GTC 2013: Raytracing im Video, Wegfindung in Deutschland, Simulationen für die Armee und mehr
Nvidias Hausmesse, die GPU Technology Conference 2013, ist kurz davor, offiziell von Nvidia-Chef Jen-Hsun Huang eröffnet zu werden. Doch bereits am Messevortag gab es einige spannende Dinge zu sehen, die wir in dieser Meldung für Sie zusammenfassen.
 GTC 2013 Nvidia Optix Raytracing 17
Derzeit findet im kalifornischen San Jose die GPU Technology Conference – kurz GTC – statt. PC Games Hardware ist natürlich vor Ort und berichtet von der Grafikkarten- und Technik-Hausmesse, die Nvidia veranstaltet. Neben GPUs, Supercomputing, Visualierung, Film- und Videoproduktion und Anwendungen aus Wissenschaft und Technik finde erstmals Vortragsreihen zu den Themen Gaming und Entertainment sowie Automotive Entertainment statt.
GTC 2013 Nvidia Optix Raytracing 17
Derzeit findet im kalifornischen San Jose die GPU Technology Conference – kurz GTC – statt. PC Games Hardware ist natürlich vor Ort und berichtet von der Grafikkarten- und Technik-Hausmesse, die Nvidia veranstaltet. Neben GPUs, Supercomputing, Visualierung, Film- und Videoproduktion und Anwendungen aus Wissenschaft und Technik finde erstmals Vortragsreihen zu den Themen Gaming und Entertainment sowie Automotive Entertainment statt.
Bereits am Tag vor der Eröffnungsrede Huangs gab es einige spannende Tutorials und Einführungen für die anwesenden Entwickler. Zudem haben wir uns für Sie auf der sogenannten Poster-Session umgeschaut, wo Studenten von verschiedenen Universitäten weltweit ihre Forschungsprojekte präsentieren können.
 GTC 2013 Nvidia Optix Raytracing 01
GTC 2013 Nvidia Optix Raytracing 01
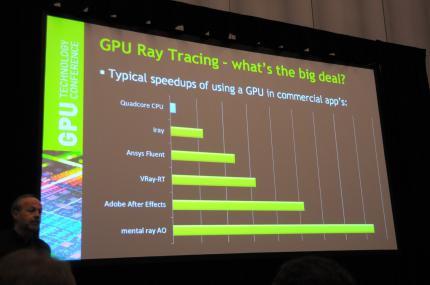
Einführung in Nvidias Optix Ray Tracing Engine
Bereits bekannt ist Nvidias Optix Ray-Tracer, welcher natürlich innerhalb der hauseigenen Cuda-Umgebung arbeitet. Die aktuelle Version 3 kann neben 64-Bit-Technik für PTX auch mit Out-of-Core-Speicherverwaltung für besonders große Datensets glänzen und bietet Optimierungen für die aktuelle Kepler-Architektur.
Nvidia zeigte in Gestalt des Redners Phillipp Miller, Director of Product Management Nvidia Advanced Rendering Solutions, Optix 3 Raytracing in Verbindung mit GPU-Physx. Die Demo nutzt eine Maximus-2-Konfiguration mit einer Quadro-Karte für die grapische Darstellung und zweiTesla-K20 für die Berechnungen. Das Wasser wird dank Raytracing übrigens ohne die klassischen, bei Rastergrafik quasi unumgänglichen Polygonstrukturen dargestellt und ist folglich extrem detailliert.
Die Poster-Session
Drei spannende oder spaßige Projekte haben wir uns etwas näher angeschaut - für die restlichen verweisen wir auf die Bilder in der Galerie.
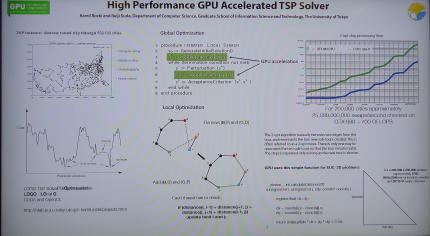 GTC 2013 Poster Session Travelling Salesman Problem
Das Travelling-Salesman-Problem, kurz TSP, ist Teil des Wegfindungs- und Routing-Komplexes. Wir haben uns auf der GTC 2013 die Lösung von Rocki und Suda anhand einer Deutschlandkarte mit 13.000 Städten vorführen lassen, welche neben einer naiven Single-Core-CPU-Implementierung auch einen Cuda-Pfad und eine OpenCL-Variante bietet - letztere nutzt im CPU-Teil auch Multithreading und Autovektorisierung auf dem verwendeten Core i7-3930K, ein fairer Vergleich ist ergo gegeben. Spannend: Die Cuda-Implementierung ist dem OpenCL-Pendant deutlich überlegen - wir konnten zwischen 40 und 60 Prozent Vorsprung sehen. Das untermauert aufs neue, dass die Treiberprogrammierer bei Nvidia eindeutige Vorgaben bezüglich der Prioritätensetzung haben. Während der Namenspatron nur die kürzeste Reiseroute auf seiner Strecke finden muss, wird der zu Grunde liegende Algorithmus auch beim Routing von Leitungen auf Chips, der Kristallografie, im Verkehrswesen oder in der Robotersteuerung genutzt.
GTC 2013 Poster Session Travelling Salesman Problem
Das Travelling-Salesman-Problem, kurz TSP, ist Teil des Wegfindungs- und Routing-Komplexes. Wir haben uns auf der GTC 2013 die Lösung von Rocki und Suda anhand einer Deutschlandkarte mit 13.000 Städten vorführen lassen, welche neben einer naiven Single-Core-CPU-Implementierung auch einen Cuda-Pfad und eine OpenCL-Variante bietet - letztere nutzt im CPU-Teil auch Multithreading und Autovektorisierung auf dem verwendeten Core i7-3930K, ein fairer Vergleich ist ergo gegeben. Spannend: Die Cuda-Implementierung ist dem OpenCL-Pendant deutlich überlegen - wir konnten zwischen 40 und 60 Prozent Vorsprung sehen. Das untermauert aufs neue, dass die Treiberprogrammierer bei Nvidia eindeutige Vorgaben bezüglich der Prioritätensetzung haben. Während der Namenspatron nur die kürzeste Reiseroute auf seiner Strecke finden muss, wird der zu Grunde liegende Algorithmus auch beim Routing von Leitungen auf Chips, der Kristallografie, im Verkehrswesen oder in der Robotersteuerung genutzt.
Interessant ist auch der Ansatz von Ethan Kerzner. Der Doktorand der Universität Iowa entwickelt eine Visualisierungs- und Simulationslösung für die US Army, welche anhand von Materialdicke und -eigenschaften die Panzerung von Fahrzeugen (V/L-Analysis, Vulnerability/Lethality) analysieren kann. Dafür nutzt er das bereits bekannte Order Independent Transparency mit einer speziellen Optimierung namens PALL (Primitive Allocated Linked Lists) anstelle der bekannten Per-Pixel Linked Lists (PPLL). Er ordnet jedem Primitive, also der geometrischen Grundeinheit, einen festen Speicherbereich zu, in dem die Linked-Lists aufgetragen werden. Zwar muss dafür erst einmal errechnet werden, wieviele Pixel jedes Primitiv bedeckt, dafür sind danach aber unfragmentierte Speicherbereiche vorhanden, welche das Gerangel (Contention) um die Speicherzugriffe (Atomics) deutlich reduzieren und in einer mit steigender Auflösung immer besseren Performance münden als die etablierte Methode - und das, obwohl Kerzner und seine Partner sogar noch auf die schnellste Methode, Atomic Adds, unter OpenGL verzichten müssen.
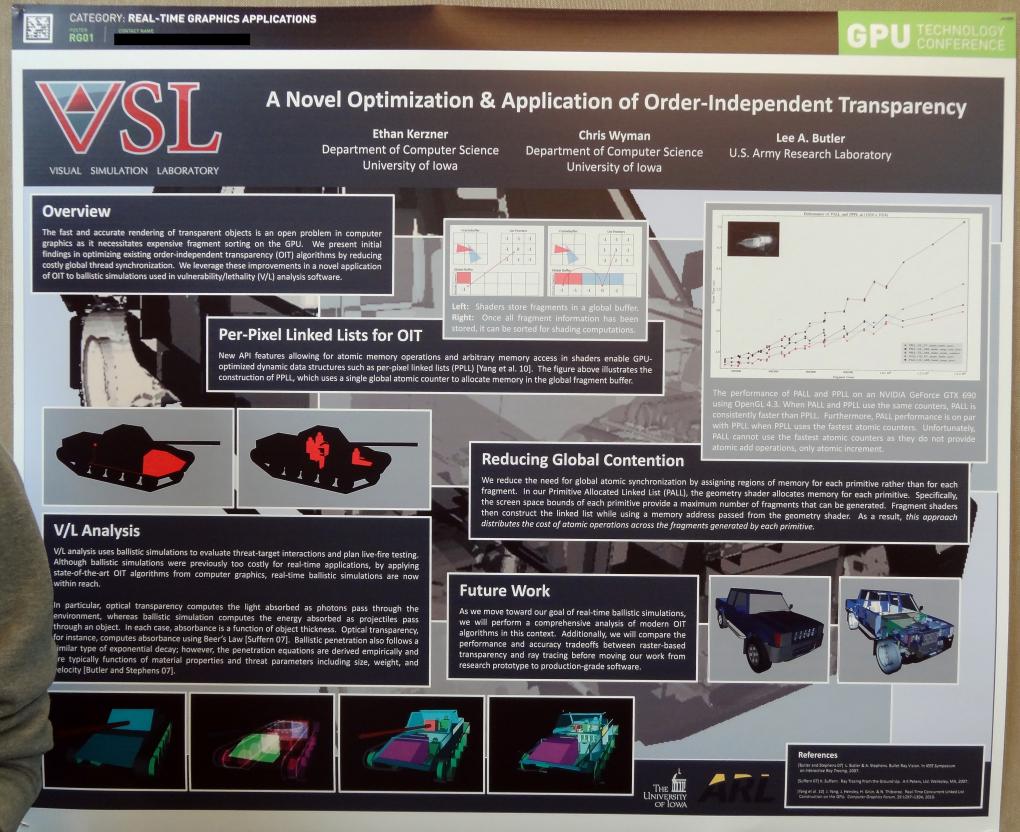 GTC 2013 Poster Session Order Independent Transparency
GTC 2013 Poster Session Order Independent Transparency
Was OIT mit V/L-Simulationen zu tun hat? Ganz einfach. Anstelle der optischen Transparenz kann im Algorithmus auch ein beliebiges Material parametrisch dargestellt werden.
 GTC 2013 Poster Session Rubik sCube
Zum Schluss noch etwas Kurioses: Studenten der Universität für Elektro-Kommunikation (UEC) in Japan haben sich der parallelisierten Lösung von Rubics Zauberwürfel angenommen. Dank klugen Speichermanagements in ihrer Baumstruktur erreichen sie selbst mit einer Geforce GTX 570 dabei noch die sechsfache Performance eines Core i5-3570K.
GTC 2013 Poster Session Rubik sCube
Zum Schluss noch etwas Kurioses: Studenten der Universität für Elektro-Kommunikation (UEC) in Japan haben sich der parallelisierten Lösung von Rubics Zauberwürfel angenommen. Dank klugen Speichermanagements in ihrer Baumstruktur erreichen sie selbst mit einer Geforce GTX 570 dabei noch die sechsfache Performance eines Core i5-3570K.









Ja, ist schon richtig. Cuda ist halt für Nvidia die dominante Plattform, über die sie die Kontrolle haben, in die sie seit nunmehr acht Jahren investieren. Da ist es mMn schon verständlich, das man die eigene Lösung pusht - zumal man darin auch bei den neuen Karten mehr Möglichkeiten hat als es im sich eher langsam weiterentwickelnden OpenCL der Fall ist.
Es ist aber auch ein bißchen eine Frage des Marktes: Wäre die Konkurrenz stark genug, würde es sich für die Softwareanbieter nicht mehr lohnen, nur auf Nvidia zu setzen und Nvidia wiederum gezwungen, OpenCL besser zu unterstützen. Aber da hat AMD eben die ersten Jahre selbst auf eine proprietäre Lösung gesetzt, bevor man begann, für OpenCL zu trommeln. Bis das nun wirkt, dauert es eben.
Klingt alles toll, aber vieles davon wieder nur in CUDA umgesetzt. Und da war ja etwas - ach ja, die allgemeine OpenCL-Schwäche bei Geforce-Grafikkarten. (kein Wunder, dass da der CUDA-Pfad schneller ist & ganz besonders wenn das alles aus dem eigenen Haus kommt) Es ist also manches nur für Unternehmen interessant, die von sich aus, nur auf eine Plattform setzen werden/wollen.