Nvidia GA100 (Ampere): Die Spezifikationen des Next-Gen-Rechenmonsters [Update]
Jetzt aktualisiert: Nvidia hat seine nächste GPU-Generation Ampere in Form des A100 mit technischen Details vorgestellt. Wie erwartet ist der Volta-Nachfolger in fast jeder Disziplin ein Gigant. PCGH fasst zusammen, welche Eckdaten bisher bekannt sind. Und ob man darauf Rückschlüsse ziehen kann, wie die Geforce-Varianten von Ampere aussehen könnten.

Aktualisierung vom 15. Mai
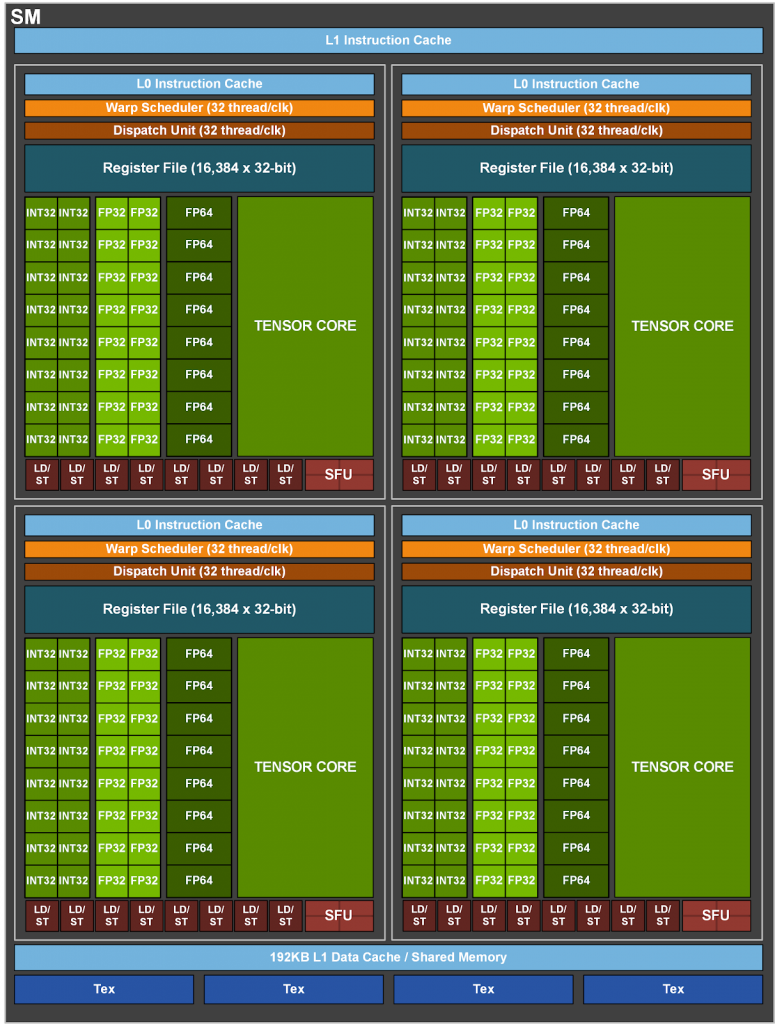
Mittlerweile ist nicht nur das Blockdiagramm des Ampere GA100 verfügbar, sondern auch das Innenleben des Shader-Multiprozessors. Nvidia erläutert die Architektur in seinem Developer Blog. Wir haben diesen Artikel entsprechend aktualisiert. Die interessanteste Information betrifft das Raytracing: GA100 beherbergt keinerlei RT-Cores. Diese fehlen folglich bewusst im schematischen SM-Aufbau. Realtime-Raytracing ist - wie beim Volta GV100 - zwar dennoch möglich, allerdings nicht mit maximaler Leistung. Diesen Missstand aus Spielersicht werden die Gaming-Amperes richten, welche zu einem späteren Zeitpunkt präsentiert werden.
Falls es weitere Neuigkeiten gibt, erfahren Sie es selbstverständlich zeitnah bei uns. Man munkelt, dass es in Kürze weitere Informationen seitens Nvidia im Rahmen eines Technik-Tauchgangs (Deep Dive) geben wird.
Original-Artikel vom 14. Mai
Die Gerüchteküche sollte Recht behalten: Nvidias neueste GPU-Generation hört auf den Codenamen Ampere und wird in 7 Nanometer Strukturbreite bei der Foundry TSMC gefertigt. Der neue Chip ist erwartungsgemäß ein wahres Rechenmonster und bringt stattliche 54 Milliarden Schaltungen auf 826 mm² Kernfläche unter. PCGH fasst die bisher bekannten Informationen zusammen.
Der GA100 für HPC-Systeme ist abgespeckt
Wie bereits der Volta GV100 startet auch Ampere als Produkt für Datenzentren, welche traditionell schier unendliche Mengen an Rechenleistung benötigen. Hier muss direkt zwischen Prozessor und Produkt unterschieden werden: Die GPU hört auf den Namen GA100, die HPC-Lösung jedoch auf die Bezeichnung A100. Egal, welches Datenformat, der Ampere GA100 bringt eine Reihe an Neuerungen mit, um seinen Vorgänger teilweise um den Faktor 20 zu schlagen. Erreicht wird dies vor allem durch die Verbesserung der spezialisierten Tensorkerne, welche bei entsprechender Programmierung um Größenordnungen schneller arbeiten als die auch bei Spielen herangezogenen FP-ALUs (Stream-Prozessoren). Wir haben die bisher bekannten Informationen zum A100 für HPC-Systeme zusammengefasst und den Vorgängern sowie Gaming-Geforces gegenübergestellt.
| Modell | Tesla A100 (SXM) | Tesla V100 (SXM) | Tesla P100 (SXM) | Titan RTX (PCIe) | Titan V (PCIe) | Titan Xp (PCIe) |
|---|---|---|---|---|---|---|
| GPU | Ampere GA100 | Volta GV100 | Pascal GP100 | Turing TU102-400 | Volta GV100 | Pascal GP102-400 |
| Fertigung | 7 nm TSMC (N7) | 12 nm TSMC | 16 nm TSMC | 12 nm TSMC | 12 nm TSMC | 16 nm TSMC |
| Chipgröße (reiner Die) | 826 mm² | 815 mm² | 610 mm² | 754 mm² | 815 mm² | 471 mm² |
| Transistoren Grafikchip (Mio.) | 54.200 | 21.100 | 15.300 | 18.600 | 21.100 | 12.000 |
| FP32-ALUs-/SIMDs/TMUs | 6.912/108/432 | 5.120/80/320 | 3.584/56/224 | 4.608/72/288 | 5.120/80/320 | 3.840/30/240 |
| Dedizierte INT32-Einheiten | 6.912 | 5.120 | - | 4.608 | 5.120 | - |
| Tensor Cores (TC) | 432 | 640 | - | 576 | 640 | - |
| Raytracing Cores (RT) | - | - | - | 72 | - | - |
| Raster-Endstufen (ROPs) | Unbekannt | Unbekannt | 96 | 96 | 96 | 96 |
| GPU-Basistakt (MHz) | Unbekannt | Unbekannt | 1.328 | 1.350 | 1.200 | 1.480 |
| GPU-Boost-Takt (MHz) | 1.410 | 1.530 | 1.480 | 1.770 | 1.455 | 1.582 |
| Rechenleistung INT8 (TOPS)* | 624 | 125 | 21,2 | 261 | 119 | 12,2 |
| Rechenleistung FP16 (TFLOPS)* | 312 | 170 | 21,2 | 32,6 | 161 | 12,2 |
| Rechenleistung FP32 (TFLOPS) | 19,5 | 15,7 | 10,6 | 16,3 | 14,9 | 12,2 |
| Rechenleistung FP64 (TFLOPS)* | 19,5 | 7,45 | 5,30 | 0,51 | 7,45 | 0,38 |
| Speicheranbindung (Bit) | 5.120 | 4.096 | 4.096 | 384 | 3.072 | 384 |
| Speicherstandard | HBM gen2 | HBM gen2 | HBM gen2 | GDDR6 | HBM gen2 | GDDR5X |
| Geschw. Grafikspeicher (GT/s) | 2,45 | 1,75 | 1,45 | 14,0 | 1,70 | 11,4 |
| Übliche Speichermenge (GiB) | 40 | 32 | 16 | 24 | 12 | 12 |
| Speicherübertragung (GB/s) | 1.550 | 900 | 732 | 672 | 653 | 548 |
| TDP (Watt) | 400 | 300 | 300 | 280 | 250 | 250 |
| PCI-Express-Standard | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| Stromanschlüsse | - | - | - | 2 × 8-polig | je 1 × 6-/8-polig | je 1 × 6-/8-polig |
*Durchsatzwerte bei Berechnung über die Tensorkerne, welche um Faktoren schneller arbeiten als die FP-ALUs. Angaben ohne "Sparsity".
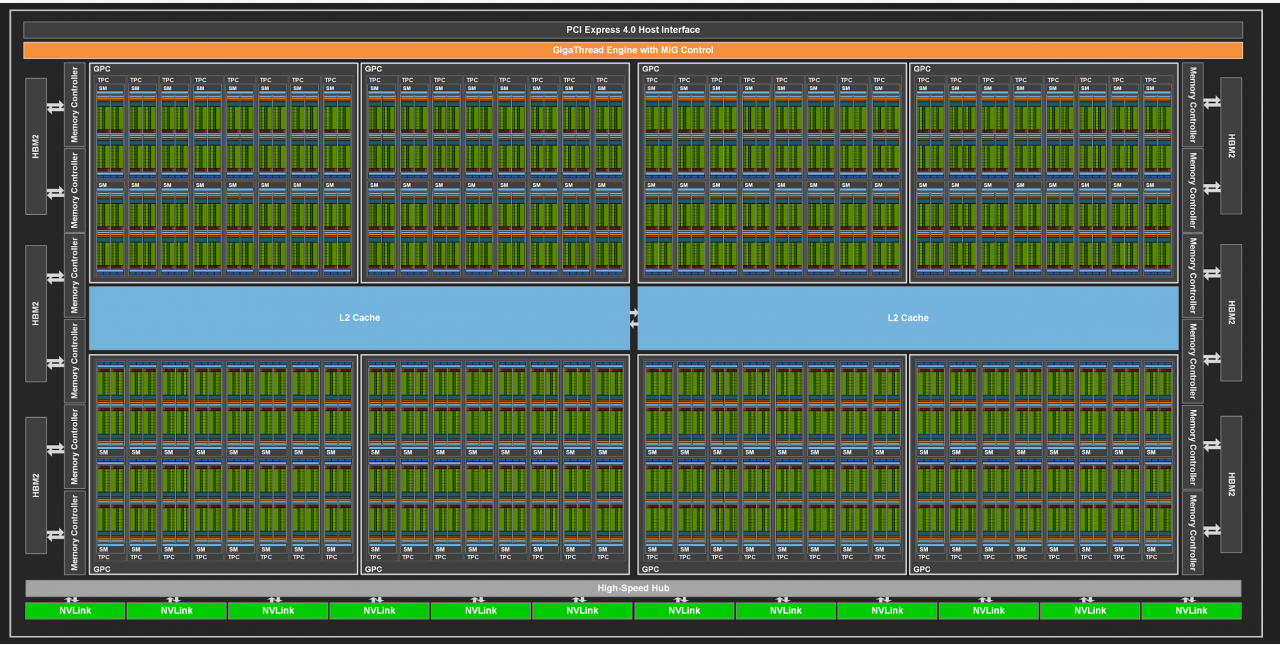
GA100 beherbergt 128 SMs (Update)
Die HPC-Lösung Tesla A100, welche Nvidia explizit "Tensor Core GPU" nennt, schöpft die Möglichkeiten des GA100 nicht ansatzweise aus, vermutlich aufgrund einer noch nicht vollständig ausgereiften Fertigung. Insgesamt beherbergt der GA100 satte 128 Shader-Multiprozessoren mit insgesamt 8.192 Stream-Prozessoren (FP32-ALUs), im A100 sind folglich 20 SMs bzw. 1.280 SPs deaktiviert.
Mittlerweile hat Nvidia auch das Basismodul eines jeden Grafikchips, den Shader-Multiprocessor (SM), grafisch visualisiert. Dabei bestätigt sich eine Vermutung: GA100 beherbergt keinerlei Raytracing-Kerne, welche die Strahlenverfolgung im virtuellen Raum übernehmen. Dafür ist ein SMA (Shader Multiprocessor Ampere) vollgestopft mit Arithmetisch-Logischen Einheiten. Wie erwartet stecken 64 FP32-ALUs, 64 INT32-ALUs sowie 32 FP64-ALUs in jedem SM. Flächenmäßig, so suggeriert es die Grafik, wird jedoch alles von einem "Uber Tensor Core" überschattet - angesichts der Auslegung des A100 als HPC-Beschleuniger ist das nicht verwunderlich.
Bevor Missverständnisse aufkommen: Auch wenn der GA100 als SXM-Lösung ohne Display-Ausgänge startet, handelt es sich doch um einen vollwertigen Grafikchip. Dies ist unter anderem daran ersichtlich, dass jeder SM wie gehabt über eine Quad-TMU für Texturoperationen verfügt. Das ist ein wichtiger Punkt, denn es gibt durchaus Bestrebungen, als Platzgründen althergebrachte Einheiten wie TMUs zu Gunsten anderer Rechenwerke wegzulassen. AMDs durch das Netz geisterndem HPC-Monster "Arcturus" wird genau das nachgesagt.
40 bis 48 GiByte Speicher
Der HPC-Beschleuniger A100 verfügt laut Nvidia über 40 GiByte High Bandwidth Memory zweiter Generation (HBM gen2), angebunden an ein 5.120-Bit-Interface. Aufmerksame Beobachter stellen fest, dass das nicht zum Bild passt, das eindeutig sechs HBM-Stapel zeigt, welche 6 × 1.024 = 6.144 Bit suggerieren. Derzeit ist unbekannt, ob es sich beim sechsten Stack um einen Dummy handelt und warum Nvidia diesen Schritt geht. Aus den fünf HBM-Stapeln ergibt sich eine Transferrate von rund 1,55 Terabyte pro Sekunde - 50 Prozent mehr als beim bisherigen Spitzenreiter Vega 20. Die Taktraten werden nicht genannt, rechnerisch arbeiten die HBM-Stacks jedoch mit circa 2,45 GT/s. Theoretisch und bei zukünftigen Produkten mit vollständig aktivem GA100 stehen bei gleichem Takt 1,9 TByte/s sowie 48 GiByte Kapazität bereit.
Flexible Tensor Cores 3.0
Ampere bringt die dritte Generation der Tensor-Kerne mit, welche TF32 (Tensor Float) unterstützen. Einfach ausgedrückt soll hier ohne zu großen Performance-Verlusten bei den bevorzugten FP16-KI-Berechnungen die Genauigkeit erhöht werden. Und das auch ohne eine Änderung der gewohnten Vorgehensweise. Nvidia erreicht das mit einem 10-Bit-Mantissa (dekadischer Logarithmus) und einem 8-Bit-Exponenten. Außerdem beherrschen die Tensor-Kerne nun auch FP64-Genauigkeit, was die Leistung im HPC-Bereich verdoppeln kann. Das Thema für KI-Berechnungen wird dann wohl auch in die RTX-Karten für Spieler durchschlagen, wo die Tensor-Kerne schon bei Turing vorhanden sind und mit denen unter anderem DLSS realisiert wird. Ob die höhere Leistung bei doppelter Präzision auch für Spieler kommt und da auch was bringt, werden wir sehen. Weitere Neuerungen sind Multi-Instance GPU (MIG), das mehrere Anwendungen gleichzeitig auf einer GPU erlaubt, und Sparsity, ein Phänomen aus neuralen Netzwerken.
Gaming-Ampere: Ausblick (Update)
Falls Sie sich zu Recht fragen, wo die News für Spieler bleiben: Diesbezüglich hält sich Nvidia noch bedeckt, auch wenn es zahlreiche mehr oder minder glaubhafte Leaks gibt. Vorerst gibt es den A100-Beschleuniger nur als 400 Watt starkes SXModul ("Mezzanine"), nicht als PCI-Express-Steckkarte. Die Gaming-Chips werden mit Gewissheit andere Schwerpunkte setzen, denn unter anderem FP64 alias Double Precision ist bei Spielen kein Thema. Hier dreht sich alles um FP32-Leistung, welche beim Blick ins A100-Datenblatt etwas mager ausfällt. Hier stehen 19,5 TFLOPS bereit, denn nach aktuellem Kenntnisstand lässt sich die Arbeit in Spielen nicht auf die bei FP32 doppelt so schnellen Tensorkerne auslagern.
Wäre die A100 eine PCI-Express-Steckkarte im Stile einer "Titan A", böte sie auf dem Papier "nur" +20 Prozent Leistung gegenüber einer Titan RTX. Treibt man Letztere mithilfe sehr starker (Wasser-)Kühlung auf gut 2,1 GHz, erreicht sie diese Rechenleistung, während eine Geforce RTX 2080 Ti knapp daran scheitert. Bei Volta ließ sich Nvidia dazu hinreißen, für seine besonders gut betuchten Enthusiasten eine entsprechende Titan-Grafikkarte aufzulegen. Diese erschien viele Monate vor dem Start des RTX-Rummels, sodass das Sinn ergab. Eine Titan A auf GA100-Basis ohne dedizierte Raytracing-Kerne halten wir zwar für unwahrscheinlich, ausgeschlossen ist sie jedoch nicht. Auch wenn es nicht den Anschein macht, beim Echtzeit-Raytracing ist "traditionelle" Shader-Leistung nach wie vor der wichtigste Faktor. Ampere kann hier dank der schieren Menge an Rechenwerken punkten, wie es Volta ebenfalls tut. Rekonstruktionstechniken wie DLSS 2.0 entspannen die Lage weiter. Es bleibt spannend!
Bildergalerie
Bildergalerie
Die besten Grafikkarten finden Sie auch in unserem PCGH-Ratgeber Grafikkarten.









pcgh benches eignen sich nicht für ob spiele spielbar sind nur um die relative hardware performance zu ermitteln. kuck youtube einfach gameplays die 2060 s ist kaum schneller als eine 1080
https://www.pcgameshardwa...