AMD: Neue Details zu Milan, kein SMT4 für Zen 3-Prozessoren

AMDs Senior Manager im Bereich HPC Applications, Martin Hilgeman, hat in einer kürzlichen Präsentation neue Details zu den Rome-Nachfolgern "Milan" verraten. Gab es jüngst noch Spekulationen um SMT4, steht nun fest, dass es auch weiterhin bei zwei Threads pro Rechenkern bleiben wird.
Kürzlich machten Gerüchte um potentielles SMT4 für AMDs nächste CPU-Generation auf Zen 3-Basis breit. Angestoßen von einem älteren, vermeintlichen "Leak", wagten die Kollegen von hardwareluxx.de das "Gedankenexperiment" von vier Threads pro physischem Rechenkern für Zen 3-CPUs. Dabei bezog man sich erst einmal explizit auf die Server-Produkte, die unter dem Codenamen "Milan" laufen. Mittlerweile steht fest, dass es bei zwei Threads pro Kern bleiben wird.
Offizielle AMD-Roadmap erteilt Spekulationen um SMT4 für Zen 3 eine Absage
In einer aktuellen Präsentation im Zuge der HPC-AI Advisory Council im britischen Leicester gewähnte AMD, vertreten durch den Senior Manager im Bereich HPC Applications Martin Hilgeman, einige Einblicke zur nächsten Generation an Server-CPUs und damit auch Zen 3. Allzu tief ließ AMD allerdings nicht blicken, aber immerhin tief genug, um festzustellen, dass es beim jetzigen SMT bleiben wird.
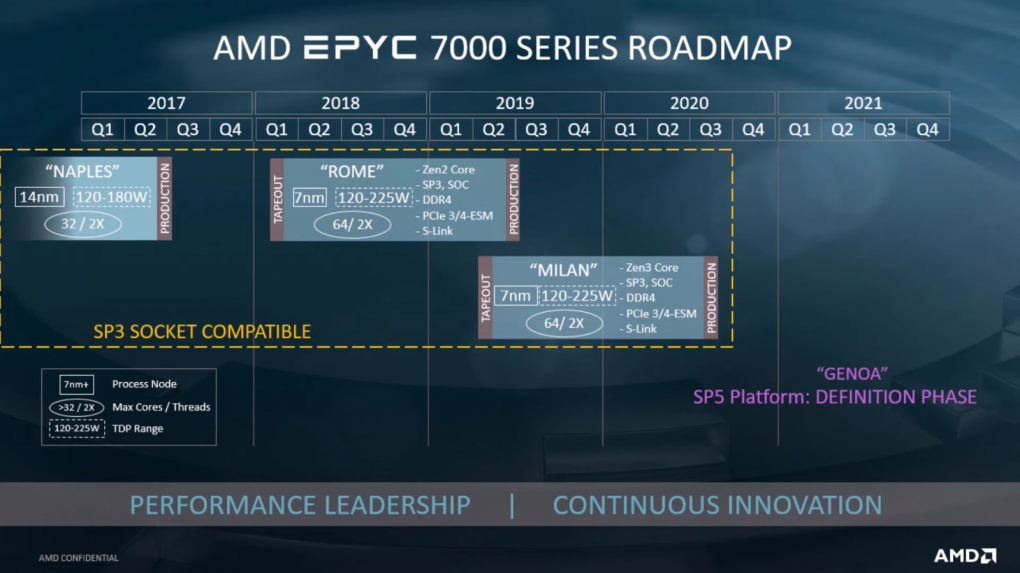
Auf der nachfolgenden Roadmap ist explizit die Rede von "64/ 2x", was wiederum maximal 64-Kerne mit jeweils zwei Threads bedeutet, wie auch der aufgeführten Legende zu entnehmen ist. Auch sonst deutet sich kein größerer Umbruch gegenüber den aktuellen Rome-CPUs auf Zen 2-Basis an.
 Quelle: AMD
AMD HPC Roadmap
Quelle: AMD
AMD HPC Roadmap
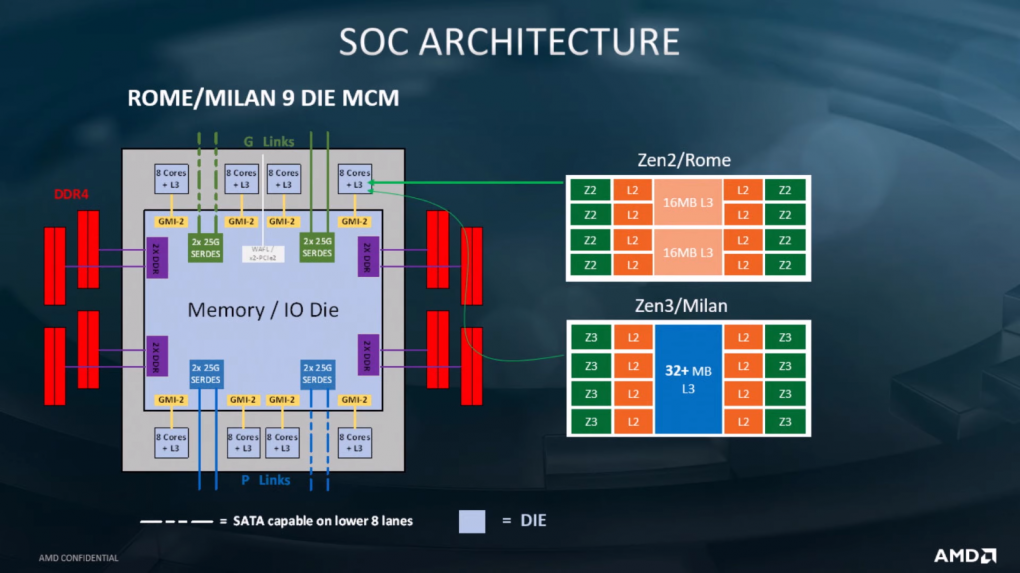
Das macht nicht nur die Roadmap deutlich. Auf einer späteren Folie darf ein kurzer Blick auf die Architektur von Milan geworfen werden. Im groben unterscheidet sich diese nicht von Rome. Änderungen gibt es aber am Aufbau der genutzten Zen 3-Chiplets. Die beherbergen weiterhin jeweils acht Kerne, sind jedoch etwas anders aufgebaut. Der aktuell getrennte L3-Cache wird zusammengelegt, sodass sich alle Kerne eines Chiplets aus einem gemeinsamen L3-Cache von mindestens 32 MiByte bedienen. In die Produktion soll Milan ab dem dritten Quartal 2020 gehen.
 Quelle: AMD
Details zur Architektur von Rome und Milan
Quelle: AMD
Details zur Architektur von Rome und Milan
Auch lesenswert: Ryzen 3000: Preise auch drei Monate nach Launch relativ stabil
Eine kleine Randnotiz auf der Roadmap ist derweil auch der Milan-Nachfolger "Genoa". Die Thematik wird auch kurz von Hilgeman angerissen. Die werden "komplett anders sein". Das bezieht sich nicht nur auf die Ablöse von Sockel SP3, der durch SP5 ersetzt wird. Auch spricht der AMD-Vertreter von "neuem Speicher und neuen Fähigkeiten". Aktuell wird erwartet, dass bei der neuen Plattform unter anderem auf DDR5 und PCI-Express 5.0 gesetzt wird.
Die vollständige Präsentation von der aktuellen HPC-AI Advisory Council, bei der es hauptsächlich um AMDs aktuelle Rome-Riege geht, finden Sie in voller Länge nachfolgend.
![[PLUS] 5 CPUs im Streaming-Test: Was leisten Vier-, Sechs- und Achtkern-CPUs?](/screenshots/1020x/2019/08/aufmacher_streaming-pcgh1.png)
[PLUS] 5 CPUs im Streaming-Test: Was leisten Vier-, Sechs- und Achtkern-CPUs?
mehr ...









Hier könnt ihr auch mal durchscrollen: http://ir.amd.com/static-... (AMD EPYC HORIZON Executive Summit – Presentation)
exakt.
x86-64 - Wikipedia
Es gibt auch Gerüchte, dass entsprechende Schaltungen schon in Northwood integriert, aber wegen Fehlern noch deaktiviert waren. (Ob es stimmt? Offizielle Einführung kam erst mit Prescott und gleichzeitig stieg die Transistorzahl dramatisch, allerdings sollte auch der gleiche ALU-Durchsatz plötzlich ohne double pumping erzielt werden.)
Schlussendlich ist das Design von IBM jedoch nicht mit dem SMT-Design von Intel/AMD vergleichbar, denn letzteres steigert im wesentlichen die Effizienz/Auslastung der existierenden Funktionseinheiten. IBM dagegen hat als kleinste funktionelle Recheneinheit einen Slice definiert, der einen Thread verarbeiten kann und Einheiten für INT/FP- , Skalar- und Vektor-Operationen bietet. Die SO/SMT4-Variante kombiniert 4 Slices zu einem Rechenkern, dagegen die SU/SMT8-Variante kombiniert 8 Slices zu einem Kern und da es ersteren mit bis zu 24 und letzteren mit nur bis zu 12 Kernen gibt, kommt man am Ende für beide Varianten bei etwa 8 Mrd. Transistoren und maximal 96 parallele Threads raus. **) Im Unterschied zu Intel/AMD kommt hier also jeder hinzugenomme Thread mit einem festen Verhältnis an zusätzlichen Ausführungseinheiten daher und das erklärt natürlich, warum der POWER9 auch mit "SMT4/8" recht effizient arbeitet und eine wohldefinierte Leistung pro Thread auf die Straße bringt.
Mit einem etwas unbedarfteren Blick auf SMT in Verbindung mit x86 verstehen viele diese Art der Steigerung von Instruction Level Parallelism jedoch in der Art, dass man den Kernen einfach nur die Verwaltungsmöglichkeiten geben muss, damit sie anstatt der bisher zwei Threads bspw. auch vier Threads verwalten und differenzieren können (IP, Stack, Cache, usw.) und schon hat man mehr Leistung hinzugewonnen und genau das wird eben nicht der Fall sein. Die auf x86 beobachteten Best Case Szenarien von 20 % bis gar in Einzelfällen 30 % Durchsatzsteigerung mittels SMT2 dürfte wohl schon nahezu eine optimale/maximale Auslastung der x86-Funktionseinheiten (in realistischen Workloads) darstellen, d. h. SMT4 wird ohne zusätzliche Funktionseinheiten (ALUs/Vektoreinheiten, etc.) nur in seltenen Fällen überhaupt einige wenige Prozent zusätzlich bringen. Auf x86 müssten also die Kerne deutlich "breiter" werden ... demgegenüber ist AMD mit Zen2/Rome den anderen Weg gegangen und hat stattdessen die Kernzahl erhöht.
Zum Vergleich, weil es hier gerade passt:
IBM System S924
2 x POWER9 SU/SMT8 (je 12 Kerne, 3,4/3,9 GHz, 120 MiB L3 eDRAM)
2 x rd. 8 Mrd. Trans., 693 mm2 in 14 nm
bis zu 344 GiB/s Speicherbandbreite
SPEC 2017 CPU INTrate = 213 Punkte
AMD Epyc 7402P
1 x 7402P SMT2 (24 Kerne, 2,8/3,35 GHz, 128 MiB L3)
ca. 19,1 - 21,8 Mrd. Trans., 528 - 667 mm2 in 7 nm/14 nm (effektive Nutzung)
bis zu 205 GiB/s Speicherbandbreite
SPEC 2017 CPU INTrate = 170 Punkte
Das POWER9-System ist hier nur 25 % schneller wobei dessen deutlich höherer Takt, der doppelt so große L3-Cache sowie die deutlich höhere Speicherbandbreite zu berücksichtigen ist.
AMD hat also einen recht guten Job gemacht. (Der 12-Kerner Epyc 7272 als Dual-Socket-System taugt nicht zum Vergleich, da ein solches Dual-Socket-System auch nur 128 MiB L3 hätte und eine kumulierte Speicherbandbreite von gar nur 170 GiB/s.)
*) Samsung sitzt gerade daran den JESD235B-Standard vollständig umzusetzen und 12-Lagen-HBM2E zu fertigen (12 oder 24 GiB) und SK Hynix kündigte bereits 3,6 Gbps-Chips für 2020 an. Mit nur zwei Stacks wären damit bereits 48 GiB und 920 GiB/s (inkl. ECC) möglich.
**) Eine höhere Effizienz bzgl. spezifischer Workloads bleibt dennoch zu vermuten, denn ansonsten hätte sich IBM die unterschiedliche Kern-Zusammenfassung der SO- und SU-Versionen sparen können.