Core Ultra 400D/400DX: Intels Geheimwaffen gegen Ryzen X3D

Im Desktop-PC lässt Intel auf Core Ultra 200 alias "Arrow Lake" und das im März erschienene "Arrow Lake Refresh" im kommenden Jahr die Core Ultra 400 alias "Nova Lake" folgen. Core Ultra 400D und 400DX sollen dabei gegen Ryzen X3D antreten.
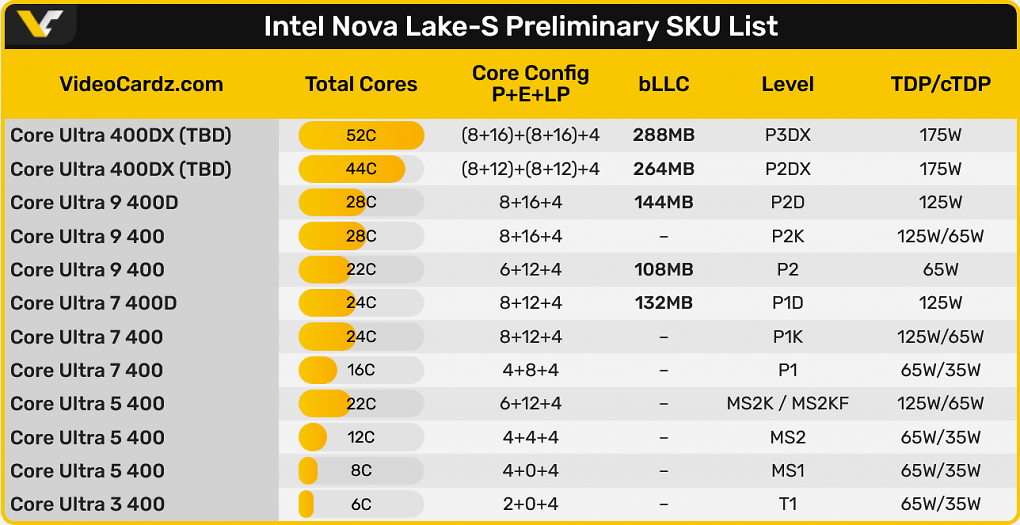
Im Desktop-PC lässt Intel auf die aktuellen Core Ultra 200 ("Arrow Lake-S") und die Core Ultra 200 Plus ("Arrow Lake-S Refresh") voraussichtlich im kommenden Jahr die Core Ultra 400 ("Nova Lake-S") folgen, welche bekanntlich 6 bis 52 Prozessorkerne in dem neuen und langlebigen Sockel LGA-1954 und DDR5-8000 mit ECC als UDIMM, CUDIMM und CSODIMM unterstützen werden. Die Webseite VideoCardz hat entsprechend eigener Angaben im Vorgeld offizielle Dokumente zugespielt bekommen, welche direkt von Intel selbst stammen sollen. Auch die Produktbezeichnung sei jetzt bekannt: Intel Core Ultra Series 4.
Core Ultra 400D und 400DX gegen Ryzen X3D
Wie aus den Veröffentlichungen von @jaykihn0 hervorgeht, sollen die schnellsten Modelle mit 108 bis 288 MiByte bLLC ("Big Last Level Cache") ausgestattet sein, welches als L4-Cache das Pendant zu AMDs 3D V-Cache darstellen soll.
Demzufolge sollen insgesamt fünf Modelle mit zusätzlichem Zwischenspeicher ausgestattet werden, sodass die Single-Die-SKUs wahlweise mit 108, 132 oder gar 144 MiByte bLLC ausgestattet werden könnten, während die beiden Dual-Die-SKUs mit 264 MiByte (2 × 132 MiByte) oder 288 MiByte (2 × 144 MiByte) aufwarten sollen. Für diese speziellen Modelle soll Intel die Suffixe "D" und "DX" hinter die offizielle Modellbezeichnung anhängen und damit AMDs Ryzen X3D angreifen.
Neue Architekturen im neuen Sockel
Während Core Ultra 200 ("Arrow Lake-S") wie Core Ultra 200V ("Lunar Lake") sowohl auf neue P-Cores ("Lion Cove") als auch neue E-Cores ("Skymont") setzen wird, werden die Core Ultra 400 ("Nova Lake-S") abermals neue Performance- und Efficiency-Cores mit neuen Codenamen "Coyote Cove" sowie "Arctic Wolf", einführen. Als Sockel kommt der neue Intel LGA-1954 zum Einsatz, welcher DDR5 mit 8.000 MT/s unterstützen soll, wenn ein Speicherriegel pro Kanal eingesetzt wird.
- Neue Performance-Cores ("Coyote Cove")
- Neue Efficiency-Cores ("Arctic Wolf")
- Neue Neural Processing Unit 6
Auf der Basis von insgesamt fünf unterschiedlichen Die-Varianten und Packages mit 8, 16, 28 (dual), 52 (dual) Prozessorkernen sollen insgesamt 12 Modelle mit Verlustleistungen von 35 bis 175 Watt TDP angeboten werden.
 Quelle: VideoCardz
Egal ob Single- oder Dual-Die, die Intel Core Ultra 400 sollen immer 24 PCIe-Lanes der 5. Generation zur Verfügung stellen und bis zu 2 TB DDR5-8000 verwalten können, welche mittels UDIMM, CUDIMM oder CSODIMM bereitgestellt werden.
Quelle: VideoCardz
Egal ob Single- oder Dual-Die, die Intel Core Ultra 400 sollen immer 24 PCIe-Lanes der 5. Generation zur Verfügung stellen und bis zu 2 TB DDR5-8000 verwalten können, welche mittels UDIMM, CUDIMM oder CSODIMM bereitgestellt werden.
Core Ultra 400DX wohl im HEDT-Segment
Die "gewöhnlichen" Consumer-Varianten reichen dabei von einem Core Ultra 3 4xx mit 6 Prozessorkernen bis zu einem Core Ultra 9 4xxD mit 28 Prozessorkernen. Die beiden Topmodelle mit 44 und 52 Prozessorkernen sollen hingegen voraussichtlich noch einmal gesondert vermarktet und als Core Ultra X9 4xxDX im HEDT-Segment positioniert werden. Die Bezeichnungen sind jedoch noch nicht final.
Neben den klassischen Desktop-CPUs könnte Intel auch erstmals einen mobilen Chip mit einem großen integrierten Xe3p-Grafikprozessor ("IGP") als eine Art Mega-APU im Desktop-Segment anbieten und auf Ryzen AI 500 ("Medusa Point") zielen.
Durch den mit der mobilen Core Ultra Series 3 alias "Panther Lake" eingeführten Aufbau mit seinen zahlreichen Tiles ist Intel bei der Konfiguration der kommenden CPUs sehr flexibel aufgestellt und könnte ein solches Design vergleichsweise "kostengünstig" realisieren. Es ist also davon auszugehen, dass sich das Unternehmen mit Nova Lake deutlich breiter aufstellen möchte.
Ihre Meinung ist gefragt!
Wie stehen Sie zu diesem Thema? Die PCGH-Redaktion freut sich über Ihre fundierte Meinung in den Kommentaren zu dieser Meldung. Um zu kommentieren, müssen Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie bisher noch keinen Account haben, könnten Sie sich hier unverbindlich registrieren. Beachten Sie beim Kommentieren aber bitte die geltenden Forenregeln.
Quelle: @jaykihn0 via VideoCardz









Prefetching macht die CPU selber, Software hat umgekehrt keine direkte Kontrolle über den Cache. (Heißt umgekehrt: Im Cache kann alles mögliche landen, von dem der interne Algorithmus des Herstellers meint, es wäre wert, aufbewahrt zu werden. HUD war nur ein geratenes, aber illustratives Beispiel von mir.) Man kann also nur optimieren, wenn man spezifische Details der Caching-Logik eines konkreten Prozessors kennt. Aber wie schon im parallelen Thread zu Software-Optimierungen geschrieben: Das ist zu fummelig, um jenseits von Konsolen leistungsrelevant zu sein. Man schaue sich den Aufwand an, den Low-Level-Exploits wie Spectre treiben, um kontrollierte Cache-States zu provozieren.
In der Praxis würde maximal eine Anpassung des Codeumfangs erwarten und diese auch weniger zielgerichtet und mehr als Folge. Die gleiche Arbeit mit einem simpleren Programm zu machen, ist prinzipiell immer eine gute Idee und je näher man sich an der Kapazitätsgrenze des Caches bewegt, desto stärker sollten sich kleine Verbesserungen auszahlen. Heißt: Wer die Leistung seines Programms zu steigern versucht, in dem er es entschlackt, wird ganz automatisch von "ein Stück über der Cache-Kapazitätsgrenze" bis "darunter" optimieren, weil er in dem Bereich große Leistungszuwächse sieht, sich bei weiter Arbeit in gleicher Weise dann aber nur noch wenig tut.
Mit "Videoberarbeitung" meinte ich Schnitt und ähnliches, aber keine konkreten Programme, sondern nur allgemein/theoretisch betrachtet. Wer mehrere 100 MiB große Fragmente bearbeitet, arbeitet mit Daten, die nicht mehr cachebar sind. Der Programmcode umgekehrt sollte, den Größen typischer Ausführungsdateien zu Folge, sowieso passen.
De- oder Encoding kann ich schlechter einschätzen. Auf den ersten Blick wirkt es gar nicht cachelastig – die Tools sind winzig und die Nutzdaten werden nur einmal verarbeitet. Es gibt keine zweite Runde, für die man sie vorhalten könnte. Aber mikroskopisch betrachtet arbeiten meinem Wissen nach alle nicht komplett veralteten Codecs Frame temporal, nutzen die Daten eines einzelnen Bildes also jeweils für die Bearbeitung der folgenden. 24 MiB für einen komplett dekomprimierten UHD-Frame liegen durchaus in V-Cache-Größenordnung. Auf der anderen Seite sind diese Zugriffsmuster natürlich extrem vorhersehbar, Heimspiel für Prefetcher also, und je moderner der Codec, desto komplexer wird die Querverrechnung und desto eher limitieren die Compute-Pipelines. Was in der Summe rauskommt, kann ich nicht abschätzen und habe es auch nie vergleichend gebenched.
Glaube mal viel hole ich da einfach nicht mehr raus. Es wird auch nur noch minimal kleiner aber der Aufwand ist zu hoch. Ich lasse es lieber wie es ist.
Hab mich generell auch versucht zurückzuhalten, denn das ist schon ziemlich Off-Topic hier.^^
Ich schick dir 'ne PN.
Solltest du, wie ich, weiter mit x264 encoden, ist das nicht verwunderlich und du hättest dich vor dem CPU Kauf vllt. mehr informieren sollen.
x264 skaliert nicht gut mit mehr als 16 Threads. Einerseits hast du mehrere Typen von Frames und die sind teils untereinander abhängig, sodass man nicht endlos skalieren kann, andererseits hab ich zmd. gelesen, dass bei mehr als 16 Threads die Qualität auch abnehmen kann. Das ist auch einer der Gründe weshalb ich mich damals nicht für eine höhere CPU Klasse als den 3700X entschieden hab.
Ich lass x264 (aktuell) die 'interne' Anzahl an Threads selbst bestimmen und lande bei meinen meisten Encodes bei 22-24 Threads (1,5x). Bei Encodes in niedrigerer Auflösung (<= 720p) und/oder mit simpleren Settings (medium Preset) lande ich auch mal bei nur 18 Threads.
Du kannst zwar manuell den Threadcount über "--threads=X" festlegen (weiß nicht ob in XMedia Recode), aber würde ich persönlich nicht machen, höher zu gehen..
Ah, ok, hast das auch schon raus.^^ Naja, machst aber mehr Nutzen aus deiner CPU und bekommst eine bessere Qualität (je nachdem wo du aktuell mit den Einstellungen stehst..).
Große Firmen nutzen zwar durchaus andere Encoder, als das was uns zur Verfügung steht, aber natürlich hab ich da keine Ahnung, inwiefern die besser skalieren.
Ich bin auf das eine Programm xmedia recode als 32 bit gebunden. Es macht unter Windows 11 nur Probleme . Man kann einstellen was man will ,es vergisst die selbst aktiven Sitzung eingestellte Sachen. Unter Windows 10 habe ich das Problem noch nie gehabt. Zuverlässig arbeitet es eben also nicht unter Windows 11.
Außerdem bin ich immer noch unter Win 10 unterwegs, also kann ich mit Win 11 auch nicht weiterhelfen.. :|
Tya schaue so nicht so aus als ob es viel wäre. Das heißt auf gut deutsch 13 Kerne ackern voll und 3 Kerne der Zeit schlafen vor sich hin.
Solltest du, wie ich, weiter mit x264 encoden, ist das nicht verwunderlich und du hättest dich vor dem CPU Kauf vllt. mehr informieren sollen.
x264 skaliert nicht gut mit mehr als 16 Threads. Einerseits hast du mehrere Typen von Frames und die sind teils untereinander abhängig, sodass man nicht endlos skalieren kann, andererseits hab ich zmd. gelesen, dass bei mehr als 16 Threads die Qualität auch abnehmen kann. Das ist auch einer der Gründe weshalb ich mich damals nicht für eine höhere CPU Klasse als den 3700X entschieden hab.
Ich lass x264 (aktuell) die 'interne' Anzahl an Threads selbst bestimmen und lande bei meinen meisten Encodes bei 22-24 Threads (1,5x). Bei Encodes in niedrigerer Auflösung (<= 720p) und/oder mit simpleren Settings (medium Preset) lande ich auch mal bei nur 18 Threads.
Wenn du die 18 Threads auch bei FHD bekommst, grätscht entweder XMedia Recode dazwischen oder du nutzt ein niedriges Preset - höhere Presets skalieren mit der Leistung besser, probier mal "slower".
Du kannst zwar manuell den Threadcount über "--threads=X" festlegen (weiß nicht ob in XMedia Recode), aber würde ich persönlich nicht machen, höher zu gehen..
Mit x265 hab ich deutlich weniger Erfahrung und Wissen. Vllt. Da mal selbst recherchieren bzgl. Der Skalierung.
Große Firmen nutzen zwar durchaus andere Encoder, als das was uns zur Verfügung steht, aber natürlich hab ich da keine Ahnung, inwiefern die besser skalieren.
Ich verwende einen 265k. Ich gebe Vollgas. Zwei gleich starke Anwendung gleichzeitig und zwar auf p und e Kerne . Das dann die e Kerne schlapp machen sagte mir auch einer. Die e Kerne sind keine Power Kerne. Und darum fallen die auch bei der Leistung zurück. Aber genau das fordere ich sie .ich tue ihnen alles abverlangen was geht. Aber nun Stelle ich fest ,ich kriege diese nicht mehr schneller hin. Ich stecke in der Sackgasse. Die CPU bei den e Kernen völlig überfordert aber ich verlange nach mehr. Die Wattanzeige die steigt nach oben ,bei stärkeren CPUs sogar so weit das sie sogar drosseln. Würde ich da nun mit Luft hantiert würde es gameover heißen. Sogar der 285k landete bei einem auf 90 Grad. Also kurz vor der Drossel Grenze. Mehr scheint wirklich nicht zu gehen. Würde ich auf Takt noch bestehen ,dann würde wohl auch die wasseekühlung schlapp machen. Alles nur um die e Kerne mehr zu Puschen . Aber genau damit würde ich der CPU wirklich erschlagen. Ich habe wohl gedacht die e Kerne könnten echte Last auch vertragen. Naja hinter her wohl doch schlauer geworden. Wird das etwa beim Nachfolger auch wieder so Enten e Kerne geben ?