Großangriff auf Nvidia: AMD wappnet sich mit den Instinct MI300 und bis zu 1,5 TByte HBM3-Speicher für das KI-Wettrüsten

AMD hat auf seinem Event "Advancing AI" die KI-Beschleuniger Instinct MI300X und Instinct MI300A mit beeindruckenden Spezifikationen vorgestellt und damit, ohne den schier übermächtigen Konkurrenten namentlich zu nennen, zum Großangriff auf Nvidia im voraussichtlich zukunftsweisenden KI-Wettrüsten. Mit bis zu 2.432 Compute Units und 1,5 TByte HBM3-Speicher pro Plattform möchte der Hersteller den Kampf um die Vorherrschaft bei der KI-Beschleunigung zu seinen Gunsten entscheiden.
Im Rahmen des Events "Advancing AI" hat AMD mit seinen Beschleuniger-Lösungen Instinct MI300X und Instinct MI300A sowie der gewaltigen Instinct MI300X Platform, alle seinen Karten im KI-Wettrüsten auf den Tisch gelegt und seine KI-Flotte gegen den schier übermächtigen Konkurrenten Nvidia in Stellung gebracht. Mit sehr beeindruckenden Spezifikationen zielt AMD auf Nvidias H100 und H200.
AMD geht mit den Instinct MI300 "all in" im KI-Wettrüsten
AMDs neue Generation der HPC- und KI-Beschleuniger setzt sich vorerst aus zwei Produkten zusammen. Während die Instinct MI300X einen klassischen Beschleuniger darstellt, verbirgt sich hinter Instinct MI300A einer riesigen Enterprise-APU, welche eine CPU mit 24 Zen-4-Prozessorkernen, bestehend aus vier CCDs, 128 GiByte schnellen HBM3 und insgesamt 228 Compute Units miteinander vereint.
 Quelle: AMD
Quelle: AMD
 Quelle: AMD
Quelle: AMD
Die Instinct MI300X ist noch einmal besser ausgestattet, wenngleich der klassische Beschleuniger die 24 Zen-4-Prozessorkerne missen lässt und seinerseits stattdessen auf auschließlich insgesamt 304 Compute Units ("CUs") auf Basis von CDNA 3 sowie 192 GiByte HBM3-Speicher setzt, welcher über 8.192-Bit angebunden ist und einen hohen Speichertakt von 5,2 GHz bietet. Die in vielerlei Hinsicht beeindruckenden technischen Spezifikationen der beiden KI-Beschleuniger lesen sich wie folgt.
 Quelle: AMD
Quelle: AMD
 Quelle: AMD
Quelle: AMD
Wie aus den Folien hervorgeht, kombiniert AMD sein bekanntes 2,5D-Packaging mit einem zusätzlichen 3D-Stacking, wie es beispielsweise auch für den 3D V-Cache der Ryzen-Prozessoren zum Einsatz kommt. Der Hersteller spricht deshalb jetzt von einem 3,5D-Stacking, welches für beide Instinct MI300 zum Einsatz kommt.
| AMD Instinct MI300X | AMD Instinct MI300A | |
|---|---|---|
| Architekturen | CDNA 3 | Zen 4 CDNA 3 |
| Prozessorkerne | - | 24 |
| Shadereinheiten | 19.456 | 14.592 |
| Compute Units | 304 | 228 |
| Speicher | 192 GiByte | 128 GiByte |
| Speichertyp | HBM3 ECC | HBM3 ECC |
| Speichertakt | 5,2 GHz | 5,2 GHz |
| Speicherbus | 8.192-Bit | 8.192-Bit |
| Bandbreite | 5,3 TByte/s | 5,3 TByte/s |
| FP16-Performance | 1.300 TFLOPS | 980 TFLOPS |
| FP32-Performance | 163 TFLOPS | 123 TFLOPS |
| FP64-Performance | 82 TFLOPS | 61 TFLOPS |
| TPD | 750 Watt | 550 Watt |
Da eine Instinct MI300X in der Regel aber nie alleine zum Einsatz kommt, hat AMD passend dazu die mächtige Instinct MI300X Platform aufgelegt, welche bis zu acht der schnellen KI-Beschleuniger vereint und damit bis zu 2.432 Compute Units und 155.648 CDNA-3-Shadereinheiten bereitstellen kann. Im Vollausbau stehen dann zudem 1.536 GiByte HBM3 bereit, während die Plattform eine beeindruckende Performance von 20,9 PFLOPS ("FP8") für KI-Beschleunigungen erreicht.
 Quelle: AMD
Quelle: AMD
In ersten Benchmarks schneller als Nvidia H100
In ersten herstellereigenen HPC-Benchmarks ist die AMD Instinct MI300X nicht unwesentlich schneller als Nvidia H100 ("Hopper"), auch wenn jeder Hersteller immer die Szenarien demonstriert, welche dem eigenen Produkt am besten liegen. Dennoch deutet sich an, dass AMD hier eine äußerst leistungsstarke KI-Plattform abgeliefert hat, die Nvidias Produkte zukünftig auf Augenhöhe herausfordern kann.
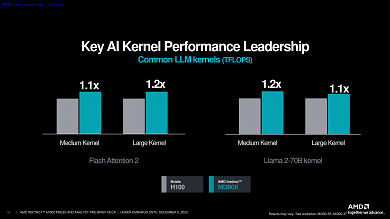 Quelle: AMD
Quelle: AMD
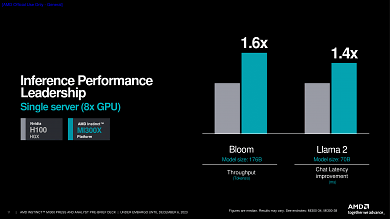 Quelle: AMD
Quelle: AMD
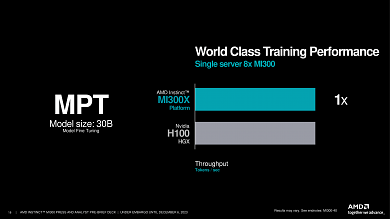 Quelle: AMD
Quelle: AMD
 Quelle: AMD
Quelle: AMD
AMD scheut sich auch nicht, seine KI-Lösungen im Hinblick auf Effizienz und Leistung pro Watt mit Nvidias kommender Speerspitze, der H200 ("Grace Hopper"). Die neue Enterprise-APU Instinct MI300A soll bis zu doppelt so effizient sein wie Nvidias kommender Superchip, wie AMD mit entsprechenden Benchmarks belegt.
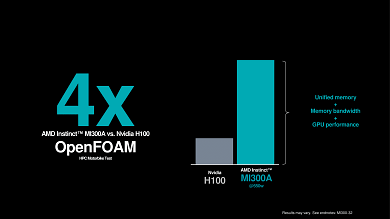 Quelle: AMD
Quelle: AMD
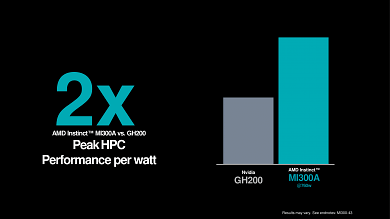 Quelle: AMD
Quelle: AMD
Zum Abschluss demonstrierte AMD mit einer direkten Gegenüberstellung der Instinct MI300A und der Nvidia H100, dass das eigene Produkt aktuell in allen relevanten Teilbereichen seine Führungsposition untermauert oder sich wenigstens auf demselben hohen Niveau wie der große Konkurrent sieht.
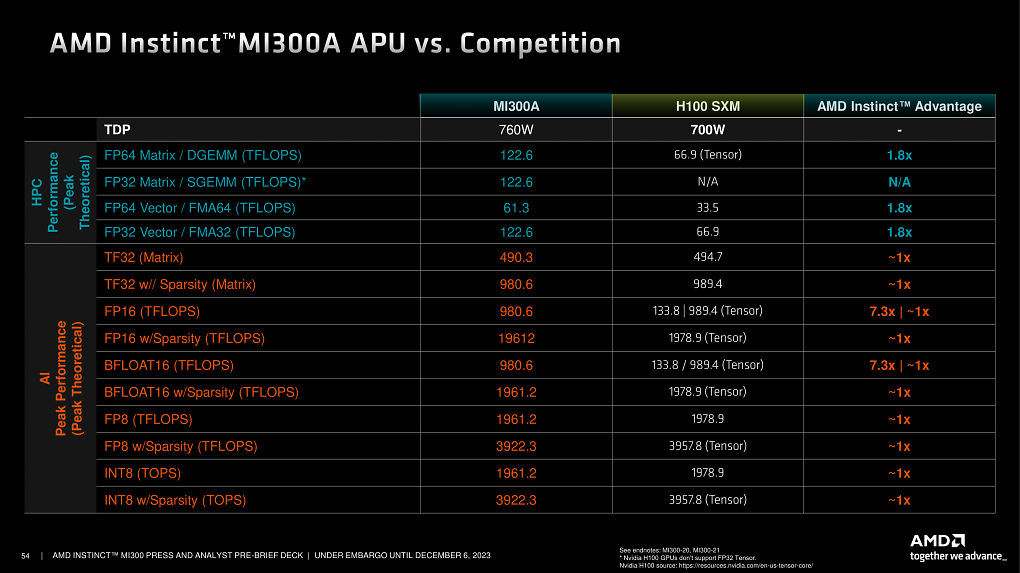 Quelle: AMD
Quelle: AMD
Ryzen 8040 ("Hawk Point") und Ryzen 8050 ("Strix Point")
Neben den neuen Profi-Lösungen für die KI-Beschleunigung in Großrechnern, Supercomputern und Rechenzentren hat AMD auf dem Event auch die neuen APUs der Serie Ryzen 8040 ("Hawk Point") vorgestellt, die im Hinblick auf die mittlerweile immer wichtiger werdende Beschleunigung von KI ebenfalls 60 Prozent schneller arbeiten als ihre direkten Vorgänger. PCGH hat außerdem bereits über die im kommenden Jahr erscheinenden Ryzen AI 8050 ("Strix Point") berichtet.
Wer sich den gesamten zweistündigen Livestream zu AMDs Event "Advancing AI" noch einmal in voller Länge ansehen möchte, dem sei hierfür das offizielle Video zur Veranstaltung auf YouTube ans Herz gelegt.
Ihre Meinung ist gefragt!
Wie stehen Sie zu diesem Thema? Die PCGH-Redaktion freut sich über Ihre fundierte Meinung in den Kommentaren zu dieser Meldung. Um zu kommentieren, müssen Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie bisher noch keinen Account haben, könnten Sie sich hier unverbindlich registrieren. Beachten Sie beim Kommentieren aber bitte die geltenden Forenregeln.
Quelle: AMD









Wenn man z.B. MI300a und Grace Hopper nimmt, ist AMD Nvidia einen kompletten Architekturschritt voraus wodurch sich ein enormer Effizienzgewinn ergibt. Es ist mir an der Stelle auch etwas unbegreiflich, wieso intel ihre APU dafür gestrichen hat.
Es gibt dort schlichtweg die Infrastrukuren und Leute noch nicht so wie beim Marktführer
So wurde etwa Zusammenarbeit mit (AMD und Intel)und Support, Software etc im Vergleich zu Nvidia als "in einem Frühstadium" beschrieben.
Es gibt dort schlichtweg die Infrastrukuren und Leute noch nicht so wie beim Marktführer
Bin gespannt, wobei ich ja KI (Missbrauch) ja absolut grotten mies finde.
Aber die Rechenleistung..toi toi toi
aber hier verhält es sich ähnlich wie Zen vs Intels Core i7 in den letzten Jahren:
das Produkt mag von den Zahlen her super sein, aber Nvidia hat diesen Markt absolut im Griff, auch was Softwaresupport und Co betrifft. Es wird schwer da Fuß zu fassen, ich wünsch es aber natürlich sowohl AMD als auch Intel.
Denn es zeigt sich je mehr Nvidia bei KI verdient, desto weniger Wafer reservieren sie (bei insgesamt beschränktem Kontingent) für Grafikkarten
Nvidia hatte aber einfach viel mehr Geld/Investoren und 3dfx wusste nicht in welche Richtung (Features wie TnL) man in diesem völlig neuen Markt gehen sollte. Als man dann die Entwicklungszyklen, Richtung usw endlich gewusst hat, wars zu spät (abgesehen von einigen anderen Fehlentscheidungen und Personalabgang)