
RTX 4070 Ti im Test: Feature-Finesse nicht verpassen
Mit der RTX-40-Reihe bietet Nvidia nicht bloß mehr vom Alten, sondern auch neue Funktionen im Chip. Ein kleiner Technik-Tauchgang mit und rund um Ada Lovelace.
In diesem Artikel
- Seite 1 Geforce RTX 4070 Ti im Test: Spezifikation
- Seite 2 RTX 4070 Ti im Test: Feature-Finesse nicht verpassen
- Seite 3 Geforce RTX 4070 Ti im Test: Benchmarks in 4 Auflösungen
- Seite 4 Geforce RTX 4070 Ti im Test: Raytracing-Benchmarks und Preis/Leistung
- Seite 5 Geforce RTX 4070 Ti im Test: Leistungsaufnahme & Effizienz
- Seite 6 Geforce RTX 4070 Ti im Test: Zusammenfassung mit Fazit
- Seite 7 Bildergalerie
Mit der "Ada Lovelace"-Mikroarchitektur erfindet Nvidia das Rad zwar nicht neu, beschleunigt jedoch diverse Rechenwerke und führt neue Funktionen ein. Einige davon wirken immer, da sie durch Logik- und Takt-Verbesserungen kommen, andere benötigen eine Ansprache durch Spiele- und Programm-Entwickler - sind dann aber besonders effektiv. Sehen wir uns an, was die Ada-Drillinge im Gepäck haben und wie der Vorgänger Ampere im Vergleich dasteht.
Geforce RTX 4070 Ti: AD104 feiert sein Debüt
Der neueste und bislang kleinste Ada-Prozessor hört auf den Namen AD104. Auf der Geforce RTX 4070 Ti kommt er in einer für alle Gaming-relevanten Belange vollständigen Konfektion zum Einsatz. Diese beinhaltet 5 Graphics Processing Clusters (GPCs), 30 Texture Processing Clusters (TPCs), 60 Streaming-Multiprozessoren (SMs), somit 7.680 FP32-ALUs sowie eine 192-Bit-Speicherschnittstelle mit sechs 32-Bit-Controllern und 48 MiByte Level-2-Zwischenspeicher. Pro SM sind außerdem zwei FP64-ALUs enthalten, sodass die FP32:FP64-Rate wie bei Ampere 64:1 beträgt. Vergleicht man die RTX 4070 Ti mit einer RTX 4090, bietet Letztere weniger als die doppelten Durchsatzwerte - der Vollausbau des AD102-Chips ist hingegen pro Takt um Faktor 2,4 stärker. Der AD104 wird unterdessen auch die kommende Geforce RTX 4070 (Non-Ti) antreiben, hier in abgespeckter Form.


Geforce RTX 4080: AD103
Der zweitgrößte Ada-Prozessor AD103 beinhaltet 7 Graphics Processing Clusters (GPCs), 40 Texture Processing Clusters (TPCs), 80 Streaming-Multiprozessoren (SMs), somit 10.240 FP32-ALUs sowie eine 256-Bit-Speicherschnittstelle mit acht 32-Bit-Controllern und 64 MiByte Level-2-Zwischenspeicher. Pro SM sind außerdem zwei FP64-ALUs enthalten, sodass die FP32:FP64-Rate wie bei Ampere 64:1 beträgt. Die Geforce RTX 4080 verwendet einen leicht abgespeckten Chip mit der Kennung AD103-300, bei dem das volle Speicher-Subsystem mit allen Caches und Datenbahnen aktiv ist. Der Kern arbeitet jedoch nur mit 76 von 80 Shader-Multiprozessoren (-5 %). Reserven für eine nachfolgende Geforce RTX 4080 Super, welche den vollen Chip sowie höhere Taktraten auffährt, sind folglich gegeben.
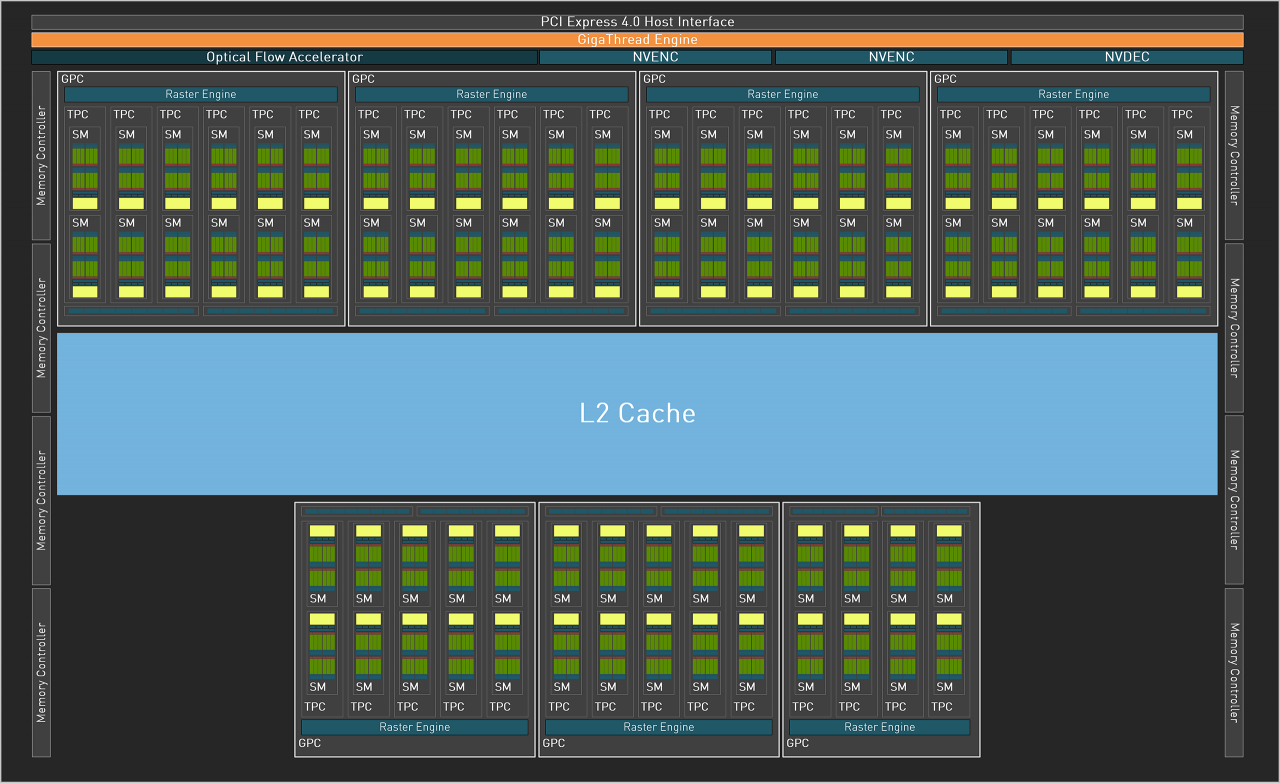
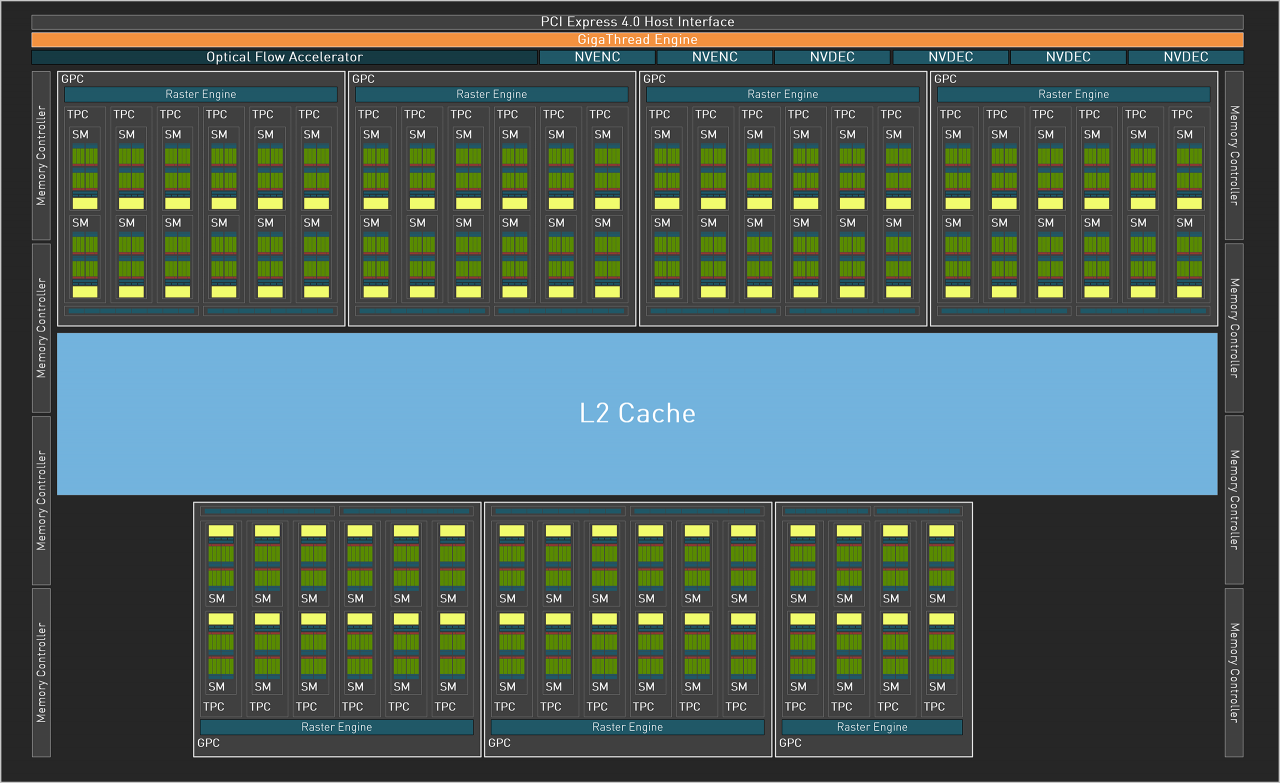
Geforce RTX 4090: AD102
Die "Ada-Vollversion" AD102 beinhaltet 12 Graphics Processing Clusters, 72 Texture Processing Clusters, 144 Streaming-Multiprozessoren, somit 18.432 FP32-ALUs sowie eine 384-Bit-Speicherschnittstelle mit zwölf 32-Bit-Controllern. Pro SM sind außerdem zwei FP64-ALUs enthalten, sodass die FP32:FP64-Rate wie bei Ampere 64:1 beträgt. Die Geforce RTX 4090 basiert nicht auf dem Vollausbau des AD102, sondern einem verhältnismäßig starken Beschnitt namens AD102-300. Dieser bietet 128 SMs, 16.384 FP32-ALUs (je -11 %) und 72 anstelle von 96 MiB Level-2-Cache (-25 %). Reserven für eine Geforce RTX 4090 Ti respektive neue Titan-Grafikkarte sind folglich geschaffen. Außerdem gehen wir davon aus, dass der AD102 in weiter abgespeckter Form auch für eine Geforce RTX 4080 Ti Verwendung finden wird.


Raytracing Cores 3.0
Nachdem Turing (RTX 20) dedizierte Hardware-Einheiten für das Raytracing einführte, verbesserte Nvidia diese Rechenwerke erstmals in Ampere (RTX 30) um Faktor 2. Für die dritte Generation Ada Lovelace (RTX 40) nennt Nvidia eine erneut verdoppelte Ray-Triangle Intersection Rate gegenüber Ampere - pro Takt. Die RT-Cores 3.0 melden folglich doppelt so schnell einen Hit oder Miss beim Durchstöbern der Raytracing-Datenstruktur (BVH) und viermal so schnell wie jene in Turing. Während diese Verbesserung automatisch in Kraft tritt, verfügt Ada außerdem über zwei Funktionen, die eine deutlich höhere Leistung erlauben, sofern ein Entwickler diese explizit anspricht. Da wäre die doppelte Alpha-Traversal-Rate, welche mithilfe der sogenannten Opacity Micromap Engine (OMM) möglich wird. Dahinter steckt eine Funktion, um die beim Raytracing grundsätzlich problematischen Objekte mit Transparenzwert (Alpha) - wie Blätter oder Zäune - effizienter abzuarbeiten. Zu guter Letzt bieten Adas RT-Kerne eine sogenannte Displaced Micro-Mesh Engine (DMM), bei der es sich um eine Art spezielle Tessellation für Raytracing-Workloads handelt. Durch die Erzeugung feiner Details innerhalb der RT-Kerne (anstelle der kompletten Pipeline) soll die Erstellung der BVH-Datenstruktur (Bounding Volume Hierarchy) satte zehnmal schneller vonstattengehen und nur noch 1/20 des Speichers benötigen. Doch das ist Zukunftsmusik, derzeit ist kein Spiel mit diesen Funktionen bestätigt.
Shader Execution Reordering
Beim Shader Execution Reordering (SER) handelt es sich um eine weitere Effizienzfunktion, welche Raytracing-Berechnungen auf die Sprünge helfen soll. Das Feature ist in der Lage, die gerade bei komplexem Raytracing diffus anfallenden Arbeitsanweisungen vorzusortieren, damit das Shading effizienter und ohne "Luftblasen" in der Pipeline vonstattengehen kann. Im Gegensatz zu Intel, deren vergleichbare Thread Sorting Unit (TSU) autark agiert, benötigt Nvidias SER-Einheit eine gezielte Ansprache durch die Applikation. Das lohnt sich, laut Nvidia steigt die Leistung durch SER bestenfalls um den Faktor 2. Die Kalifornier führen außerdem das derzeit in Arbeit befindliche "Raytracing Overdrive"-Update für Cyberpunk 2077 an, bei dem man einen durchschnittlichen Leistungsgewinn von 44 Prozent gemessen haben will. SER ist neu in Ada, weder Ampere noch Turing verfügen über diesen optionalen Kniff. Derzeit können Entwickler SER nur über NVAPI-Erweiterungen implementieren, doch Nvidia arbeitet laut eigener Aussage mit Microsoft zusammen, um das Feature im Rahmen von DirectX zu spezifizieren - beispielsweise im Rahmen eines neuen DXR Tier 1.2.
Optical Flow Accelerator
Das wohl spannendste Feature einer RTX-40-Grafikkarte ist DLSS 3, denn die dritte Hauptversion des KI-gestützten Upsamplings führt eine sogenannte Frame-Generation ein. Was Fernseher und Videobearbeitungsprogramme längst beherrschen, hieven die Geforce-Macher für den Echtzeiteinsatz auf eine neue Ebene: Hier wird nicht stumpf von Frame zu Frame interpoliert, um mehr Bilder pro Sekunde zu erhalten, sondern mithilfe von zwei Informationsströmen gearbeitet. Da wären die vom Spiel bereitgestellten Bewegungsvektoren (Motion Vectors), welche beispielsweise angeben, in welche Richtung sich Objekte bewegen - diese Information ist bereits für erfolgreiches DLSS-2-Upsampling notwendig. Hinzu kommt die neue Optical Flow Estimation, welche unter anderem bei Objekten hilft, für die keine Bewegungsvektoren gemeldet werden, etwa Partikel. Ausgeklügelte Algorithmen sorgen dafür, dass nach jedem echten Frame jeweils ein künstliches auf der GPU erzeugt wird, ohne dass der Prozessor davon weiß. Dadurch kann DLSS 3 Frame Generation auch bei CPU-limitierten Szenarien die Bildrate (bestenfalls) verdoppeln.
 Quelle: Nvidia (Screenshot: PCGH)
Ada Optical Flow Accelerator - OFA
Laut Nvidia ist der Optical Flow Accelerator (OFA) ein wichtiger Pfeiler des Erfolgs. Dabei handelt es sich um eine dedizierte Recheneinheit, welche in jedem Grafikprozessor einmal vorhanden ist. Ampere verfügt über die erste Inkarnation eines OFA, mit bestenfalls 126 Tera-OPS (in der Geforce RTX 3090 Ti). Die Ada-Chips AD102, AD103 und AD104 verfügen hingegen über je einen OFA mit über 300 TOPS, ergo Faktor 2,5 gegenüber der besten Ampere-Lösung. Diese Verbesserung macht Frame Generation laut Nvidia erst ohne lästige Latenz bei guter Qualität praxistauglich. Mehr zu DLSS 3 mit Augenmerk auf die neue Geforce RTX 4070 Ti lesen Sie im Artikel Geforce RTX 4070 Ti Launch - DLSS 3.0 und die clevere Frame-Generation.
Quelle: Nvidia (Screenshot: PCGH)
Ada Optical Flow Accelerator - OFA
Laut Nvidia ist der Optical Flow Accelerator (OFA) ein wichtiger Pfeiler des Erfolgs. Dabei handelt es sich um eine dedizierte Recheneinheit, welche in jedem Grafikprozessor einmal vorhanden ist. Ampere verfügt über die erste Inkarnation eines OFA, mit bestenfalls 126 Tera-OPS (in der Geforce RTX 3090 Ti). Die Ada-Chips AD102, AD103 und AD104 verfügen hingegen über je einen OFA mit über 300 TOPS, ergo Faktor 2,5 gegenüber der besten Ampere-Lösung. Diese Verbesserung macht Frame Generation laut Nvidia erst ohne lästige Latenz bei guter Qualität praxistauglich. Mehr zu DLSS 3 mit Augenmerk auf die neue Geforce RTX 4070 Ti lesen Sie im Artikel Geforce RTX 4070 Ti Launch - DLSS 3.0 und die clevere Frame-Generation.

- Seite 1 Geforce RTX 4070 Ti im Test: Spezifikation
- Seite 2 RTX 4070 Ti im Test: Feature-Finesse nicht verpassen
- Seite 3 Geforce RTX 4070 Ti im Test: Benchmarks in 4 Auflösungen
- Seite 4 Geforce RTX 4070 Ti im Test: Raytracing-Benchmarks und Preis/Leistung
- Seite 5 Geforce RTX 4070 Ti im Test: Leistungsaufnahme & Effizienz
- Seite 6 Geforce RTX 4070 Ti im Test: Zusammenfassung mit Fazit
.gif)








MfG
Raff
Ich verstehe da was nicht, wenn ich Seite 3 und Seite 4 Vergleiche, vielleicht hat da jemand eine Antwort für mich.
Als Resolution Einstellung nehme ich 2560x1440.
Ich vergleiche die Geforce RTX 4070 Ti auf Seite 3 mit Seite 4.
Ich vergleiche Cyberpunk 2077 auf Seite 3 mit Seite 4.
Auf Seite 3 (ohne Ray Tracing) wird eine Average FPS von 64.4 und Low 1% FPS von 57 angegeben.
Auf Seite 4 (mit Ray Tracing) wird eine Average FPS von 71.5 und Low 1% FPS von 64 angegeben.
Warum habe ich eine höhere FPS mit Ray Tracing?
Dabei verbraucht die Karte auch noch etwa 40% weniger.
Die 240 Euro Aufpreis haben sich aus meiner Sicht momentan absolut gelohnt.
Aber schade dass ADA so hochpreisig ist, es sind technisch wirklich tolle Karten.
Jetzt stehe ich mit der 4070 Ti bei 90-99% GPU Auslastung, 120+ FPS und kann meine Pläne die CPU und den Unterbau zu upgraden erst mal vertagen. Hätte nicht gedacht, dass die Frame Generation Kiste so gut funktioniert. Habe auch Spiderman, Cyberpunk, Witcher, Atomic Heart damit getestet und selbst Cyberpunk läuft dann mit 100-130 FPS auf max. Settings in WQHD. Macht schon laune.