GTX280/260: Chip-Architektur

Nvidia stellt mit dem GT200 den größten Grafikprozessor aller Zeiten vor. PCGH erläutert, was die Geforce GTX 280 und 260 gegenüber den Vorgängern besser machen: von Fps und Power-Management über die Architektur, bis hin zu Lautstärke und Kühlung.
Wie zuvor erwähnt, handelt es sich beim Chip der Geforce GTX280/260 um ein wahres Monstrum. Der direkte Vergleich zu einem Penryn-Prozessor von Intel zeigt die Größenordnung.
 Quelle: Bild PCGH
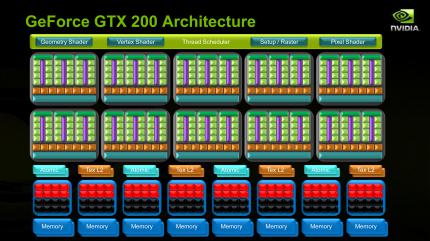
Geforce GTX280 im PCGH-Test: Schematische Übersicht über die Funktionseinheiten (Bild: Nvidia)
Die 1.400 Millionen Transistoren teilen sich auf folgende Funktionsgruppen auf:
Quelle: Bild PCGH
Geforce GTX280 im PCGH-Test: Schematische Übersicht über die Funktionseinheiten (Bild: Nvidia)
Die 1.400 Millionen Transistoren teilen sich auf folgende Funktionsgruppen auf:
• 10 Shader-Cluster zu je 24 ALUs und acht Textureinheiten (Adress & Filter)
• 8 ROP-Partitionen mit angekoppeltem 64-Bit Speichercontroller
• Diverse Caches, Setup-Logik, den Steuerprozessor (Thread-Scheduler) und weitere Einheiten
Nicht im Haupt-Chip enthalten sind die 2D-Funktionen sowie Logik für die SLI-Technik. Diese wurden, wie schon bei der Geforce 8800 GTX/GTS auf Basis des G80, in einen separaten Mini-Chip ausgelagert - den NVIO2.
 Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Wie beim G80 wurden unter anderem 2D-Funktionen im NVIO ausgelagert (Bild: PCGH)
Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Wie beim G80 wurden unter anderem 2D-Funktionen im NVIO ausgelagert (Bild: PCGH)
Recheneinheiten aufgebohrt
 Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Unter diesem Heatspreader versteckt sich der G(T)200-Die (Bild: PCGH)
Auch an der Organisation der Einheiten hat Nvidia etwas gedreht. Kamen bislang in der Direct-X-10-kompatiblen Geforce-Riege noch Gruppen aus zweimal acht Shader-ALUs zum Einsatz, sind es nun drei dieser 8er-Blöcke, die die Basis eines Shader-Clusters oder auch TPC (Thread/Texture Processor Cluster) bilden. Damit wird insgesamt ein höheres ALU-zu-Textur-Verhältnis erreicht und den immer länger werdenden Shader-Programmen und der abnehmenden Bedeutung bildgebender Texturen Rechnung getragen. Das Verhältnis ALU zum TMU wurde damit von 2:1 im G80 auf 3:1 im GT200-Chip erhöht. Nach wie vor gibt es für jede dieser "Multi-Prozessor" genannten Gruppen einen 16 kiByte großen Cache, über welchen die einzelnen ALUs direkt kommunizieren können.
Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Unter diesem Heatspreader versteckt sich der G(T)200-Die (Bild: PCGH)
Auch an der Organisation der Einheiten hat Nvidia etwas gedreht. Kamen bislang in der Direct-X-10-kompatiblen Geforce-Riege noch Gruppen aus zweimal acht Shader-ALUs zum Einsatz, sind es nun drei dieser 8er-Blöcke, die die Basis eines Shader-Clusters oder auch TPC (Thread/Texture Processor Cluster) bilden. Damit wird insgesamt ein höheres ALU-zu-Textur-Verhältnis erreicht und den immer länger werdenden Shader-Programmen und der abnehmenden Bedeutung bildgebender Texturen Rechnung getragen. Das Verhältnis ALU zum TMU wurde damit von 2:1 im G80 auf 3:1 im GT200-Chip erhöht. Nach wie vor gibt es für jede dieser "Multi-Prozessor" genannten Gruppen einen 16 kiByte großen Cache, über welchen die einzelnen ALUs direkt kommunizieren können.
Genau genommen befinden sich im GT200-Chip sogar mehr als 240 Recheneinheiten, denn erstmal für Nvidia-GPUs vermag der GT200 auch FP64-genaue Berechnungen auszuführen. Diese sind für Spiele zwar auf absehbare Zeit irrelevant, im Markt für GPGPU existieren jedoch einige Anwendungsprofile, die die erhöhte Genauigkeit nutzen.
 Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Schematische Aufteilung der Die-Fläche nach Funktionseinheiten (Bild: PCGH)
Wie Nvidias Toni Tamasi PCGH gegenüber angibt, existieren für diese Art von Berechnungen separate Einheiten in der GPU zusätzlich zu den 240 Shader-ALUs. Mit ihnen erreicht der GT200-Chip ein Achtel seiner für Spiele verfügbaren Rechenleistung von 622 MAD-GFLOPs und 933 kombinierten MAD/MUL-GFLOPs. Ja, sie haben richtig gelesen: Die mysteriöse MUL-Einheit ist zurück, welche bereits im G80 angepriesen, aber kaum in Aktion erlebt wurde. Laut Nvidia hat man das Scheduling verbessert, sodass die Multiplikation nun neben der Attributs-Interpolation auch für allgemeine Shader-Programme nutzbar ist. Wir haben dies natürlich nachgeprüft und konnten in speziellen Benchmarks das Vorhandensein dieser Fähigkeit nachweisen. Tatsächlich erreicht der GT200-Chip im GPU-Bench eine MUL-Instruction-Issue-Rate von bis zu 388 Millionen Anweisungen pro Sekunde - rund 35 Prozent mehr als im ADD- oder MAD-Test des Benchmarks. Die theoretisch möglichen plus 50 Prozent sind zwar noch etwas entfernt, aber im Gegensatz zu diesem Ergebnis konnte der G80 gar keine Steigerung der MUL-Rate erzielen.
Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Schematische Aufteilung der Die-Fläche nach Funktionseinheiten (Bild: PCGH)
Wie Nvidias Toni Tamasi PCGH gegenüber angibt, existieren für diese Art von Berechnungen separate Einheiten in der GPU zusätzlich zu den 240 Shader-ALUs. Mit ihnen erreicht der GT200-Chip ein Achtel seiner für Spiele verfügbaren Rechenleistung von 622 MAD-GFLOPs und 933 kombinierten MAD/MUL-GFLOPs. Ja, sie haben richtig gelesen: Die mysteriöse MUL-Einheit ist zurück, welche bereits im G80 angepriesen, aber kaum in Aktion erlebt wurde. Laut Nvidia hat man das Scheduling verbessert, sodass die Multiplikation nun neben der Attributs-Interpolation auch für allgemeine Shader-Programme nutzbar ist. Wir haben dies natürlich nachgeprüft und konnten in speziellen Benchmarks das Vorhandensein dieser Fähigkeit nachweisen. Tatsächlich erreicht der GT200-Chip im GPU-Bench eine MUL-Instruction-Issue-Rate von bis zu 388 Millionen Anweisungen pro Sekunde - rund 35 Prozent mehr als im ADD- oder MAD-Test des Benchmarks. Die theoretisch möglichen plus 50 Prozent sind zwar noch etwas entfernt, aber im Gegensatz zu diesem Ergebnis konnte der G80 gar keine Steigerung der MUL-Rate erzielen.
 Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Das Hynix-GDDR3-RAM ist mit 1.200 MHz spezifiert (Bild: PCGH)
Weitere Verbesserungen, ebenfalls vielmehr im Hinblick auf die nutzbare Rechenleistung als auf theoretisch mögliche Spitzenwerte, erreicht Nvidia durch eine Vergrößerung des Register-Files. Dabei handelt es sich um den Speichertyp, welcher am dichtesten an den ALUs arbeitet und auf den noch schneller zugegriffen werden kann, als auf den 16-kiByte-Cache der Streaming-Multiprozessoren. Ist dieser Registerspeicher voll, müssen Daten aus dem langsameren VRAM nachgeladen werden. Aus der CUDA-Dokumentation geht hervor, dass beispielsweise die ersten CUDA-Chips (G80) bei knapp 10,7 Registern pro Thread an die Grenzen des Registerfiles stießen.
Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Das Hynix-GDDR3-RAM ist mit 1.200 MHz spezifiert (Bild: PCGH)
Weitere Verbesserungen, ebenfalls vielmehr im Hinblick auf die nutzbare Rechenleistung als auf theoretisch mögliche Spitzenwerte, erreicht Nvidia durch eine Vergrößerung des Register-Files. Dabei handelt es sich um den Speichertyp, welcher am dichtesten an den ALUs arbeitet und auf den noch schneller zugegriffen werden kann, als auf den 16-kiByte-Cache der Streaming-Multiprozessoren. Ist dieser Registerspeicher voll, müssen Daten aus dem langsameren VRAM nachgeladen werden. Aus der CUDA-Dokumentation geht hervor, dass beispielsweise die ersten CUDA-Chips (G80) bei knapp 10,7 Registern pro Thread an die Grenzen des Registerfiles stießen.
Zum einen belegen 64-Bit-Threads natürlich potenziell die doppelte Menge Registerspeicher, zum anderen war Nvidia das Problem der knappen Register durchaus bewusst, sodass der Speicherplatz dieses Files pro ALU im GT200 verdoppelt wurde.
Auch das Threading-Konzept wurde weiter ausgebaut. Ein Thread beinhaltet ein Programm, welches die ALUs ausführen . Es kann sich dabei um ein Shader-Programm für eine Pixelgruppe, um einen PhysX-Solver-Kernel oder eine beliebige andere Anweisungsfolge handeln. Insgesamt können nun pro Streaming-Multiprozessor 32 statt wie bisher 24 Threads in Bearbeitung gehalten werden, sodass die Latenz, welche beim Zugriff auf und Filtern von Texturen entsteht, besser versteckt werden kann. Wann immer ein Thread auf eine Rücklieferung einer Speicher- oder Filteranfrage warten muss, tritt sofort ein anderer an dessen Stelle und es wird weitergerechnet. Es leuchtet also ein, dass eine höhere Anzahl gleichzeitiger Threads die Auslastung der GPU verbessert.
Der logisch gesehen letzte Punkt der Render-Pipeline, an dem Nvidia Verbesserungen hat einfließen lassen, sind die Raster-Operatoren (auch ROP oder RBE, Render Backends genannt). Teilten sich in der ersten Direct-X-10-Generation von GPUs noch je zwei ROPs eine Blending-Einheit, verfügt beim Geforce-GTX-Chip nun jede ROP einzeln über diese Fähigkeit. Die Gesamtzahl der Blendings pro Takt steigt also von 12 auf nunmehr 32. An den MSAA-Fähigkeiten tat sich indessen nicht: Noch immer beherrschen die ROPs 4x MSAA in einem Arbeitsschritt, für 8xQ ist ein Loop nötig. Deshalb kosten alle FSAA-Modi, die 8x Multisampling beinhalten (8xQ, 16xQ, 32xS), wie bei der GF8/9-Serie noch immer sehr viel Leistung.
 Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Die GTX260, welche uns leider teildefekt erreichte, verfügt über den G200-100-A2-Chip(Bild: PCGH)
Auch die zwischenzeitlich kritisierte Geometry-Shader-Performance hat Nvidia verbessert. Zwar verfügen Direct-X-10-Chips über vereinheitlichte Shader-ALUs, der Geometry-Shader nimmt jedoch eine Sonderstellung dahingehend ein, dass mithilfe entsprechender Programme mehr Ausgabewerte erzeugt werden können, als in den Shader einfließen (Stream Out). Diese Werte müssen zwischengespeichert werden, was bei nicht ausreichend dimensioniertem Cache schnell einen Flaschenhals bilden kann. Der GT200 verfügt über einen sechsmal so großen GS-Cache wie der G80 und kann demnach deutlich performanter zusätzliche Geometrie oder Cube-Maps erzeugen. Tests mit Rightmark3D 2.0 unter Vista und Direct X 10 untermauern Nvidias Behauptung.
Quelle: Bild: PCGH
Geforce GTX280 im PCGH-Test: Die GTX260, welche uns leider teildefekt erreichte, verfügt über den G200-100-A2-Chip(Bild: PCGH)
Auch die zwischenzeitlich kritisierte Geometry-Shader-Performance hat Nvidia verbessert. Zwar verfügen Direct-X-10-Chips über vereinheitlichte Shader-ALUs, der Geometry-Shader nimmt jedoch eine Sonderstellung dahingehend ein, dass mithilfe entsprechender Programme mehr Ausgabewerte erzeugt werden können, als in den Shader einfließen (Stream Out). Diese Werte müssen zwischengespeichert werden, was bei nicht ausreichend dimensioniertem Cache schnell einen Flaschenhals bilden kann. Der GT200 verfügt über einen sechsmal so großen GS-Cache wie der G80 und kann demnach deutlich performanter zusätzliche Geometrie oder Cube-Maps erzeugen. Tests mit Rightmark3D 2.0 unter Vista und Direct X 10 untermauern Nvidias Behauptung.
 Quelle: Bild PCGH
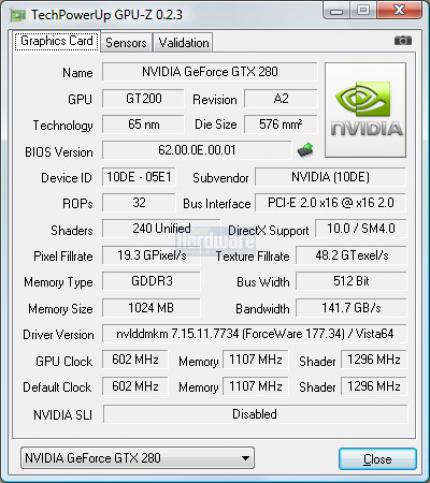
Geforce GTX280 im PCGH-Test: GPU-z gibt ab Version 0.2.3 Aufschluss über die internen Einheiten des Chips. (Bild: PCGH)
Quelle: Bild PCGH
Geforce GTX280 im PCGH-Test: GPU-z gibt ab Version 0.2.3 Aufschluss über die internen Einheiten des Chips. (Bild: PCGH)
 Quelle: Bild: PCGH
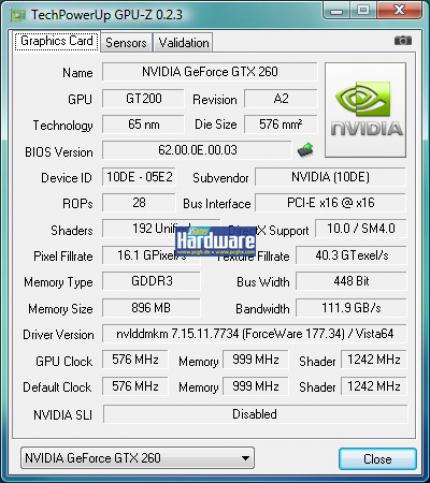
Geforce GTX260 im PCGH-Test: GPU-z gibt ab Version 0.2.3 Aufschluss über die internen Einheiten des Chips. (Bild: PCGH)
Quelle: Bild: PCGH
Geforce GTX260 im PCGH-Test: GPU-z gibt ab Version 0.2.3 Aufschluss über die internen Einheiten des Chips. (Bild: PCGH)








