Open-Source-DLSS von Intel: XeSS in Aktion, alle Informationen
Intels kommende Arc-Grafikkarten werden mit einer DLSS-Alternative starten, welche ebenso wie das Nvidia-Verfahren mit KI-Informationen arbeitet. Mehr noch, Intels Verfahren namens XeSS (Xe Super Sampling) wird quelloffen sein und soll auch auf Radeon- und Geforce-Grafikkarten laufen. Wir fassen die Informationen zusammen.

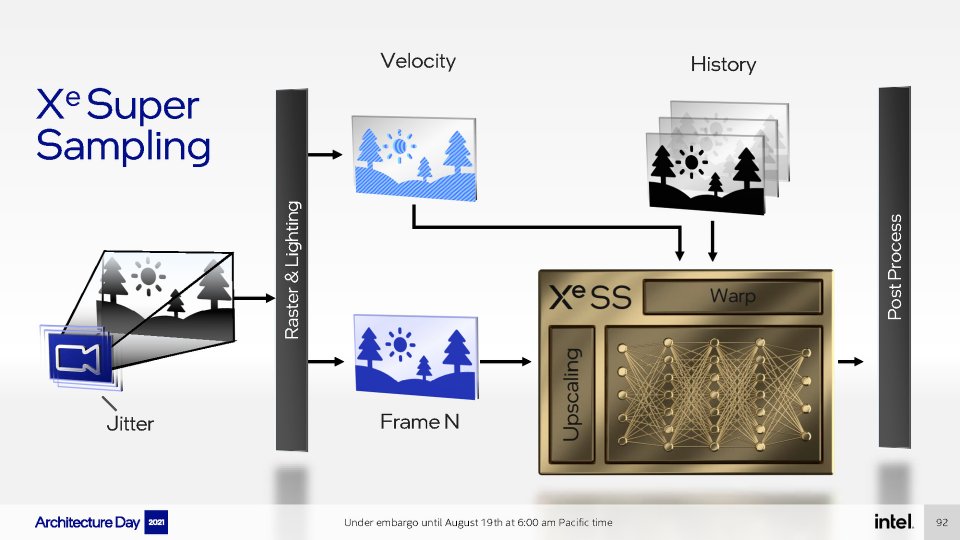
Auf dem Architecture Day 2021 plauderte Intel nicht nur über neue Hard-, sondern auch über neue Software. Unter den Neuerungen befand sich auch ein Anti-Aliasing-Verfahren, das frappierend an Nvidias Deep Learning Super Sampling erinnert: XeSS, kurz für Xe Super Sampling. In beiden Fällen handelt es sich um fortgeschrittenes Upsampling.
Wir erinnern uns: DLSS macht sich die durch Training gewonnenen Informationen eines Neuronalen Netzwerks zu Nutze, um niedrige Auflösungen bestmöglich hochzurechnen und somit bei guter Qualität die Leistung signifikant zu steigern. DLSS führt nicht nur räumliche Berechnungen durch, sondern vergleicht und verrechnet außerdem die Daten aufeinander folgender Frames, um die temporale Stabilität zu erhöhen. Die Ergebnisse der aktuellen DLSS-2.x-Iterationen sind bemerkenswert und übersteigen die Qualität reiner Spatial-Upscaler, darunter auch AMDs FidelityFX Super Resolution (FSR), deutlich - allerdings besteht aufgrund der höheren Komplexität auch mehr Raum für Fehler.
 Quelle: Intel (Screenshot: PCGH)
Intel Architecture Day 2021 Intel Xe Arc Gaming GPUs Pressdeck Full Presentation 92 1
Quelle: Intel (Screenshot: PCGH)
Intel Architecture Day 2021 Intel Xe Arc Gaming GPUs Pressdeck Full Presentation 92 1
Das hohe Qualitätsniveau sauberer DLSS-Implementierungen scheint auch Intel anzustreben, allerdings mit zwei bemerkenswerten Unterschieden bei der Kompatibilität. Die erste: XeSS wird Open-Source, um die Verbreitung anzufeuern. Das erste Software Development Kit (SDK) soll noch in diesem Monat veröffentlicht werden; Intel spricht von einer "einfach zu integrierenden API". Außerdem soll XeSS auch mit AMD- und Nvidia-Grafikkarten zusammenarbeiten, was die Akzeptanz erfahrungsgemäß signifikant steigen lässt. Selbstverständlich wird der Code auf Xe-HPG-Chips, also die Arc-Grafikkarten, zugeschnitten sein, welche über entsprechende Rechenwerke verfügen: Die Matrix-Multiplikatoren, von Intel XMX genannt, führen die spatiotemporalen Berechnungen bei niedriger Bildschirmauflösung durch, rechnen das Bild auf die Ausgabe-Auflösung hoch und entlasten damit die geplagten FP32-ALUs daneben. Intel spricht von der (bis zu) zweifachen Bildrate auf einem Xe-HPG-Modell.
Ein kleines Ass hat Intel im Ärmel: Bei XMX handelt es sich um eine proprietäre Befehlssatzerweiterung, welche laut aktuellem Kenntnisstand nur auf Xe-/Arc-Grafikkarten verfügbar sein wird. Andere GPUs müssen sich mit dem DP4a-Format begnügen. Es ist daher davon auszugehen, dass Geforce- und Radeon-GPUs prozentual immer etwas weniger profitieren. Theoretisch ließen sich aber zumindest Nvidias Tensor-Kerne in Volta, Turing und Ampere für die XeSS-Berechnungen heranziehen, sofern sich ein Entwickler diese Mühe macht. Offiziell, d. h. von Seiten Intels, ist Derartiges nicht zu erwarten - zumal Stand jetzt unklar ist, ob die Tensor-Kerne mit DP4a umgehen können und ob es vielleicht eine Alternative zu diesem Format (wie FP16) gibt.






Intel hat bereits ein Vergleichs-Video veröffentlicht, welches bedauerlicherweise noch nicht in Ultra HD verfügbar ist. Zu sehen ist eine selbstablaufende Demo auf Basis der Unreal Engine 4. Wie einst bei den ersten DLSS-Demonstrationen zeigt sich auch XeSS von seiner besten Seite. Trotz der Youtube-Kompression sind die qualitativen Unterschiede zwischen 1080p und dem auf Ultra HD hochgerechneten XeSS-Bild deutlich erkennbar. Offenbar wendet XeSS wie FSR und DLSS eine Nachschärfung an, um die subjektive Qualität weiter zu erhöhen. Wir gehen davon aus, dass Entwickler deren Stärke (ebenfalls wie bei DLSS und FSR) stufenweise konfigurieren können.
Intel selbst beschreibt XeSS folgendermaßen:
This XeSS demo in 4K shows high-quality super sampling in action on Xe HPG. XeSS uses deep learning to synthesize images that are very close to the quality of native high-res rendering. This reconstruction is performed by a neural network trained to deliver high performance and great quality. The contents and game levels shown in this demo were created by Rens. Rens is a 3D artist, environment artist and technical art director. He is known for his outstanding photogrammetry techniques and high-end rendering skills, and has worked with top game development studios like DICE, Epic Games and Sony.

 Darüber hinaus würde ich hier gar soweit gehen und behaupten, dass das eher ein Schnellschuss war, um der 2018/19er-Gamerschaft eine Begründung zu liefern, warum Tensor Cores auf Gamer-GPUs sind (und entsprechend "mitbezahlt werden müssen").
Darüber hinaus würde ich hier gar soweit gehen und behaupten, dass das eher ein Schnellschuss war, um der 2018/19er-Gamerschaft eine Begründung zu liefern, warum Tensor Cores auf Gamer-GPUs sind (und entsprechend "mitbezahlt werden müssen").







Und was ich von nvidias BLOBs halte:
[Ins Forum, um diesen Inhalt zu sehen]
Letzteres wird für den höheren Durchsatz verantwortlich sein. Ich schätze mal, dass das vom Prinzip etwa mit AVX vergleichbar ist, wo auch ein deutlich höherer Durchsatz erreicht wird. Die geringere Precision ist in dem Fall ohnehin vernachlässigbar.
Was dagegen wirklich nur mit Marketingfolien vorhanden ist, ist eine Info wie das Netz für DLSS2 überhaupt aussieht.