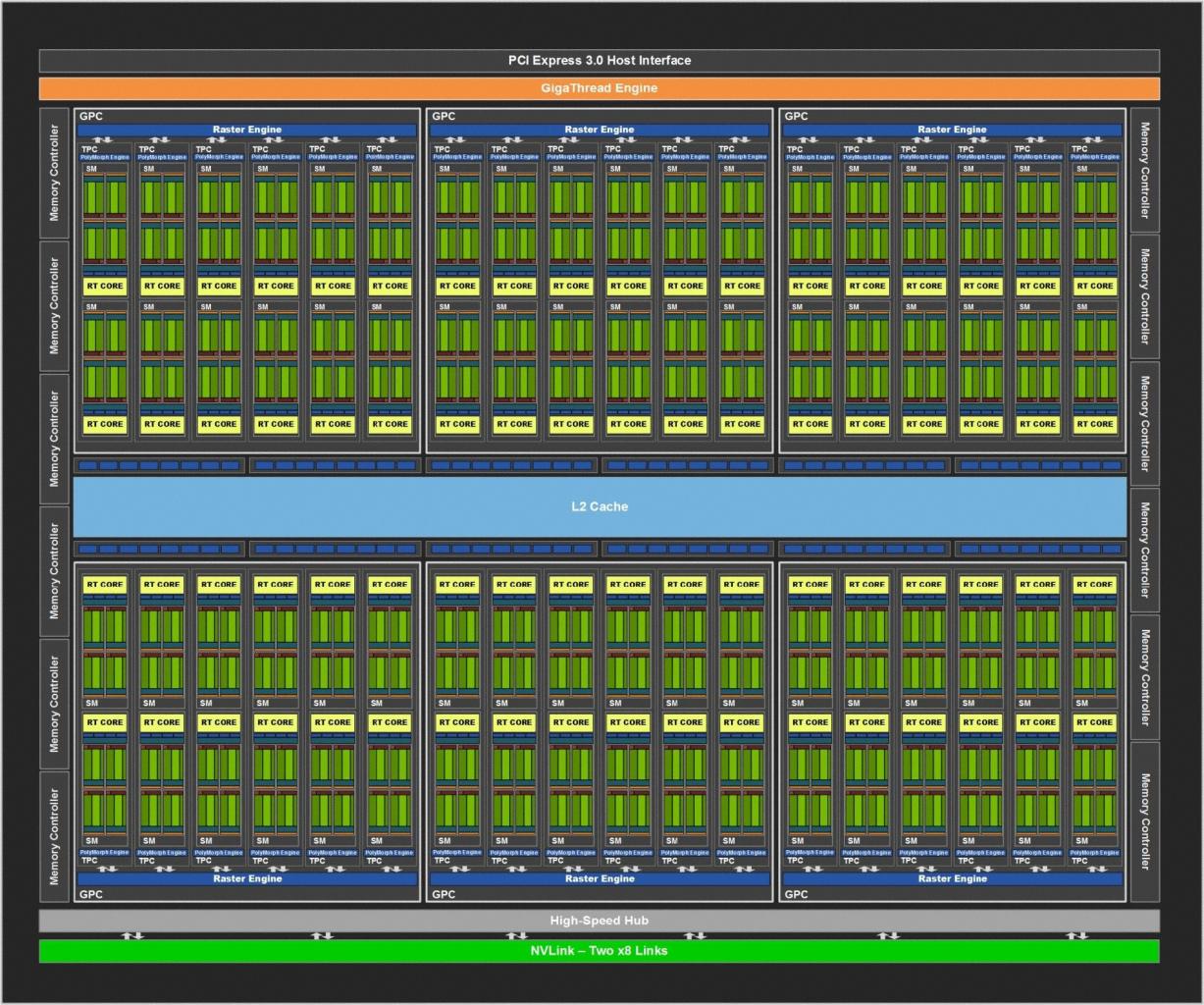
Wirklich neu, das heißt ohne Testlauf in Volta, sind die RT-Kerne. Diese Rechenwerke stellen das Hauptmerkmal der Turing-Grafikkarten zur Verfügung: Raytracing in Echtzeit. Letzteres ist ein dehnbarer Begriff, für manche Spieler fängt "Echtzeit" bei 15 Fps an, andere wünschen sich 144 Fps. Wie dem auch sei, Turing verfügt als erste GPU-Generation über fest verdrahtete Einheiten, die sich einzig und allein um die Strahlenverfolgung kümmern. Mehr zu den Raytracing-Kernen erfahren Sie im entsprechenden Abschnitt dieses Artikels.
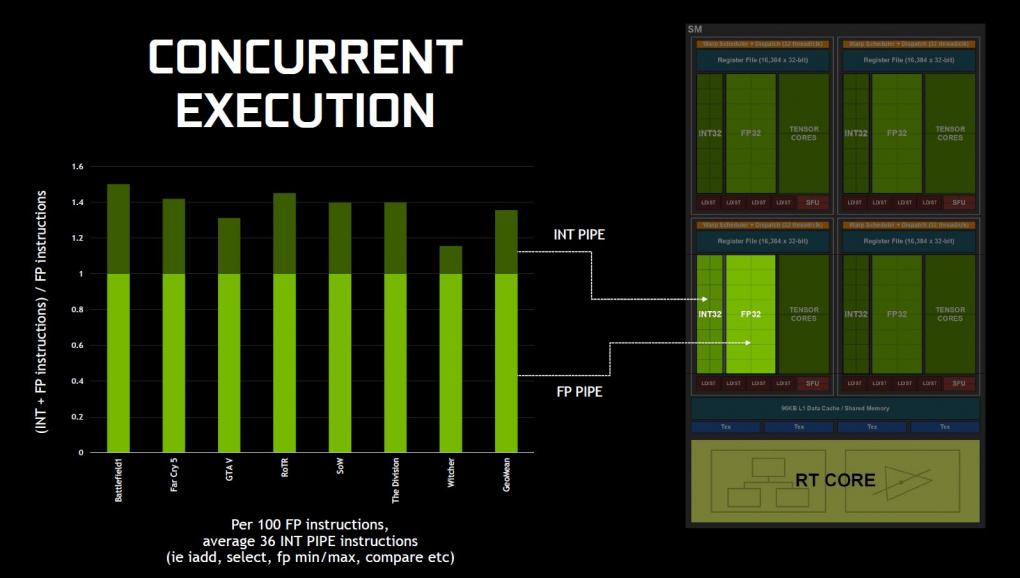
Da FP- und INT-ALUs Hand in Hand arbeiten, steigt die effektive Rechenleistung pro FP32-ALU.
Dass Volta INT32-Einheiten neben den üblichen FP32-ALUs einführte und Turing dieses Design übernimmt, erwähnten wir bereits. Bislang nicht zur Sprache gekommen sind Ursache und Wirkung dieser Modifikation. Nvidia führt Analysen diverser Spiele ins Feld, die einen interessanten Instruktionsmix offenbaren: Pro 100 Gleitkomma-Operationen (FP) fallen durchschnittlich 36 Integer-Operationen (INT) an. Diese verstopfen die Pipeline innerhalb der FP32-ALUs, weshalb die Idee nahelag, ihnen dedizierte INT32-Helferlein abzustellen. Da FP- und INT-ALUs Hand in Hand, also parallel, arbeiten, steigt die effektive Rechenleistung pro FP32-ALU. Dabei lassen sich FP32- und INT32-ALUs nicht einfach addieren, laut Nvidia ergeben sich je nach Spiel jedoch um 15 bis 50 Prozent höhere Durchsatzwerte. Dieser Design-Kniff ist der wahrscheinlichste Grund dafür, warum die Titan V in Quantum Break eine scheinbar überproportionale Leistung erreicht. Das Spiel nutzt exzessives Post-Processing und dabei wohl auch einen anspruchsvollen INT-FP-Instruktionsmix. Wie gehabt sorgt eine Quad-TMU pro SM für eine zeitgemäße Texturierungsleistung.
 Quelle: Nvidia
Turing: Bearbeitet Floating-Point- und Integer-Berechnungen parallel
Quelle: Nvidia
Turing: Bearbeitet Floating-Point- und Integer-Berechnungen parallel
First- bis Last-Level-Cache
Auch das Cache-System wurde bei Turing feinjustiert und orientiert sich an den Volta-Errungenschaften. Der Level-1-Cache und der zuvor getrennt ausgeführte Shared Memory werden zusammengeführt und können jetzt individuell konfiguriert werden (64+32 oder 32+64 KiByte). Die optimale Einstellung ergibt sich aus den Anforderungen, wobei Spiele in der Regel mit 64 KiByte Shader-RAM plus 32 KiByte Textur-Cache konfiguriert werden. Nvidia gibt weiterhin an, dass die L1-Transferrate doppelt so hoch ausfällt wie bei Pascal, lässt sich dabei jedoch keine Referenz zu Volta entlocken. Wir gehen davon aus, dass Volta genauso schnell zwischenspeichert, wobei der GV100 außerdem über einen L1-Pool von 128 anstelle von 96 KiByte verfügt. Der L2-Cache wird von 3 (GP102) auf 6 MiByte (TU102, GV100) vergrößert.
Der auf dem Board installierte Last-Level-Cache, der Grafikspeicher, bindet beim TU102 maximal 384 Datenbahnen an: Zwölf 32-Bit-Datenpfade mit je 1 GiByte GDDR6-Speicher sowie 512 KiByte L2-Cache. Bei der Geforce RTX 2080 Ti fällt ein Speicher-Controller dem Rotstift zum Opfer, sodass nur noch 352 Bit und 11 GiByte zur Verfügung stehen. Der moderne Speicherstandard GDDR6 arbeitet auf den Turing-Grafikkarten mit 14 Gigatransfers pro Sekunde (GT/s) - 7.000 MHz anstelle von bis zu 5.700 MHz beim GDDR5X einer Titan Xp (+23 % Takt). Nvidia bescheinigt der RTX 2080 Ti sogar eine durchschnittlich um 50 Prozent höhere effektive Speichertransferrate als einer GTX 1080 Ti, was durch verbesserte Kompressionsalgorithmen (verlustfrei) erreicht wird. Zu guter Letzt soll der bei Turing installierte 14-Gbps-GDDR6 um 20 Prozent energieeffizienter arbeiten als der nicht genauer benannte GDDR5X bei Pascal.
 Quelle: Nvidia
Die RTX 2080 Ti erzielt laut Nvidia eine um ~50 Prozent höhere Speichertransferrate als die GTX 1080 Ti.
Quelle: Nvidia
Die RTX 2080 Ti erzielt laut Nvidia eine um ~50 Prozent höhere Speichertransferrate als die GTX 1080 Ti.









Dafür ist die 2080 eigentlich konzipiert meiner Meinung nach.
MfG
Dafür ist die 2080 eigentlich konzipiert meiner Meinung nach.
p.s.: Im PCGH Test steht aber etwas von UHD Auflösung/ maxed out und nicht 5k?!??
MfG
http://www.pcgameshardwar...
Du kannst jeden Grafikspeicher aushebeln, wenn du die Auflösung hoch genug wählst.
Ich gebe dir aber trotzdem in soweit Recht, dass für eine Grafikkarte die explizit mit UHD beworben wird 8 GByte schon sehr an der Grenze sind. Und das bereits in heutigen Spielen.
Gesendet von meinem SM-G935F mit Tapatalk