"Huangsches Gesetz": Nvidia gibt Ausblicke auf die Post-Moore-Ära

Das Mooresche Gesetz ist tot, lang lebe das Huangsche Gesetz: In einem Nvidia-Vortrag zur Hot-Chips-Konferenz 2023 geht das Unternehmen näher auf die Zukunft der Chipentwicklung ein.
In den vergangenen Jahren wurde das Mooresche Gesetz von verschiedenen Unternehmen immer wieder für verlangsamt, nicht mehr gültig, tot oder lebendig erklärt. Für Grafikkarten-Hersteller Nvidia ist die Sachlage eindeutig: Die Halbleiter-Industrie "ist fast am Limit", verkündete Jensen Huang bereits im Oktober 2022. Als in gewissem Sinne Nachfolger steht das nach dem Nvidia-CEO benannte "Huangsche Gesetz" bereit, welches im Rahmen der Hot-Chips-Konferenz 2023 von Nvidias Chief Scientist Bill Dally näher erläutert wurde.
Die "tektonische Verschiebung in der Art und Weise, wie Computerleistung in einer Post-Moore's Law-Ära bereitgestellt wird", äußert sich beim Huangschen Gesetz als eher ungenaue Angabe. Hiermit ist simplifiziert gemeint, dass die Entwicklungsfortschritte bei Grafikprozessoren schlicht schneller voranschreitet als bei den im Mooreschen Gesetz angeführten integrierten Schaltkreisen; Moore konkretisierte aber immerhin, dass sich die Anzahl der Transistoren verdoppeln würde.
Das Huangsche Gesetz hingegen basiert auf "menschlichem Einfallsreichtum", der sich nur bedingt vorhersagen lässt. Immerhin scheinen diese Einfälle ordentlich Früchte zu tragen, denn wie Hally in einer Präsentationsfolie anmerkt, hat sich die GPU-KI-Inferenzleistung in den vergangenen Jahren um den Faktor 1.000 vergrößert.
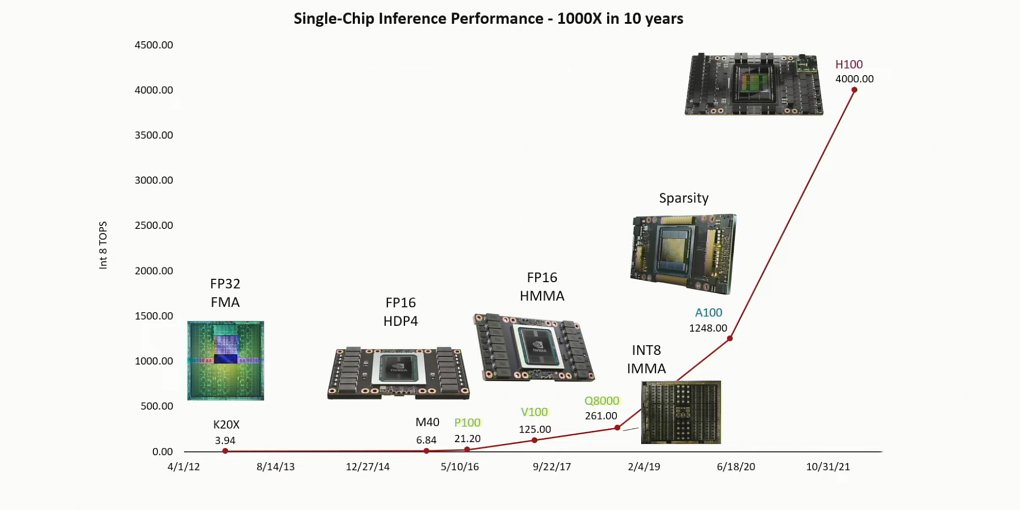 Quelle: Nvidia
"Huangsches Gesetz": Nvidia gibt Ausblicke auf die Post-Moore-Ära (1)
Dieser Performanceschub stehe in krassem Gegensatz zu den Leistungssprüngen, die in diesem Zeitraum mittels Prozessverbesserungen erreicht wurden, wie Hally erklärt. Die Nvidia-GPUs, deren Chips in diesen zehn Jahren von Keplers 28 nm (GTX 700) auf die heutige Ada-Lovelace-Strukturbreite von 5 nm (RTX 4000) geschrumpft sind, hätten hier nur mit einem 2,5-fachen Faktor zum Leistungsgewinn beigetragen.
Quelle: Nvidia
"Huangsches Gesetz": Nvidia gibt Ausblicke auf die Post-Moore-Ära (1)
Dieser Performanceschub stehe in krassem Gegensatz zu den Leistungssprüngen, die in diesem Zeitraum mittels Prozessverbesserungen erreicht wurden, wie Hally erklärt. Die Nvidia-GPUs, deren Chips in diesen zehn Jahren von Keplers 28 nm (GTX 700) auf die heutige Ada-Lovelace-Strukturbreite von 5 nm (RTX 4000) geschrumpft sind, hätten hier nur mit einem 2,5-fachen Faktor zum Leistungsgewinn beigetragen.
Das Ende der Fahnenstange des Huangschen Gesetzes ist für Nvidia anders als beim Moore-Äquivalent noch nicht erreicht: Dally verspricht, dass mehrere Möglichkeiten zur Beschleunigung der KI-Inferenzverarbeitung existieren. Hierzu zähle etwa die Entwicklung "besserer" Speicherschaltung, effizienteren KI-Modellen oder eine weitere Vereinfachung der Zahlendarstellung.
Quelle: Nvidia via Tom's Hardware









n31
tsmc 5nm 17000$ 300mmm² DIE Preis 90-123$
tsmc 6nm 9000$ 6 mcd ~240mm² 38$
packaging 5$ = 167$
ad103 379mm²
178$
ad102
193$-348$
Ein ad102 kostet vollwertig 400$
Der cut nur 205$
amd mcm n31 liegt bei etwa 150$
amd hatte aber geplant nvidia high end anzugreifen bis man den Fehler entdeckt hatte und schnell Schadensbegrenzung machen musste.
Vielleicht hab ich da einen Denkfehler, aber ich bin jetzt einfach vom Die-Size ausgegangen. Der AD104 auf einer 4070 Ti soll 294 mm² groß sein. GCD auf dem Navi31 der 7900XT 304.35 mm² plus obendrauf noch MCD. Und der Rest der Karte abseits der GPU ist bei AMD nochmal deutlich komplexer als bei NVIDIA.
Ähnlich sieht es im Vergleich zum AD103 aus.
Es gab mal von einem Twitter-"Leaker" (finds grad nicht) eine BOM, die eine 4080 bei 300$ sah, die 7900XT(X) mindestens 50% teurer. Keine Ahnung, ob das Substanz hatte oder einfach nur spekuliert.
AD102 mag teuerer sein, aber der spielt auch in einer komplett eigenen Liga.
Weniger ungünstig wird es für AMD erst bei den kleineren Karten.
Ein ad102 kostet vollwertig 400$
Der cut nur 205$
amd mcm n31 liegt bei etwa 150$
amd hatte aber geplant nvidia high end anzugreifen bis man den Fehler entdeckt hatte und schnell Schadensbegrenzung machen musste.
Und ist AMD wirklich Konkurrenz? Da kann man Zweifel haben.
Gerade bei den größeren Modellen braucht AMD erheblich größere Chips als NVIDIA für in etwa die gleiche Raster-Performance. D.h. AMD-Grafikkarten dürften von den Produktionskosten her deutlich teurer sein als ihre NVIDIA-Gegenstücke, trotz Chiplet. Und selbst wenn sie beim Rastern mithalten können, sind sie bei der Effizienz, beim Raytracing und bei diversen Software-Features, vor allem natürlich beim Upsampling, nicht konkurrenzfähig.
Momentan kann AMD wieder mal nur über den Preis konkurrieren, hat aber vermutlich deutlich, deutlich weniger Preisspielraum als NVIDIA. D.h. wenn NVIDIA wirklich möchte, könnten sie an der Preisfront alles kontern.
Und je wichtiger DLSS & Co. werden, desto mehr wird sich das auch auf der Kostenseite niederschlagen. NVIDIA braucht für eine bestimmte Leistung einfach deutlich weniger Hardware. Und momentan sieht es leider überhaupt nicht danach aus, als ob AMD hier würde mithalten können.
Selbst nvidia kennt amd pläne nicht und die sind sehr an der entwicklung vond er fertigung abhängig. mcm wird noch vermehrt Thema werden in den nächsten jahren abr anders als viele denken
Wenn man die patente durchgeht von amd wird schnell klar das amd nuer eins aufhäölt und das ist die frtigung ähnlich zu intel von 2014-2020 stagnieren wir gerade bei der latenz zwischen verschiendener chipmodule das wird aufgebrochen sobald es n2x mit gaa und die chip verbindungen übereinander gelöszt sind undd es wenioger zu wämrestaus führt
Das resultat ist ab n1,8 das auf der fläche die chips gestapelt sind und in der höher die alu das kan man bis zu 4 lagen machen .
Speich aus einen 70mm² chip mit einen nicht mehr steigenden SI das sich erst bei gaa verkleinern wird .sidn aus planar 48sm (36sm als konsumenten chip) dann auch 46sm aktiv dann eben bis zu 4 mal soviel.
Und die kosten bleiben etwa gleich bzw Teuer den tsmc bezahlt man pro mm²
also muss man ab dem nachfolger von n1,8 sich was einfallen lassen im low end.
Den ab dann steigen die kosten pro chip stark an. Ich nehmen an das man mit zwei lagen anfängt und es im low end bei 36 bis 72sm kommen wird je nachdem wie groß der darüberliegendee si und sram wird in n4x.
Dabei nehme ich an das man die 16-18sm nimmt. =32 oder 36sm
Das derzeitige gerücht spricht von 16sm pro gpc ist aebr ein umbau der ada Architektur im sm selber ändet sich nix
N3 verspricht 15% Takt, n2 25% Takt, n2x gaa, n1,8 10% 3d chips
aus derzeit 2,8ghz wird 3,2 4,0ghz und zuletzt 4,4ghz bei nicht geändertem design
Womit ich von 4,0ghz gpu ab 2028 ausgehe amd wird wenn rdna3 gefixt wird schon 2026 die 4,0ghz gpu haben und 2028 dann 4,5ghz oder amd wird mit rdna5 vorausbrechen und erste mcm in 3d design ermöglichen mit reduziertem Takt ich gehe von maximal 2,5ghz aus. In n3 node.
Dafür steigt die Anzahl an alu im chip drastisch an ab 128cu auf etwa 200mm²
nehme ich amd ipc der Architektur komme ich da auf etwa 47tf
Der refresh dessen in n2 wird en Takt um 25% steigern =3,1ghzergeben etwa 3,8ghz 75tf
daher nehme ich stark an das man rdna5 auf n2 setzen will darum wird rdna4 nicht geben 2024 2025 und rdan5 erst q2 2026 soweit sein.
n2x bietet ne Struktur Verkleinerung und somit die Möglichkeit auf 256 alu zu kommen was die perf verdoppelt dann also 150tf
Das wäre so wenn man auf 190m² sich festlegt bei 280mm² wird das nochmals mehr 192 alu das sind schon 2 lagen
halbierte Größe dann 384 alu ab n2x 2028 bei 3,8ghz 220tf
nvidia kann mit aktuellem design maximal auf 288sm gehen dafür beim Takt maximal bis 4,0ghz kommen.
was in etwa das bedeutet
288 *88*2*4,0= 202tf damit wären 4,4ghz ab n1,8 Pflicht
und der node kommt erst 2029 bzw 2030
eine Änderung an der arch ist unabwendbar
Zur info ab n2 wird die waferbelichtung auf maximal 420mm² begrenzt
aktuell sind es 850mm²
nvidia Fläche ist aktuell bei maximal 609mm² in n5 144sm
n3 maximal 650mm² bei 192sm
n2x maximal 368mm² mit 288sm 4,0ghz 202tf
Eine Änderung der arch würde das auf 18sm per gpc 120 fp32 (112fp32 nativ) auf etwa 12gpc sein =216sm
216*120*2*3,5=184tf
mehr geht nicht und man muss in die höhe das spricht alles dafür das nvidia sich der ada design beibehält und nur die gpc Struktur ändert von 12sm auf 16sm
Was den ersten Weg beschreibt also
rtx50 maxed 192sm 104tf in q3 2024
rtx60 maxed 288sm 4,0ghz 202tf in q1 2027
amd rx8000 maxed 64cu 32tf in q4 2024-q1 2025
amd rx9000 maxed 384cu 220tf in q2-q4 2026
meine Prognosen betreffen aktuellen Gerüchten wohin die reise geht dabei ist amd die treibende kraft wenn mcm klappt hat nvidia ein Problem den dafür hat nvidia derzeit kein Rezept außer auf tsmc n1,8 abzuwarten .
Den nvidia hat keine patente für ein mcm Modullbauweise von gpu. Das ist wenn nur planar und da hat amd schon gezeigt das dies ohne Abzüge von latenz nix bringen wird.
Und nvidia wird ihren fp32 Ansatz nicht aufgeben. Dann bräuchte man ein Komplettes neues Treiberteam und eine Änderung der Philosophie hin zu Software emulation von fp32 in einen fp64 design und das zeigt intel schon das dies eine Aufgabe wäre die man sich nicht antun will.
Amd gcn war auch fp64 und man hat das fürn natives fp32 system umgestellt (rdna) seitdem läuft es rund nur mcm hat nen latenzproblem. das nur durch Takt gelöst werden kann.
Das haben sie mit rdna4 gelöst nur eben das mcm noch nicht.
Je näher wir dem release dieser arch kommen desto genauer wird meine Prognose das sind voll ausbauchips die durch sku Anpassungen (yiel9d die Leistung sich verringert.
mein Fokus liegt beim mainstream markt also was die ps6 und xbox leisten wird ab 2028 da sind es 30tf das ziel derzeit
das nvidia solange wie möglich die sku preise hoch halten will ist klar
Das man ab 2026 die krone verliert steht sicher.
amd rx8600 ab 17tf ab 300$ 12gb q2 2024 (n43 32cu 3,55ghz)
nvidia rtx5060 16tf ab 320$ 9gb q2 2024 (gb207 30sm 3,1ghz)
amd rx8700xt 28tf ab 450$ 12gb q3 2024 (n48 56cu 3,1ghz)
nvidia rtx5060ti 26tf ab 450$ 12gb q2 2024 (gb206 48sm 3,1ghz)
keine guten Aussichten für mich.