Intel "accelerated": Neue Fertigung 2022 und 2023, 20 Ångström 2024 [Update]
AMD und TSMC geben seit Jahren den Ton bei High-End-CPUs an, aber Intel will zum Gegenschlag ausholen: Neue Fertigungs-Nodes (mit neuen Namen) sollen künftig jährlich große Effizienzsprünge bringen und mit innovativen Packaging-Verfahren kombiniert werden.

Update 27.07.2021: Öffentliche Slides, Videos und einige Details
Die ursprüngliche Version dieser Artikels wurde anhand von Presse-Vorabinformationen erstellt um gleichzeitig mit Pat Gelsingers Auftritt in der Nacht von Dienstag auf Mittwoch online zu gehen. Zwischenzeitlich hat Intel auch die dann öffentlich gezeigte Präsentation und Videos zur Verfügung gestellt. Neue Informationen gab es kaum, aber einige Darstellungen sind anschaulicher und die verwendeten Illustrationen künftiger Prozessoren geben Spekulationen über deren Aufbau neue Nahrung. Wir haben daher die Galerie am Ende dieses Artikels um die interessantesten Slides ergänzt und einige Details in den Text einfließen lassen.
Originalartikel vom 26.07.2021
Broadwell, Skylake, Kaby Lake, Coffee Lake, Coffee Lake Refresh, Comet Lake und Rocket Lake haben zwei Dinge gemeinsam: den Hersteller und den Fertigungsprozess. Im Verlauf der letzten sieben Jahre hing Intel stetig mehr "+" an "14 nm", begeisterte aber zunehmend weniger mit Produktionsinnovationen. Immerhin den mobilen Markt konnte man im Verlauf der letzten zwei Jahre langsam auf 10 nm umstellen, Server folgen in diesem, aber verglichen mit dem seit 2019 für AMDs Ryzen-CPUs genutzten "7 nm"-Prozess von TSMC (Apple lässt dort längst in "5 nm" fertigen) wirkt Intel auf dem Papier veraltet - und kämpft in Benchmarks mit hohem Energieeinsatz um den Anschluss.
Intel accelerated: Neuer Wein in brandneuen Schläuchen
Das soll sich ändern, wie Intel am Dienstagnachmittag gegenüber Pressevertretern und in der folgenden Nach auch öffentlich bekannt gab. Unter dem Schlagwort "accelerated" wird zur offiziellen Unternehmensstrategie, was Gerüchte schon länger prophezeien: Den jahrelangen Verzögerungen bei der 10-nm-Einführung folgt eine enge Staffelung der angestauten Nachfolger. Parallel wird die Nomenklatur angepasst, um den technischen Fortschritt gegenüber Kunden besser zu kommunizieren. Oder anders gesagt: Um Marketing-Hindernisse durch ehrliche Prozessbezeichnungen abzubauen.
 Quelle: Intel
Wirklich nachvollziehbar war die Fertigungs-Namensgebung zuletzt bei keinem Hersteller. Allgemein anerkannt ist aber, dass Intels Bezeichnungen am bescheidensten waren.
Zuletzt hatte Intel nämlich "die kleinste fertigbare Struktur" als Namensgeber für Prozesse verwendet. Das heißt bei "10 nm"-CPUs waren die aktiven Zonen der Transistorfinnen knapp 10 nm breit. Die Hauptkonkurrenten in Form von Global Foundries, Samsung und TSMC zählten dagegen, ausgehend von 22 nm, munter in Wurzel-2-Schritten weiter, wann immer sie einen Verbesserungsschritt für einen Full-Node hielten. Ergebnis: Intels "14 nm"-Fertigung ist GFs "12 nm" weit überlegen; der Intel-"10 nm"-Prozess wird mit TSMCs "7nm" verglichen. Obwohl für Endkunden letztlich nur die erbrachte Leistung und Effizienz zählen, erschwert der formelle Unterschied zwischen "14 nm" und "7nm" dabei auch die Vermarktung von Core- gegen Ryzen-CPUs über die technischen Eigenschaften hinaus.
Quelle: Intel
Wirklich nachvollziehbar war die Fertigungs-Namensgebung zuletzt bei keinem Hersteller. Allgemein anerkannt ist aber, dass Intels Bezeichnungen am bescheidensten waren.
Zuletzt hatte Intel nämlich "die kleinste fertigbare Struktur" als Namensgeber für Prozesse verwendet. Das heißt bei "10 nm"-CPUs waren die aktiven Zonen der Transistorfinnen knapp 10 nm breit. Die Hauptkonkurrenten in Form von Global Foundries, Samsung und TSMC zählten dagegen, ausgehend von 22 nm, munter in Wurzel-2-Schritten weiter, wann immer sie einen Verbesserungsschritt für einen Full-Node hielten. Ergebnis: Intels "14 nm"-Fertigung ist GFs "12 nm" weit überlegen; der Intel-"10 nm"-Prozess wird mit TSMCs "7nm" verglichen. Obwohl für Endkunden letztlich nur die erbrachte Leistung und Effizienz zählen, erschwert der formelle Unterschied zwischen "14 nm" und "7nm" dabei auch die Vermarktung von Core- gegen Ryzen-CPUs über die technischen Eigenschaften hinaus.
Da Vorschläge für industrieweit einheitliche Standards mehrfach gescheitert sind, passt sich Intel deswegen jetzt der Konkurrenz an: Die zuletzt "Enhanced Super Fin" genannte letzte 10-nm-Generation wird künftig als "Intel 7" bezeichnet. Verwechslungen mit "Core (i)7" erscheinen vorprogrammiert, aber immerhin suggeriert der Name keine Maßangabe respektive -einheit wie "nm" mehr. Der bislang in der Gerüchteküche als "7 nm" gehandelte Nachfolgeprozess schrumpft analog um drei Ziffernstufen auf "Intel 4". Vermutlich orientiert man sich hier direkt an TSMC, denn bislang wurde von Intel-7-nm-CPUs eine etwas bessere Leistung (aber weitaus späteres Erscheinen) gegenüber TSMCs "5nm" erwartet. Zu "Intel 5 nm" gab es dagegen bislang kaum Gerüchte und künftige werden von "Intel 3" sprechen. Mit dessen Nachfolgern möchte man dann eine neue Ära einleiten: Der mutmaßlich in der bislang als 3-nm-Klasse bezeichneten Region liegen Node wird "Intel 20A" heißen, darauf folgt "Intel 18A"(ex-2-nm). Die Namen suggerieren damit wieder eine Maßangabe (20 Ångström entsprechen 2 nm), die Intel aber als Ausdruck für den Beginn der "angstrom era" verstanden wissen möchte.
Intel accelerated: Aggressive Roadmap
 Quelle: Intel
Intel 10 nm(+), 10 nm++, 7 nm, 5 nm und 3 nm sind Geschichte. Die Bezeichnungen der Gerüchteköche müssen den offiziellen Namen Intel 10, 7, 5, 3 und 20A weichen. Dem Entnutzer kann es egal sein – Redakteuere fluchen wegen der unvermeidbaren Wortwiederholungen, wenn man über Intels Intel-5-CPUs als Intel-7-Nachfolger und ähnlichem schreibt.
Aber was zählt ist auf dem Platz. Hier bestätigt Intel zunächst, dass Alder Lake auf Basis von 10 nm++ alias "Enhanced Super Fin" alias "Intel 7" diesen Herbst erscheinen wird. Anfang 2022 folgt das Server-Gegenstück Sapphire Rapids, dem Intel im Gespräch zunächst "zwei" Silizium-Chips zusprach, sich dann aber auf "zwei Arten" korrigierte und zur konkreten Anzahl keine Angabe mehr machen wollte. Bislang existieren nur Leaks, die offensichtlich für leistungsfähige Server gedachte Konfigurationen mit vier Chips zeigen, verbunden mittels EMIB und somit kleineren Silizium-Stücken anderer Art im Package. Es gibt aber seit längerem Spekulationen über einen Workstation- und Desktop-Enthusiast-Ableger oberhalb von Alder Lake auf Basis halb so vieler Chips. Hierzu sagte Intel nur "HEDT ist nicht tot". Gegenüber den Vorgängern Ice Lake SP (nur Server) und Tiger Lake (nur mobile) verspricht Intel auf alle Fälle 10-15 Prozent Effizienzgewinn durch die Fertigung, dazu kommen Architektur-Weiterentwicklungen. Bereits bestätigt wurde der Aufbau von Alder Lake aus bis zu 8 Big- und bis zu 8 aktiven Little-Cores; Intels Beispielrenderings bestätigen jetzt erstmals deren Größenrelation: Demnach werden vier kleine Gracemont-Kerne die Waferfläche eines Golden-Cove-Cores einnehmen und die gesamte 8+8-Kern-CPU somit den gleichen Fertigungsaufwand wie ein All-Big-Zehnkerner haben.
Quelle: Intel
Intel 10 nm(+), 10 nm++, 7 nm, 5 nm und 3 nm sind Geschichte. Die Bezeichnungen der Gerüchteköche müssen den offiziellen Namen Intel 10, 7, 5, 3 und 20A weichen. Dem Entnutzer kann es egal sein – Redakteuere fluchen wegen der unvermeidbaren Wortwiederholungen, wenn man über Intels Intel-5-CPUs als Intel-7-Nachfolger und ähnlichem schreibt.
Aber was zählt ist auf dem Platz. Hier bestätigt Intel zunächst, dass Alder Lake auf Basis von 10 nm++ alias "Enhanced Super Fin" alias "Intel 7" diesen Herbst erscheinen wird. Anfang 2022 folgt das Server-Gegenstück Sapphire Rapids, dem Intel im Gespräch zunächst "zwei" Silizium-Chips zusprach, sich dann aber auf "zwei Arten" korrigierte und zur konkreten Anzahl keine Angabe mehr machen wollte. Bislang existieren nur Leaks, die offensichtlich für leistungsfähige Server gedachte Konfigurationen mit vier Chips zeigen, verbunden mittels EMIB und somit kleineren Silizium-Stücken anderer Art im Package. Es gibt aber seit längerem Spekulationen über einen Workstation- und Desktop-Enthusiast-Ableger oberhalb von Alder Lake auf Basis halb so vieler Chips. Hierzu sagte Intel nur "HEDT ist nicht tot". Gegenüber den Vorgängern Ice Lake SP (nur Server) und Tiger Lake (nur mobile) verspricht Intel auf alle Fälle 10-15 Prozent Effizienzgewinn durch die Fertigung, dazu kommen Architektur-Weiterentwicklungen. Bereits bestätigt wurde der Aufbau von Alder Lake aus bis zu 8 Big- und bis zu 8 aktiven Little-Cores; Intels Beispielrenderings bestätigen jetzt erstmals deren Größenrelation: Demnach werden vier kleine Gracemont-Kerne die Waferfläche eines Golden-Cove-Cores einnehmen und die gesamte 8+8-Kern-CPU somit den gleichen Fertigungsaufwand wie ein All-Big-Zehnkerner haben.
Gamer erwartet schon Ende 2022/Anfang 2023 desen Nachfolger: Wie Intel offiziell bestätigt, hatte der Alder-Lake-Nachfolger Meteor Lake bereits letztes Quartal sein Tape-In; es wurden also die finalisierten Schaltpläne an die Fertigung zwecks Implementation übergaben. Aufgrund der vertikalen Integrationen respektive engen Abstimmung von Entwicklung und Fabs bei Intel ist dies praktisch gleichbedeutend mit dem Tape-Out, also der Übermittlung der finalen Belichtungsmaskendesigns, bei anderen Fertigern und Intel gibt sich entsprechend zuversichtlich, im zweiten Halbjahr 2022 die Großserienproduktion in "Intel 4" anlaufen zu lassen. Dieser Prozess soll seinerseits 20 Prozent schnellere Transistoren bei gleichem Verbrauch (für Meteor Lake wurden 5 bis 125 W TDP bestätigt) gegenüber Intel 7 ermöglichen und wird als "Granite Rapids" parallel in Datencenter einziehen. Das Rendering von Meteor Lake zeigt hierbei drei getrennte, gleich große Chips für GPU, Recheneinheiten und "SoC-LP". Granite Rapdis scheint ebenfalls drei verschiedene Silizium-Typen zu verwenden, wobei die nur noch zwei zentralen, mutmaßlich die Recheneinheiten tragenden Chips von Intel in 6 × 10 Segmente strukturiert werden. Das spricht für eine enorme Steigerung der Kernanzahl gegenüber Sapphire Rapids, auch wenn Intel wie gehabt einiger der resultierenden 120 Mesh-Segmente mit I/O-Controllern füllen dürfte.
Ein weiteres Jahr später, also in der zweiten Hälfte 2023, steht bereits die "Intel 3"-Großserienproduktion auf dem Plan. Während für Intel 7 und Intel 4 nur zunehmenden EUV-Einsatz als Verbesserungsmaßnahme genannt wird, verspricht Intel 3 eine höhere Packdichte innerhalb der logischen Verschaltungen der High-Performance-Libraries und "optimierte" Metall-Interconnects. Zusätzlich gibt es 18 Prozent Effizienzgewinn auf Transistorebene; das wären in der Summe 60 Prozent gegenüber heutigen Tiger-Lake-CPUs nur durch die Fertigung für Anfang 2024 auf den Markt gelangende Produkte.
Intel accelerated: Gate All Around und Power Via
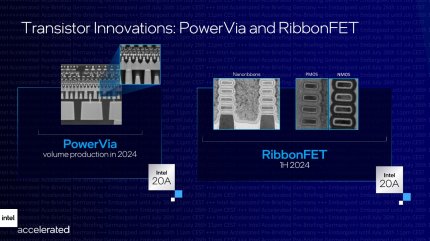 Quelle: Intel
Power Vias nutzen die Silizium-Rückseite für die Stromversorgung, Details bleiben vorerst geheim. Zu Gate-All-Around-Transistoren, auch in der von Intel favorisierten Bänder-Ausführung, gibt es dagegen schon reichlich wissenschaftliche Literatur – hier stehen die Fragezeichen hinter "wann" und "wie teuer".
Mit Intel 20A folgt dann ein großer Bruch und Intels Interpretation des Gate-All-Around-Konzepts. Wie der Name schon andeutet, kontaktiert das steuernde Gate den zu schaltenden Transistorkanal hier nicht nur von der Oberseite (herkömmlicher, planarer Transistor) oder von drei Seiten (FinFET), sondern rund um. Lohn ist eine nochmals bessere Kontrolle der (Halb-)Leitung, also niedrigere Leckströme und ein schnellerer Wechsel zwischen "aus" und "ein". Zusätzlich erlauben Intels "RibbonFETs" ebenso, wie vergleichbare Pläne von Samsung oder TSMC, eine platzsparende Leistungsskalierung: Ein RibbonFET besteht aus mehreren flachen Bändern, die übereinander gestapelt das Gate durchstoßen. Durch Variation der Bänderanzahl kann also leicht die Leistungsfähigkeit variiert werden, ohne die Grundfläche zu ändern, während heutige FinFETs eine bis vier Finnen parallel schalten.
Quelle: Intel
Power Vias nutzen die Silizium-Rückseite für die Stromversorgung, Details bleiben vorerst geheim. Zu Gate-All-Around-Transistoren, auch in der von Intel favorisierten Bänder-Ausführung, gibt es dagegen schon reichlich wissenschaftliche Literatur – hier stehen die Fragezeichen hinter "wann" und "wie teuer".
Mit Intel 20A folgt dann ein großer Bruch und Intels Interpretation des Gate-All-Around-Konzepts. Wie der Name schon andeutet, kontaktiert das steuernde Gate den zu schaltenden Transistorkanal hier nicht nur von der Oberseite (herkömmlicher, planarer Transistor) oder von drei Seiten (FinFET), sondern rund um. Lohn ist eine nochmals bessere Kontrolle der (Halb-)Leitung, also niedrigere Leckströme und ein schnellerer Wechsel zwischen "aus" und "ein". Zusätzlich erlauben Intels "RibbonFETs" ebenso, wie vergleichbare Pläne von Samsung oder TSMC, eine platzsparende Leistungsskalierung: Ein RibbonFET besteht aus mehreren flachen Bändern, die übereinander gestapelt das Gate durchstoßen. Durch Variation der Bänderanzahl kann also leicht die Leistungsfähigkeit variiert werden, ohne die Grundfläche zu ändern, während heutige FinFETs eine bis vier Finnen parallel schalten.
Eine weitere Innovoation von Intel 20A soll die Stromversorgung der Transistoren über die Chip-Rückseite werden. Bislang sind Strom- und Datenleitungen über den Transistoren gestapelt, was ein interferenzfreies, kurzwegiges Routing erschwert. Intel möchte daher großflächig Through-Silicon-Vias durch das Silizium bohren und die bislang ungenutzte Rückseite für die elektrische Verschaltung verwenden. Die hierzu verwendeten "Nano TSVs" sind 500 mal feiner als bisherige Lösungen, was große Fragen zu ihrer Realisierung aufwirft, denn bei bisherigen Fertigungsverfahren ist der minimal mögliche TSV-Durchmesser eng an die TSV-Länge respektive die zu durchdringende Wafer-Dicke gekoppelt. Auch sind die Nano-TSVs weiterhin deutlich größer als einzelne Transistoren. Zur Feinverteilung des Stroms wollte Intel aber noch keine Angaben machen - "20A" soll erst im Frühjahr 2024 an Fahrt aufnehmen. Entsprechende Produkte sind also erst für 2025 zu erwarten, parallel läuft dann möglicherweise intern schon die "Intel 18A"-Vorserie. Auf Fertigungsseite kommt in der Ångström-Ära High-NA EUV zum Einsatz; es werden also Belichtungen in kurzer Wellenlänge und Optiken mit großer numerischer Apertur kombiniert. Letztere beziffert ein hohes optische Auflösungsvermögen und entsprechende Linsen- (respektive bei EUV: Spiegel-)Systeme gibt es bislang nur für herkömmliche ArF-Laser. Dort tragen sie unter anderem dazu bei, dass Intels 10-nm-Fertigung trotz 193 nm Wellenlänge Strukturen ermöglicht, die TSMCs 13,5-nm-EUV-Ausbelichtungen die Stirn bieten. Was die Kombination beider Techniken ermöglichen wird, muss sich zeigen.
Intel accelerated: Foveros Omni und Foveros Direct
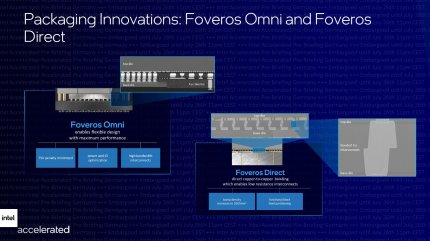 Quelle: Intel
Foveros Omni entspricht dem bereits bei Lakefield umgesetzten Konzept. Foveros Direct erinnert dagegen an die von AMD für 3D-Cache eingekaufte Technologie, dürfte beim Packaging-Spezialisten Intel aber eine eigenständige Entwicklung mit bislang unbekannten Details sein.
Parallel zu den Fertigungsinnovationen feilt Intel weiter am Prozessorpackaging, bei dem man sich bereits heute an der Weltspitze sieht - und das nicht zu Unrecht. Bereits erwähnt wurden Embedded Multi Die Bridges (EMIB): Im Substrat-PCB eingebettete Silizium-Chips, die eine ähnliche Verbindungsqualität wie von AMDs Radeon Fury bekannte Silizium-Interposer erreichen, aber viel billiger und für größere Designs geeignet sind. Bei Sapphire Rapdis soll sich der Chip-Verbund hierbei "fast wie" ein monolithischer Chip verhalten. Bereits seit Längerem wird spekuliert, dass Intel ohne einen aufwendigen, langsamen externen Interconnect nach Vorbild von AMDs Infinity Fabric auskommen möchte und stattdessen das interne Mesh direkt über mehrere Chips spannen kann. Hierzu gab es aber keine eindeutige Aussage, nur eine Verkleinerung des EMIB-Kontaktabstandes von derzeit 55 µm auf 45 µm für Granite Rapids wurde angekündigt.
Quelle: Intel
Foveros Omni entspricht dem bereits bei Lakefield umgesetzten Konzept. Foveros Direct erinnert dagegen an die von AMD für 3D-Cache eingekaufte Technologie, dürfte beim Packaging-Spezialisten Intel aber eine eigenständige Entwicklung mit bislang unbekannten Details sein.
Parallel zu den Fertigungsinnovationen feilt Intel weiter am Prozessorpackaging, bei dem man sich bereits heute an der Weltspitze sieht - und das nicht zu Unrecht. Bereits erwähnt wurden Embedded Multi Die Bridges (EMIB): Im Substrat-PCB eingebettete Silizium-Chips, die eine ähnliche Verbindungsqualität wie von AMDs Radeon Fury bekannte Silizium-Interposer erreichen, aber viel billiger und für größere Designs geeignet sind. Bei Sapphire Rapdis soll sich der Chip-Verbund hierbei "fast wie" ein monolithischer Chip verhalten. Bereits seit Längerem wird spekuliert, dass Intel ohne einen aufwendigen, langsamen externen Interconnect nach Vorbild von AMDs Infinity Fabric auskommen möchte und stattdessen das interne Mesh direkt über mehrere Chips spannen kann. Hierzu gab es aber keine eindeutige Aussage, nur eine Verkleinerung des EMIB-Kontaktabstandes von derzeit 55 µm auf 45 µm für Granite Rapids wurde angekündigt.
Meteor Lake wird stattdessen auf die zweite Foveros-Generation setzen; Chips also nicht nur nebeneinander vernetzen, sondern auch aufeinanderstapeln. Statt Foveros Omni, dass im wesentlich die vom Lakefield-SoC bekannten Möglichkeiten zur Integration verschiedener Chips bietet (RAM auf CPU auf I/O-Hub), könnte hierbei das neu vorgestellte Foveros Direct zum Einsatz kommen: Zwei technisch ähnliche Chips (dass es die gleiche Fertigung sein muss, wurde weder bestätigt noch widersprochen) werden direkt auf der Transistorenseite miteinander verbunden. Und zwar wirklich direkt, Kupfer an Kupfer ohne Lot dazwischen. Wie genau Intel diese Verbindung erreichen möchte, bleibt aber vorerst geheim.
Intel accelerated: ... und all das für zum Beispiel Amazon und Qualcomm
 Quelle: Intel
Intels Integration von Fertigungs-, Packaging- und Logikentwicklung unter einem Dach nebst Teilen der jeweiligen Zuliefererindustrie ist ein unbestrittener Vorteil gegenüber anderen Firmen, der jetzt auch am Foundry-Markt überzeugen soll.
Neben neuer Technik arbeitet Intel auch an einem neuen Firmenkonzept und möchte zum weltweit führenden Auftrags-Halbleiterfertiger aufsteigen. Wie ernst man es damit meint, zeigt ein in Worten kleiner Zusatz zu den vorangehend beschriebenen Techniken: Diese sind nämlich nicht Intel-exklusiv, sondern stehen allen interessierten Kunden zur Verfügung. Nach eigenen Angaben hat Intel bereits über ein Dutzend Partnerschaften geschlossen, namentlich genannt wurden Amazon und Qualcomm. Erstere werden für neue Amazon-Web-Service-Server-CPUs Intels Packaging-Technologien nutzen - und zwar nur diese. Die eigentlichen Chips stammen dagegen aus Fremdfertigung, vermutlich TSMC, ohne das Intel Berührungsängste zeigt. Mit den ARM-Experten von Qualcomm teilt man währenddessen weit in die Zukunft reichende Betriebsgeheimnisse, denn beide Unternehmen kooperieren bereits jetzt für in Intel 20A gefertigte Prozessoren.
Quelle: Intel
Intels Integration von Fertigungs-, Packaging- und Logikentwicklung unter einem Dach nebst Teilen der jeweiligen Zuliefererindustrie ist ein unbestrittener Vorteil gegenüber anderen Firmen, der jetzt auch am Foundry-Markt überzeugen soll.
Neben neuer Technik arbeitet Intel auch an einem neuen Firmenkonzept und möchte zum weltweit führenden Auftrags-Halbleiterfertiger aufsteigen. Wie ernst man es damit meint, zeigt ein in Worten kleiner Zusatz zu den vorangehend beschriebenen Techniken: Diese sind nämlich nicht Intel-exklusiv, sondern stehen allen interessierten Kunden zur Verfügung. Nach eigenen Angaben hat Intel bereits über ein Dutzend Partnerschaften geschlossen, namentlich genannt wurden Amazon und Qualcomm. Erstere werden für neue Amazon-Web-Service-Server-CPUs Intels Packaging-Technologien nutzen - und zwar nur diese. Die eigentlichen Chips stammen dagegen aus Fremdfertigung, vermutlich TSMC, ohne das Intel Berührungsängste zeigt. Mit den ARM-Experten von Qualcomm teilt man währenddessen weit in die Zukunft reichende Betriebsgeheimnisse, denn beide Unternehmen kooperieren bereits jetzt für in Intel 20A gefertigte Prozessoren.
Intel accelerated: Fazit
Die beiden spannendsten Aussagen des heutigen Tages betreffen nicht die Technik - deren Aspekte waren meist schon in Leaks enthalten, auch wenn eine offizielle, gesammelte Präsentation natürlich eine willkommene ist. Aber die eigentlichen Kampfansagen sind der Zeitplan und die Offenheit, mit der Intel auftritt. Dem Einzug von 10 nm, Verzeihung "Intel 7", in den Desktop diesen Winter soll 2023, 2024 und 2025 jedes Jahr ein kompletter Fullnode folgen und Intel 18A wird offensichtlich für 2026er Produkte vorbereitet. Das wäre eine doppelt so schnell Neuerungsrate wie zu "Alien Fab"-Intels Glanztagen und als Aktienunternehmen kann man derartige Versprechen nicht komplett aus der leeren Luft greifen. Beinahe noch erstaunlicher ist aber, dass die sonst so verschwiegenen Intel-Offiziellen mit Informationen geradezu um sich schmeißen: Release-Zeitraum von Granite Rapids, TDP-Angaben von Meteor Lake, Produktpartnerschaften für 2024/2025 - Intel spricht auf einmal gerne über kommende Produkte, wo man doch zuletzt eher umso leiser wurde, je stärker AMDs Ryzens auftraten. Die heute an den Tag gelegte Bereitschaft, aus angestrengter Marktlage heraus detailliert über kommende Technik zu reden, gab es dagegen zuletzt kurz vor der letzten Neburst-Generation - als es öffentliche Vorführungen von Conroe gab und erste "Core 2"-Benchmarks auftauchten. Ob Intel in den kommenden Jahren einen ähnlichen Gegenangriff wie damals startet, bleibt abzuwarten - aber zumindest scheint man sich selbst in der Lage dazu zu sehen.









Die Mühe, das zu verstehen, kann man doch erwarten, oder irre ich mich da??
Du verwendet leider zuweilen widersprüchliche Formulierungen, so bspw. die Cachegröße ist egal und weist dann aber explizit auf die konkreten Cachegrößen hin.
Was ist den nun deine Kernaussage? Versuche die doch mal in einem einzigen Satz zu formulieren. - Etwa dass Gaming mit Zen4 nicht mehr nennenswert schneller werden kann?
Echt mal jetzt, du gibst dir Null Mühe, stattdessen kommst du mit irgendwelchen Sachen, die klar sind oder längst geklärt sein sollten. Bin ein wenig angefressen deswegen gerade.
Mit "Gesamtgröße des L3 Caches" ist doch offenbar gemeint die Summe über alle CCX/CCD. Ich meine, ich habe doch genügend Zusatzinfos geliefert, um genau diesen Sachverhalt zu verstehen. Die Gesamtgröße ist doch völlig egal, was zählt ist, was ein Thread maximal nutzen kann und das sind 16MB beim 5700G und bei Zen 2 sowie 32MB bei Zen 3.
Es ging doch darum, dass du meine Ausgangsthese nicht nachvollziehen konntest. Ich hatte das doch ursprünglich so formuliert: AMD wird sein Pulver mit Zen 3 + 3D Cache in Bezug auf Gaming bereits verschossen haben. Zen 4 + 3D Cache wird das nicht großartig toppen können, weil der Cache der entscheidende Faktor ist. Ich gehe dabei natürlich davon aus, dass die Summe "standard Cache" + 3D Cache pro CCD gleich groß sein wird.
Die grundsätzliche Idee dahinter ist, dass der Cache der limitierende Faktor ist und nicht die Kerne (IPC). Und jetzt komm nicht damit, dass IPC nicht ohne Cache bestimmt werden kann.
Du kannst das Pferd auch anders herum aufzäumen. Warum bricht der 5700G gegenüber dem 5800X so deutlich ein? Der Takt ist ziemlich vergleichbar. Das PL ist nicht das Problem. Die Speicherspec ist identisch. Ist der Cache. Die IPC der Kerne spielt keine messbare Rolle.
Verstehe ich gerade auch nicht den Satz. Natürlich legen beide Archs zu, aber verglichen untereinander wird der Unterschied kaum messbar sein, weil das, was die CPUs schnell macht in Games nicht die Kerne mit mehr IPC sind, sondern der 3D Cache.
Und all das zeigen die Benchmarks mit dem 5700G.
(Nachträglich ergänzt nach Durcharbeitung deines gesamten Posts: Vielleicht aber aufgrund nur einzelner, verwirrender Aussagen, s. u.)
Kurzform: Das Ergebnis 5700G zu 3700X ist vollkommen erwartbar und zeigt keine Überraschungen. Zudem zeigt es (anteilsmäßig) die Leistungsverluste durch einen kleineren Cache auf (relativ zu Vermeer).
Einerseits haben ich nirgends gigantische Leistungszugewinne von PCIe4 impliziert, andererseits wird die Beschränkung auf 3.0 dennoch einen kleine Effekt haben, möglicherweise hier gar einen etwas größeren, da hier wesentlich mehr Frames als in hohen Auflösungen berechnet werden und damit vermutlich auch noch etwas mehr über den PEG geschickt wird (gesichert quantifizieren kann ich das nicht, lässt sich aber theoretisch leicht erahnen, denn wenn ich davon ausgehe, dass im Test angenommenerweise keine Assets nachgeladen werden müssen, steigt der Komminikaitonsaufwand zw. CPU und GPU dennoch mit jedem zusätzlichen Frame).
"Die Gesamtgröße des Caches ist ja in der Regel nicht entscheidend"
Extrem obskur (selbst im Rahmen deiner ansonsten zu diesem Thema getätigten Aussagen; ich vermute hier hast du dich vertan? Andererseits verfolgt du den Gedanke aj nachfolgend gar noch weiter?!?), denn AMD zeigte mit ihrer frühen V-Cache-Demonstration genau das Gegenteil und der um 200 % größere L3$ soll hier angeblich +12 bis +15 % mehr Fps bringen. und die Größe des L3$ ist der einzige Unterschied der V-Cache-Modelle nach AMDs bisherigen Aussagen.
Übrigens, dass die 2-CCD-Modelle keine gigantischen Leistungs-Booster aufgrund des Caches erfahren liegt schlicht daran, dass hier Daten redundant in beiden Caches vorgehalten werden. Effektiv ist das ein 2x32 MiB L3$ und kein 64 MiB L3$. Müssten hier Kerne von CCD1 unentwegt wegen Datentransfers den Weg über den IF und IOD nehmen um auf den Cache des CCD2 zuzugreifen, würde das den Chip beträchtlich ausbremsen und das zusätzlich, denn die Latenzen erhöhten sich bereits alleine in Verbindung mit der Vergrößerung auf 32 MiB/CCD mit Zen2.
Entsprechend schreibt auch AnandTech: "The single chiplet design means 32 MB of L3 cache total (technically it’s still the same that a single core can access as the Ryzen 9 parts" und man sieht im Latency-Diagramm des 5950X auch, dass die Latenzen um ein Vielfaches ansteigen, sobald man die 32 MiB überschreitet. (Beim 3950X findet diese "Latenz-Explosion" entsprechend bereits bei 16 MiB statt, weil hier dass ältere CCD bereits einen zweigeteilten L3$ besaß.)
Und dann verwirrst du gleich noch mehr im Kontext deiner vorausgegangenen Aussagen, denn
"Entscheidend ist vielmehr der pro Thread maximal verfügbare L3 Cache und der ist beim 5700G (1-CCD) und 3700X (2-CCX) mit 16MB identisch. So was wie shared oder Remote Cache gibt es bei Ryzen nicht."
die wiederum ist plausibel. Witzigerweise widersprichst du dir damit aber gar selbst, s. o.
Und das hat nichts mit das Pferd-von-hinten-aufzäumen zu tun. Beim 5700G und 3700G hat man grob vergleichbaren Takt und einen vergleichbar großen L3$. Entsprechend fällt der Leistungszugewinn der Zen3-APU gering aus, weil hier die Zugewinne durch den größeren Cache fehlen, der offensichtlich einen nennenswerten Anteil an den Gesamtzuwächsen von Zen3 auf dem Desktop hat.
Ahhrg ... schon wieder Missverständnisse? Jedenfalls dein letzter Absatz deutet darauf hin:
"Verstehe ich gerade auch nicht den Satz. Natürlich legen beide Archs zu, aber verglichen untereinander wird der Unterschied kaum messbar sein, weil das, was die CPUs schnell macht in Games nicht die Kerne mit mehr IPC sind, sondern der 3D Cache."
Noch mal: Ich rede immer noch und unverändert von absoluter Leistung:
Zen2 : 100
Zen3 : 115
Zen3+VC: 130
Zen4: 130
Zen4+VC: 145
Also bringt auch die Kombination des V-Cache mit Zen4 gegenüber der reinen Basisarchitektur noch einmal ein signifikantes Leistungsplus. (Die Werte nicht wörtlich nehmen, rein zu Demonstrationszwecken).
Was natürlich absurd ist, wäre, dass ein V-Cache bei Zen3 +15 bringt, bei Zen4 aber plötzlich nur +5 oder gar +30 bringen können soll. (Genaugenommen würde der Zugewinn gar tendenziell höher werden, da bei grob gleichschnellem DRAM die schnellere CPU zunehmend ausgebremst wird.)
Darüber hinaus an deinen früheren Satz angelehnt:
"Meine ursprüngliche These war, dass Zen 4 (mit 3D Cache) im Vergleich mit Zen 3 (auch mit 3D Cache!) nicht mehr so stark bei der Gamingleistung zulegen wird ..."
Absolut gesehen wäre diese Aussage falsch (s. o. 130 vs. 145), wenn du dagegen den relativen Zugewinn meinst, dürfte das grob hinkommen, wobei, wie schon gesagt, eine noch schnellere CPU noch etwas mehr von einem größeren L3$ profitieren wird.
Anders dargestellt:
Theoretische IPC, wenn das DRAM nicht beschränken würde:
Zen3: 100
Effektive IPC im regulären Ausbau: 32 MiB L3$ + 3200er DRAM
Zen3: 83
Effektive IPC mit 96 MiB L3$
Zen3: 95
Zen4's theoretische IPC wird entsprechend deutlich höher liegen und die wird sich ähnlich verhalten.
Letzten Endes bestimmt die Cache-Größe einfach in welchem Umfang die jeweilige Architektur ihren vollen, theoretischen Leistungsdurchsatz entfalten kann. Dass die Cache-Größen typischerweise weit unterhalb des effektiven Maximums konzipiert werden, ist schlicht ein wirtschaftlicher Faktor, denn mit bspw. 32 MiB kann Zen3 seine Leistung offensichtlich schon ausreichend gut entfalten, mit dagegen 96 MiB offensichtlich gar noch deutlich besser (in vielen Szenarien). Möglicherweise würden selbst 128 MiB noch was signifikant bringen, darüber hinaus dürfte die "Wirkkurve" jedoch zunehmend abflachen, da vollkommener Random-Access dann doch eher wieder ein theoretischer Benchmark ist.
Bei Zen4 wird es gleichermaßen sein. Reguläre Modelle werden vielleicht weiterhin unverändert 32 MiB on-die haben. darüber hinaus wird es möglicherweise auch hier später erneut V-Cache-Modelle geben. Hier kann ich mir gut vorstellen, dass AMD die hinauszögern wird um Meteor Lake zu kontern, da man vielleicht bis dahin ansonsten nichts Neueres haben wird. (Zen5 dürfte wohl erst 2024 erscheinen).
Es wird interessant zu sehen sein, was eine mögliche HEDT-Plattform auf Basis von Sapphire Rapids SP werden könnte, wenn die bspw. auch 32 GiB HBM2 bieten sollten. Da hier ein DRAM-less Mode (zumindest beim Server) möglich sein soll, könnte man hier ein System mit gigantischer Bandbreite zusammenzimmern (wohl. 500+ GiB/s, also grob Faktor 5x ggü. regulärem 2-Kanal-DDR5). Eine jedoch andere Frage ist, wie sich das HBM2 bzgl. Latenzen verhält, wobei, da das alles on-Chip ist, wären die möglichen negativen Effekte vermutlich eher geringer. Könnte ein Enthusiast-Gamers-Dream werden.
Bei der Anwendungsleistung dürfte es auch kein fühlbaren Unterschied bedeuten, in den allermeisten Fällen braucht man die höhere Übertragungsleistung von PCIe4 noch gar nicht.
EDIT: Unzuverlässige Foren-Funktion, bzgl. Hinweis auf neue Beiträge während man schreibt ...