Intel Architecture Day 2021: So arbeitet Alder Lake
Mit Core i-12000 alias Alder Lake will Intel wieder an AMD vorbeiziehen und macht dabei nahezu alles anders als bisher. Wie genau wurde jetzt detaillierter verraten, einschließlich erster Leistungsdaten.
Bereits vor drei Wochen sprach Intel unerwartet offen über Pläne zu kommenden Fertigungsprozessen und bestätigte in diesem Rahmen noch einmal den Release der neuen "Alder Lake"-Desktop-Prozessoren diesen Herbst sowie der technisch verwandten Sapphire-Rapids-Modelle Anfang 2022. Beide werden in Intel 7 gefertigt, zuvor als Enhanced Super Fin oder, in der Gerüchteküche, als 10 nm++ bekannt. Der Prozess wird allgemein gleichwertig zu TSMCs "N7" eingeschätzt, den AMD für die CCDs aktueller Ryzen-CPUs nutzt. Auf dem Architecture Day 2021 legt Intel jetzt mit dem nächsten Schlag Informationen nach: Was wird da eigentlich gefertigt?
In diesem Artikel geht es um die Prozessor-Innovationen - alles Wissenswerte um die GPU-Fortschritte lesen Sie im Artikel Intel Architecture Day 2021: Technik-Details zu Xe, Arc und dem Multi-Chip-Monster Ponte Vecchio.
Alder Lake: Die Grundidee
Bereits seit Längerem ist bekannt, dass Alder Lake auf ein big.Little-Konzept setzen wird, wie es bei Smartphone-Prozessoren seit langem üblich ist. Das heißt besonders leistungsfähige Kerne, die schnell auf Benutzereingaben reagieren und schlecht parallelisierbaren Code flott ausführen können sowie weitere, langsamere Kerne die nachrangige Tätigkeiten übernehmen teilen sich die Arbeit. Bei Mobile-Geräten dient dies meist nur dem Stromsparen: Ein Großteil der Nutzung ist simple Medienwiedergabe mit geringen CPU-Anforderungen, zumindest solange die zu dekodierenden Codecs von Spezialeinheiten geschultert werden. Hierfür reichen kleine, simple Prozessorkerne aus, die sparsamer sind, als es große Gegenstücke selbst mit deutlicher Taktabsenkung und ausgeprägtem Power Gating je werden könnten.
 Quelle: Intel
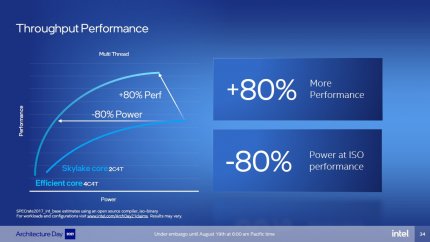
140 Prozent Leistung bei 100 Prozent Energie oder 100 Prozent Leistung bei 60 Prozent Energie: Alder Lakes Efficiency-Cores sind der Skylake-Architektur hoffnungslos überlegen. Leider weiß man nicht, welcher deren zahlreichen Vertreter als Referenz dient.
Bei Alder Lake als auch-Desktop-Prozessor hat Intel aber weitere Ziele im Auge: Zunächst arbeiten beiden Kerntypen hier grundsätzlich parallel, nicht im Wechsel, sodass die kleineren Vertreter die schnellen Ausführungseinheiten auch bei allgemein hoher Last für die dringendsden Anwendungen freihalten können. Klassische Beispiele sind Hintergrund-Services, die zwar regelmäßig ihren Status aktualisieren, aber nur selten den User benachrichtigen - sowas hat Zeit, kann aber zum Beispiel wegen Ladevorgängen trotzdem nennenswert Arbeitszeit auf einem leistungsfähigen Rechenkern blockieren. Der zweite und von Intel am meisten betonte Faktor ist Effizienz im Betrieb. Große Kerne haben nicht nur einen gewissen Mindestverbrauch, unter den sie sich schwer drosseln lassen; jede Architektur wird auch allgemein für bestimmte Lastszenarien optimiert. Verbaut man zwei verschiedene Kerntypen, kann man in mehr Situationen optimal unterwegs sein. Für Gamer und Desktop-Nutzer allgemein ist aber der dritte Punkt am spannendsten: Kleine Kerne brauchen weniger Platz. Man bekommt also sehr viele dafür zu einem akzeptablen (Herstellungs-)Preis und dadurch im Idealfall mehr Absolutleistung als bei einem homogenen "all big"-Konzept, ohne gleich die fehlenden Single-Thread-Möglichkeiten eines "all little"-Beschleunigers akzeptieren zu müssen.
Quelle: Intel
140 Prozent Leistung bei 100 Prozent Energie oder 100 Prozent Leistung bei 60 Prozent Energie: Alder Lakes Efficiency-Cores sind der Skylake-Architektur hoffnungslos überlegen. Leider weiß man nicht, welcher deren zahlreichen Vertreter als Referenz dient.
Bei Alder Lake als auch-Desktop-Prozessor hat Intel aber weitere Ziele im Auge: Zunächst arbeiten beiden Kerntypen hier grundsätzlich parallel, nicht im Wechsel, sodass die kleineren Vertreter die schnellen Ausführungseinheiten auch bei allgemein hoher Last für die dringendsden Anwendungen freihalten können. Klassische Beispiele sind Hintergrund-Services, die zwar regelmäßig ihren Status aktualisieren, aber nur selten den User benachrichtigen - sowas hat Zeit, kann aber zum Beispiel wegen Ladevorgängen trotzdem nennenswert Arbeitszeit auf einem leistungsfähigen Rechenkern blockieren. Der zweite und von Intel am meisten betonte Faktor ist Effizienz im Betrieb. Große Kerne haben nicht nur einen gewissen Mindestverbrauch, unter den sie sich schwer drosseln lassen; jede Architektur wird auch allgemein für bestimmte Lastszenarien optimiert. Verbaut man zwei verschiedene Kerntypen, kann man in mehr Situationen optimal unterwegs sein. Für Gamer und Desktop-Nutzer allgemein ist aber der dritte Punkt am spannendsten: Kleine Kerne brauchen weniger Platz. Man bekommt also sehr viele dafür zu einem akzeptablen (Herstellungs-)Preis und dadurch im Idealfall mehr Absolutleistung als bei einem homogenen "all big"-Konzept, ohne gleich die fehlenden Single-Thread-Möglichkeiten eines "all little"-Beschleunigers akzeptieren zu müssen.
Alder Lake: Eckdaten der Efficiency Cores
Bereits frühere Renderbilder von Alder Lake zeigten, dass eine Vierergruppe der kleinen, nie einzeln verbauten "E"-Cores ungefähr die gleiche Siliziumfläche einnimmt, wie ein einzelner "Performance"-Kern. Die maximale Desktop-Ausbaustufe mit 8 + 8 Kernen ist also insgesamt nicht größer als ein herkömmlicher Zehnkerner. Auf dem Architecture Day gab Intel jetzt über weitere Vergleiche auch die absolute Größe bekannt. Demnach beanspruchen vier E-Cores genauso viel Platz, wie ein älterer Skylake-Kern. Der gesamte 8-+-8-Kerner wäre demnach ähnlich groß, wie ein Core i9-10900K, welcher ebenfalls auf der Skylake-Architektur aufbaut.
 Quelle: Intel
Alder Lakes E-Cores unterstützen kein SMT, man braucht also vier Stück für vier Threads. Die sind aber zusammengenommen trotzdem nur halb so groß (enthalten fertigungsbereinigt somit ähnlich viele Transistoren) wie ein Dual-Core-Skylake und arbeiten mehr mit weniger Strom.
Dieser Fortschritt in Sachen Kerndichte ist natürlich nur teilweise auf die neue Architektur und das neue Konzept zurückzuführen. Noch wichtiger dürfte der Wechsel auf den 10-nm-Prozess "Intel 7", der etwas mehr also doppelt so viele Transistoren pro Fläche unterbringen kann, wie die alte 14-nm-Fertigung von Skylake. Er trägt auch zur Recheneffizienz der E-Cores bei, die laut Intel ihrem Namen alle Ehre machen: Pro Kern sollen sie wahlweise 40 Prozent mehr Leistung bei gleichem Verbrauch oder 40 Prozent weniger Verbrauch bei gleicher Leistung gegenüber Skylake erreichen. Für einen ganzen Cluster aus vier E-Cores werden 180 Prozent der Leistung eines doppelt so großen Dual-Core-Skylakes mit HT, also mit ebenfalls vier Threads, versprochen und das bei weiterhin niedrigerem Stromverbauch. Leider machte Intel weder Angaben, bei welchem Takt und für welche Anwendungsszenarien dieser Leistungsvorsprung gilt, sicherlich handelt es sich um einen Best-Case. Dieser ist aber ungewöhnlich beeindruckend, schließlich galten acht Skylake-Kerne vor einem Jahr noch als High-End im Notebook-Sektor. Bei Alder Lake soll diese Rechenleistung nur der Sidekick für die "echten" Kerne bilden.
Quelle: Intel
Alder Lakes E-Cores unterstützen kein SMT, man braucht also vier Stück für vier Threads. Die sind aber zusammengenommen trotzdem nur halb so groß (enthalten fertigungsbereinigt somit ähnlich viele Transistoren) wie ein Dual-Core-Skylake und arbeiten mehr mit weniger Strom.
Dieser Fortschritt in Sachen Kerndichte ist natürlich nur teilweise auf die neue Architektur und das neue Konzept zurückzuführen. Noch wichtiger dürfte der Wechsel auf den 10-nm-Prozess "Intel 7", der etwas mehr also doppelt so viele Transistoren pro Fläche unterbringen kann, wie die alte 14-nm-Fertigung von Skylake. Er trägt auch zur Recheneffizienz der E-Cores bei, die laut Intel ihrem Namen alle Ehre machen: Pro Kern sollen sie wahlweise 40 Prozent mehr Leistung bei gleichem Verbrauch oder 40 Prozent weniger Verbrauch bei gleicher Leistung gegenüber Skylake erreichen. Für einen ganzen Cluster aus vier E-Cores werden 180 Prozent der Leistung eines doppelt so großen Dual-Core-Skylakes mit HT, also mit ebenfalls vier Threads, versprochen und das bei weiterhin niedrigerem Stromverbauch. Leider machte Intel weder Angaben, bei welchem Takt und für welche Anwendungsszenarien dieser Leistungsvorsprung gilt, sicherlich handelt es sich um einen Best-Case. Dieser ist aber ungewöhnlich beeindruckend, schließlich galten acht Skylake-Kerne vor einem Jahr noch als High-End im Notebook-Sektor. Bei Alder Lake soll diese Rechenleistung nur der Sidekick für die "echten" Kerne bilden.
Alder Lake: Die Eckdaten der Perforamance-Kerne
 Quelle: Intel
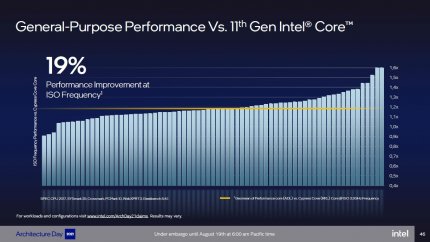
Plus 19 Prozent IPC sind für sich genommen schon ganz nett, spannend werden sie aber erst, weil man von Alder Lake Performance Cores gleichbleibend hohe Taktraten wie bei Rocket Lake erwartet.
Aus den Größenangaben zu den E-Core-Clustern leitet sich direkt ab, dass einer der größeren "P"-Cores ungefähr die Grundfläche eines ursprünglichen Skylake-Kerns einnimmt. Verglichen mit späteren Coffee- und Comet-Lake-Ausbaustufen, bei denen Intel die 14-nm-Transistorendichte zugunsten höherer Taktraten reduzierte, müsste ein Alder-Lake-Performance-Core sogar etwas kleiner ausfallen, dank Intel-7-Fertigung aber mehr als doppelt so viele Transistoren beinhalten. Diese werden vor allem in eine breitere Pipeline und somit in mehr Rechenschritte pro Takt investiert. Für gängige Systembenchmarks wie Sysmark, PCMark oder SPEC CPU verspricht Intel mindestens die gleiche, im Idealfall aber sogar die 1,6-fache Leistung pro Takt und Kern (IPC) wie bei aktuellen Rocket-Lake-Prozessoren (z.B. Core i9-11900K). Im Schnitt soll eine 19 Prozent höhere IPC erreicht werden, was bei den derzeitigen Taktspekulationen auch eine 19 Prozent höhere Absolutleistung bedeuten würde. Dieser Wert versteht sich, im Gegensatz zu vielen früheren CPU-Vorankündigungen, ohne exotische Einmaleffekte durch neue Befehlssätze für Spezialanwendungen, da Intel sich ausdrücklich auf bestehende Benchmarks bezieht.
Quelle: Intel
Plus 19 Prozent IPC sind für sich genommen schon ganz nett, spannend werden sie aber erst, weil man von Alder Lake Performance Cores gleichbleibend hohe Taktraten wie bei Rocket Lake erwartet.
Aus den Größenangaben zu den E-Core-Clustern leitet sich direkt ab, dass einer der größeren "P"-Cores ungefähr die Grundfläche eines ursprünglichen Skylake-Kerns einnimmt. Verglichen mit späteren Coffee- und Comet-Lake-Ausbaustufen, bei denen Intel die 14-nm-Transistorendichte zugunsten höherer Taktraten reduzierte, müsste ein Alder-Lake-Performance-Core sogar etwas kleiner ausfallen, dank Intel-7-Fertigung aber mehr als doppelt so viele Transistoren beinhalten. Diese werden vor allem in eine breitere Pipeline und somit in mehr Rechenschritte pro Takt investiert. Für gängige Systembenchmarks wie Sysmark, PCMark oder SPEC CPU verspricht Intel mindestens die gleiche, im Idealfall aber sogar die 1,6-fache Leistung pro Takt und Kern (IPC) wie bei aktuellen Rocket-Lake-Prozessoren (z.B. Core i9-11900K). Im Schnitt soll eine 19 Prozent höhere IPC erreicht werden, was bei den derzeitigen Taktspekulationen auch eine 19 Prozent höhere Absolutleistung bedeuten würde. Dieser Wert versteht sich, im Gegensatz zu vielen früheren CPU-Vorankündigungen, ohne exotische Einmaleffekte durch neue Befehlssätze für Spezialanwendungen, da Intel sich ausdrücklich auf bestehende Benchmarks bezieht.
Alder Lake: Thread Director
 Quelle: Intel
Der Thread Director soll dem Betriebssystem verraten, wie man Alder Lake optimal nutzt – leider ist bislang nur für Windows 11 eine entsprechender Scheduler angekündigt.
Die Leistungsversprechen von Alder Lake sind ansehnlich, aber wie nutzt man so einen komplexen Aufbau optimal? Die Befehlssätze beider Prozessorteile hat Intel schon einmal vereinheitlicht. So läufte jede Anwendung, die auf eine P-Core gestartet wird, auch auf einem E-Core fehlerfrei weiter, auch wenn die Performance-Kerne dafür Federn lassen müssen. Rocket Lake unterstützt nämlich bereits den Xeons vorbehaltenen AVX512-Befehlssatz, wenn auch ohne deren Leistungsschub. Alder Lakes P-Cores könnten das eigentlich auch, sind aber auf die Fähigkeiten der E-Cores und somit herkömmliches AVX2 beschnitten. Desktop-Anwendungen können mit AVX512 ohnehin nichts anfangen, AMD-CPUs übrigens auch nicht, sodass der Verlust eher für das Marketing von Bedeutung ist. Im Gegensatz Intels erstem Hybrid-Versuchsballon Lakefield behalten die großen Kerne bei Alder Lake aber ihre SMT-Fähigkeiten; auf den 8P-Cores laufen via Hyper-Threading also insgesamt 16 Threads, während die 8 E-Cores reine Single-Thread-Designs sind. Um Windows die Verwaltung dieser insgesamt 24 logischen Prozessorkerne zu erleichtern, hat Intel gemeinsam mit Microsoft den "Thread Director" entwickelt. Auf Hardware-Ebene stellt dieser vor allem ein Monitoring-Tool dar. Während Windows normalerweise nur sieht, ob ein Thread einen CPU-Kern belastet, erkennt Alder Lake auch die Art der Nutzung und gibt darüber Feedback.
Quelle: Intel
Der Thread Director soll dem Betriebssystem verraten, wie man Alder Lake optimal nutzt – leider ist bislang nur für Windows 11 eine entsprechender Scheduler angekündigt.
Die Leistungsversprechen von Alder Lake sind ansehnlich, aber wie nutzt man so einen komplexen Aufbau optimal? Die Befehlssätze beider Prozessorteile hat Intel schon einmal vereinheitlicht. So läufte jede Anwendung, die auf eine P-Core gestartet wird, auch auf einem E-Core fehlerfrei weiter, auch wenn die Performance-Kerne dafür Federn lassen müssen. Rocket Lake unterstützt nämlich bereits den Xeons vorbehaltenen AVX512-Befehlssatz, wenn auch ohne deren Leistungsschub. Alder Lakes P-Cores könnten das eigentlich auch, sind aber auf die Fähigkeiten der E-Cores und somit herkömmliches AVX2 beschnitten. Desktop-Anwendungen können mit AVX512 ohnehin nichts anfangen, AMD-CPUs übrigens auch nicht, sodass der Verlust eher für das Marketing von Bedeutung ist. Im Gegensatz Intels erstem Hybrid-Versuchsballon Lakefield behalten die großen Kerne bei Alder Lake aber ihre SMT-Fähigkeiten; auf den 8P-Cores laufen via Hyper-Threading also insgesamt 16 Threads, während die 8 E-Cores reine Single-Thread-Designs sind. Um Windows die Verwaltung dieser insgesamt 24 logischen Prozessorkerne zu erleichtern, hat Intel gemeinsam mit Microsoft den "Thread Director" entwickelt. Auf Hardware-Ebene stellt dieser vor allem ein Monitoring-Tool dar. Während Windows normalerweise nur sieht, ob ein Thread einen CPU-Kern belastet, erkennt Alder Lake auch die Art der Nutzung und gibt darüber Feedback.
 Quelle: Intel
Threadverwaltung ist ein Prozess, den man sich über mehrere Folien hinweg angucken muss. Schritt 1: Ein Thread sucht einen Kern.
Wartet ein Thread zum Beispiel die meiste Zeit auf Ladevorgänge von einem langsamen Speichermedium, kann er das auch auf einem E-Core tun und muss keinen Performance-Kern blockieren. Eine Anwendung die reichlich Gebrauch von komplexen SIMD-Befehlen, zum Beispiel AVX, macht, läuft dagegen auf den P-Cores deutlich schneller als auf den E-Cores. Der Thread Director meldet all diese Beobachtungen an den Scheduler des Betriebssystems und ermöglicht so eine Priorisierung der anstehenden Aufgaben. Wie Intel mehrfach betont, ist diese Evaluierung dynamisch, orientiert sich also an den tatsächlich aufgerufenen Befehlen und nutzt keine statischen Scheduling-Regeln, sodass auch gemischte Workloads wie ein Spiel mit gleichzeitigem Streaming im Hintergrund korrekt erfasst werden. Das eigentliche Kernmanagement bleibt aber dem Betriebssystem überlassen. Dieses hat also direkten Zugriff auf alle 24 logischen Kerne und muss die eigentliche Thread-Zuordnung durchführen. Das dürfte vor allem für all diejenigen ärgerlich werden, die noch nicht auf Windows 11 umsteigen möchten, denn bislang ist nur dessen Scheduler für Alder Lake vorbereitet. Da sich Intel auch im Linux-Umfeld engagiert, dürfte eine Unterstützung für Open-Source-Alternativen sowie Chrome OS zwar bald folgen, die Alder-Lake-Performance unter Windows 10 und älter bleibt dagegen spannend. Immerhin: Da das Thread-Management komplett von Hardware und Betriebssystem übernommen wird, bekommen Anwendungen davon nichts mit und müssen nicht speziell für Alder Lake optimiert werden. Laut Intel ist das umgekehrt nicht einmal möglich.
Quelle: Intel
Threadverwaltung ist ein Prozess, den man sich über mehrere Folien hinweg angucken muss. Schritt 1: Ein Thread sucht einen Kern.
Wartet ein Thread zum Beispiel die meiste Zeit auf Ladevorgänge von einem langsamen Speichermedium, kann er das auch auf einem E-Core tun und muss keinen Performance-Kern blockieren. Eine Anwendung die reichlich Gebrauch von komplexen SIMD-Befehlen, zum Beispiel AVX, macht, läuft dagegen auf den P-Cores deutlich schneller als auf den E-Cores. Der Thread Director meldet all diese Beobachtungen an den Scheduler des Betriebssystems und ermöglicht so eine Priorisierung der anstehenden Aufgaben. Wie Intel mehrfach betont, ist diese Evaluierung dynamisch, orientiert sich also an den tatsächlich aufgerufenen Befehlen und nutzt keine statischen Scheduling-Regeln, sodass auch gemischte Workloads wie ein Spiel mit gleichzeitigem Streaming im Hintergrund korrekt erfasst werden. Das eigentliche Kernmanagement bleibt aber dem Betriebssystem überlassen. Dieses hat also direkten Zugriff auf alle 24 logischen Kerne und muss die eigentliche Thread-Zuordnung durchführen. Das dürfte vor allem für all diejenigen ärgerlich werden, die noch nicht auf Windows 11 umsteigen möchten, denn bislang ist nur dessen Scheduler für Alder Lake vorbereitet. Da sich Intel auch im Linux-Umfeld engagiert, dürfte eine Unterstützung für Open-Source-Alternativen sowie Chrome OS zwar bald folgen, die Alder-Lake-Performance unter Windows 10 und älter bleibt dagegen spannend. Immerhin: Da das Thread-Management komplett von Hardware und Betriebssystem übernommen wird, bekommen Anwendungen davon nichts mit und müssen nicht speziell für Alder Lake optimiert werden. Laut Intel ist das umgekehrt nicht einmal möglich.
Alder Lake: Produktvarianten
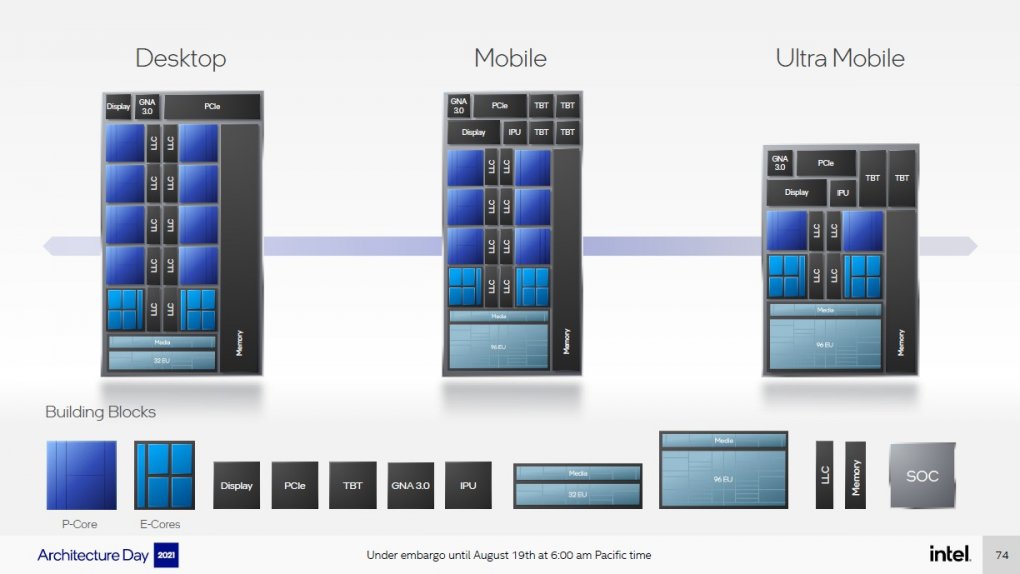
Zugeknöpft gab sich Intel auf dem Architecture Day, was die Palette möglicher Prozessoren angeht. Nomen est omen ging es der Veranstaltung eher um die interne Funktion der CPU-Kerne, deren Details sich aber noch nicht in ihrer Bedeutung einschätzen lassen, nicht um komplette Produkte. Klar ist aber: Alder Lake erscheint zunächst in drei Basiskonfigurationen. Das Desktop-Modell nutzt die ausführlich geschilderte 8-+8-Konfiguration mit einer vergleichsweise kleinen Grafikeinheit. Intel plant hier offensichtlich keinen Konkurrenten zu AMDs neuen Desktop-APUs, sondern sieht bei den High-End-Prozessoren nur eine Grafikausgabe mit 32 Ausführungseinheiten für Office- und einfache Multimedia-Zwecke vor; Gamer sollten auf eine dedizierte Grafikkarte setzen. Umgekehrt erhalten die Alder-Lake-Mobile-Modelle in BGA-Bauform eine IGP mit 96 Execution Units, je nach Klasse aber nur zwei oder sechs P-Cores, während es bei durchgängig acht E-Cores bleibt. Cache-seitig setzt Intel auf 1,25 MiB L2 je P-Core, während sich jeweils vier E-Cores im Cluster bis zu 4 MiB L2 teilen. Der Vollausbau im Core i9-12900K käme demnach auf 18 MiB L2-Cache insgesamt, dazu gibt es 30 MiB nicht inklusivem Last Level Cache. Wie schon seit Haswell üblich, dient dieser den CPU-Kernen als L3, wird aber auch von der IGP mitgenutzt. Intels Grafiken legen nahe, dass er als 1,5-MiB-Slice je P-Kern respektive E-Cluster organisiert ist, die kleine 2-+-8-Ultra-Mobile-Ausbaustufe sollte also über 6 MiB LLC verfügen. Zwischen den Slices übernimmt ein 1-Terabyte-pro-Sekunde die Kommunikation zwischen den P-Kernen und den E-Kern-Clustern, zu dessen genauen Aufbau und zur Kommunikation der E-Cores untereinander gibt es aber noch keine Informationen.
 Quelle: Intel
Alder-Lake-CPUs lassen sich aus einem Baukastenszstem zusammenstellen, offiziell plant Intel bislang aber nur die drei gezeigten Chip-Konfigurationen, aus denen weitere Prozessormodelle durch (Teil-)-Deaktivierungen abgeleitet werden.
Quelle: Intel
Alder-Lake-CPUs lassen sich aus einem Baukastenszstem zusammenstellen, offiziell plant Intel bislang aber nur die drei gezeigten Chip-Konfigurationen, aus denen weitere Prozessormodelle durch (Teil-)-Deaktivierungen abgeleitet werden.
Allen Alder Lake gemein ist die Unterstützung von PCI-Express 5.0, im Falle des i9-12900K auf 16 Lanes zuzüglich viermal PCI-E 4.0 und einem noch geheimen DMI-Interface. Der neue DDR-Controller unterstützt im Desktop offiziell DDR4-3200 oder DDR5-4800, während die in ihrer Performance nicht 1:1 vergleichbaren "LP"-Gegenstücke für Notebooks sogar bis -4266 respektive -5200 spezifiziert werden. Gerade Geräte, die sich auf ihre IGP verlassen, dürften von dem rund 50 Prozent höheren Datendurchsatz profitieren, aber weiterhin nicht über das Niveau dedizierter Einsteiger-GPU hinauskommen. Wie gewohnt werden diese Basis-Chips auch beschnitten, also mit weniger aktiven Einheiten angeboten, aber über etwaige weitere Silizium-Ausführungen aus getrennter Fertigung möchte Intel vorerst nicht sprechen. Trotzdem sollen von der 9- bis zur 125-W-TDP-Klasse alle Märkte bedient werden, wobei der Alder-Lake-Vollausbau von Intel bereits als "Enthusiast"-Produkt bezeichnet wird, preislich also eher in die Fußstapfen der LGA2066- denn der LGA1200-Core-i9 treten wird.
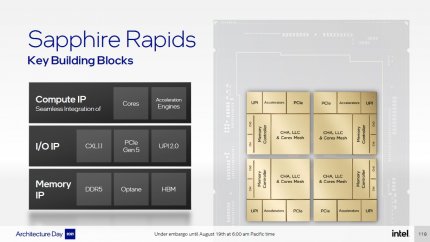
Sapphire Rapids: Der große Bruder von Alder Lake
 Quelle: Intel
Zusammengeklebte Prozessoren mit verteilten CPU-Kernen hat Intel schon in der zweiten Pentium-D-Generation verkauft. Bislang krankten alle diese Ansätze am Datenaustausch zwischen den Chips – Sapphire Rapids soll sich dagegen wie ein Monolith verhalten.
Alder Lake verspricht zwar große Fortschritt für Intel und vielleicht auch für Desktop-Anwender insgesamt. Im Workstation oder gar Server Markt, wo gut parallelisierbare Aufgaben vorherrschen, sieht man mit 8+8 Kernen aber kein Land mehr, AMD verkauft schließlich schon 64-Kerner. Denen stellt Intel ab Anfang 2022 Sapphire Rapids entgegen. Bis auf einen vergrößerten L2-Cache (2 MiB), aktives AVX512 und den neuen AMX-Befehlssatz zur Beschleunigung von Datenbanken übernimmt dieser die P-Cores von Alder Lake. Viermal so viele E-Cores wäre zwar für Microservice-Server naheliegender, unterstützen aber eben nicht die bei Xeons schon lange üblichen und durchaus auch genutzten Befehlssätze. Spannender als die Kernarchitektur ist aber der Aufbau von Sapphire Rapids. Ähnlich wie AMD in der ersten Threadripper-/Epyc-Generation setzt Intel nämlich auf vier getrennte, gleich aufgebaute Silizium-Chips. Das heißt jeder Teil-Chip trägt neben einer noch nicht veröffentlichten Anzahl von Kernen einen Dual-Channel-DDR5-Controller (insgesamt also acht Speicherkanäle), Schnittstellen für je ein HBM-Modul, dass wahlweise als Zusätzlicher RAM oder als Software-transparenter L4-Cache dient, sowie eine gewisse Zahl von PCI-Express-5.0-Lanes. Zusätzlich verbaut Intel einige Co-Prozessoren, die die eigentlichen CPU-Kerne unter anderem von Verwaltungsaufgaben befreien sollen.
Quelle: Intel
Zusammengeklebte Prozessoren mit verteilten CPU-Kernen hat Intel schon in der zweiten Pentium-D-Generation verkauft. Bislang krankten alle diese Ansätze am Datenaustausch zwischen den Chips – Sapphire Rapids soll sich dagegen wie ein Monolith verhalten.
Alder Lake verspricht zwar große Fortschritt für Intel und vielleicht auch für Desktop-Anwender insgesamt. Im Workstation oder gar Server Markt, wo gut parallelisierbare Aufgaben vorherrschen, sieht man mit 8+8 Kernen aber kein Land mehr, AMD verkauft schließlich schon 64-Kerner. Denen stellt Intel ab Anfang 2022 Sapphire Rapids entgegen. Bis auf einen vergrößerten L2-Cache (2 MiB), aktives AVX512 und den neuen AMX-Befehlssatz zur Beschleunigung von Datenbanken übernimmt dieser die P-Cores von Alder Lake. Viermal so viele E-Cores wäre zwar für Microservice-Server naheliegender, unterstützen aber eben nicht die bei Xeons schon lange üblichen und durchaus auch genutzten Befehlssätze. Spannender als die Kernarchitektur ist aber der Aufbau von Sapphire Rapids. Ähnlich wie AMD in der ersten Threadripper-/Epyc-Generation setzt Intel nämlich auf vier getrennte, gleich aufgebaute Silizium-Chips. Das heißt jeder Teil-Chip trägt neben einer noch nicht veröffentlichten Anzahl von Kernen einen Dual-Channel-DDR5-Controller (insgesamt also acht Speicherkanäle), Schnittstellen für je ein HBM-Modul, dass wahlweise als Zusätzlicher RAM oder als Software-transparenter L4-Cache dient, sowie eine gewisse Zahl von PCI-Express-5.0-Lanes. Zusätzlich verbaut Intel einige Co-Prozessoren, die die eigentlichen CPU-Kerne unter anderem von Verwaltungsaufgaben befreien sollen.
 Quelle: Intel
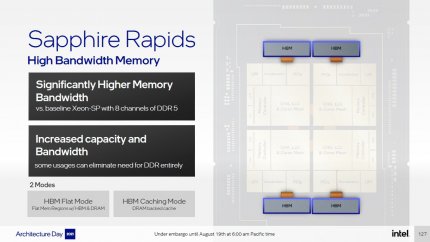
DDR5 (achtmal), HBM (viermal), diverse Co-Prozessoren und natürlich Kerne auf Alder-Lake-P-Niveau: Auch bei den Servern bläst Intel zum Angriff.
Das eigentlich Highlight ist aber die Verbindung der einzelnen Silizium-Kacheln untereinander mit EMIB-Links. Während die angesprochenen AMD-Prozessoren zeitlebens daran krankten, dass Zugriffe über den Speicher-Controller eines anderen Teil-Chips deutlich langsamer erfolgten als auf den lokalen, sollen in Sapphire Rapids alle Kerne auf allen Kacheln nicht nur alle I/O-Controller gleichberechtigt nutzen können, sondern sogar auf den gesamten L3-Cache mit hoher Datentransferrate und gleichbleibend niedriger Latenz zugreifen können. Der gesamte Prozessor hätte somit sämtliche Fertigungs-Vorteile von AMDs "Chiplet"-Strategie, zusätzlich aber auch die Performance-Vorteile der bisherigen, monolithischen Intel-Designs. Leider machte Intel erneut keine Angabe, ob es auch Sapphire-Rapids-Ableger mit zwei Kacheln geben wird, die den High-End-Desktop oberhalb von Alder Lake mit einer eigenen Plattform bedienen könnten.
Quelle: Intel
DDR5 (achtmal), HBM (viermal), diverse Co-Prozessoren und natürlich Kerne auf Alder-Lake-P-Niveau: Auch bei den Servern bläst Intel zum Angriff.
Das eigentlich Highlight ist aber die Verbindung der einzelnen Silizium-Kacheln untereinander mit EMIB-Links. Während die angesprochenen AMD-Prozessoren zeitlebens daran krankten, dass Zugriffe über den Speicher-Controller eines anderen Teil-Chips deutlich langsamer erfolgten als auf den lokalen, sollen in Sapphire Rapids alle Kerne auf allen Kacheln nicht nur alle I/O-Controller gleichberechtigt nutzen können, sondern sogar auf den gesamten L3-Cache mit hoher Datentransferrate und gleichbleibend niedriger Latenz zugreifen können. Der gesamte Prozessor hätte somit sämtliche Fertigungs-Vorteile von AMDs "Chiplet"-Strategie, zusätzlich aber auch die Performance-Vorteile der bisherigen, monolithischen Intel-Designs. Leider machte Intel erneut keine Angabe, ob es auch Sapphire-Rapids-Ableger mit zwei Kacheln geben wird, die den High-End-Desktop oberhalb von Alder Lake mit einer eigenen Plattform bedienen könnten.
Intel Architecture Day 2021: Fazit
 Quelle: Intel
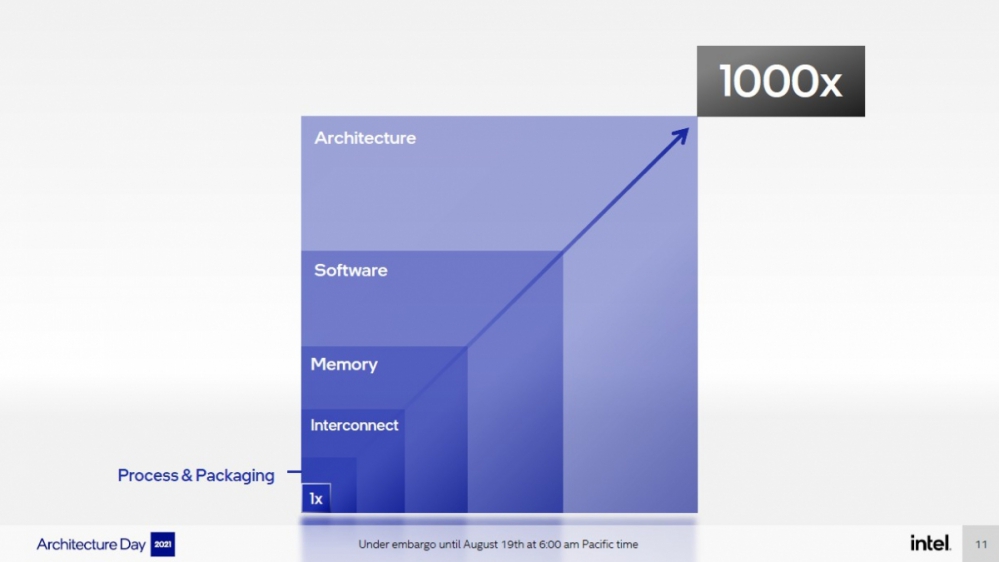
Fun fact: Seit mindestens einem halben Jahrzehnt gibt es zu jeder neuen AMD-Generation das Gerücht, es käme eine Variante mit HBM als Onboard-RAM. Stattdessen bringt Intel schon den zweiten x86-Prozessor (nach Kaby Lake G) mit diesem Feature.
Offiziell fokussierte sich Intels jüngstes Event auf den Aufbau von CPU-Kernen, den wir näher besprechen werden, sobald sich die Bedeutung der dort genannten Details besser einschätzen lässt. Angaben über Leistungsfähigkeit und Zusammenarbeit der Kerne in ganzen Prozessoren nahmen zwar einen großen Teil der Veranstaltung ein, waren als Begleitinformation aber oft lückenhaft und sollen erst zum Launch der jeweiligen Produkte vollständig veröffentlicht werden. Trotzdem ist absehbar, dass Intel großes vorhat - und das nicht nur, weil die bereits in den ersten Minuten eine Leistungssteigerung um den Faktor 1.000 bis 2025 versprochen wurde, denn diese bezog sich vermutlich eher auf die bislang wenig beeindruckenden Intel-GPU- und -HPC-Beschleuniger-Angebote. Aber auch Alder Lake könnte der große Wurf werden, der Intel verspricht. Nach über sechs Jahren 14-nm-Tippelschritten bringt allein der Fertigungswechsel einen ungewohnt großen Sprung und wandelt den seit 2019 bestehenden Fertigungsnachteil in einen Gleichstand mit AMD, bis ein Jahr später Zen 4 mit TSMC N5 die Karten neu mischt. Den Kern-Architekturen sowohl der E- als auch P-Cores merkt man unterdessen deutlich an, dass Intels Entwickler nicht Däumchen gedreht haben, während die Fertiger mit Trouble-Shooting beschäftigt waren. Aus Sicht der Desktop-Anwender bringt Alder Lake ein Jahr nach Comet Lake all die Fortschritte auf einmal, die eigentlich für zwei volle "Tocks" und zwei weitere, verfeinernde "Ticks" in Intels alten Roadmaps gedacht waren. Natürlich ist das Versprechen von 20 Prozent mehr Leistung als bei Rocket Lake zuzüglich eines kompletten Comet-Lake-Mobile-Achtkerners als Co-Prozessor trotzdem mit Vorsicht zu genießen.
Quelle: Intel
Fun fact: Seit mindestens einem halben Jahrzehnt gibt es zu jeder neuen AMD-Generation das Gerücht, es käme eine Variante mit HBM als Onboard-RAM. Stattdessen bringt Intel schon den zweiten x86-Prozessor (nach Kaby Lake G) mit diesem Feature.
Offiziell fokussierte sich Intels jüngstes Event auf den Aufbau von CPU-Kernen, den wir näher besprechen werden, sobald sich die Bedeutung der dort genannten Details besser einschätzen lässt. Angaben über Leistungsfähigkeit und Zusammenarbeit der Kerne in ganzen Prozessoren nahmen zwar einen großen Teil der Veranstaltung ein, waren als Begleitinformation aber oft lückenhaft und sollen erst zum Launch der jeweiligen Produkte vollständig veröffentlicht werden. Trotzdem ist absehbar, dass Intel großes vorhat - und das nicht nur, weil die bereits in den ersten Minuten eine Leistungssteigerung um den Faktor 1.000 bis 2025 versprochen wurde, denn diese bezog sich vermutlich eher auf die bislang wenig beeindruckenden Intel-GPU- und -HPC-Beschleuniger-Angebote. Aber auch Alder Lake könnte der große Wurf werden, der Intel verspricht. Nach über sechs Jahren 14-nm-Tippelschritten bringt allein der Fertigungswechsel einen ungewohnt großen Sprung und wandelt den seit 2019 bestehenden Fertigungsnachteil in einen Gleichstand mit AMD, bis ein Jahr später Zen 4 mit TSMC N5 die Karten neu mischt. Den Kern-Architekturen sowohl der E- als auch P-Cores merkt man unterdessen deutlich an, dass Intels Entwickler nicht Däumchen gedreht haben, während die Fertiger mit Trouble-Shooting beschäftigt waren. Aus Sicht der Desktop-Anwender bringt Alder Lake ein Jahr nach Comet Lake all die Fortschritte auf einmal, die eigentlich für zwei volle "Tocks" und zwei weitere, verfeinernde "Ticks" in Intels alten Roadmaps gedacht waren. Natürlich ist das Versprechen von 20 Prozent mehr Leistung als bei Rocket Lake zuzüglich eines kompletten Comet-Lake-Mobile-Achtkerners als Co-Prozessor trotzdem mit Vorsicht zu genießen.
Intel arbeitet zwar diesmal nicht mit neuen Befehlssätzen und Spezialbeschleunigern, wird sich für die ersten Präsentationen aber sicherlich keinen Worst Case herausgesucht haben. Auch wurde bislang nicht verraten, wie viele der insgesamt 16 Kerne bei vertretbarer Leistungsaufnahme gleichzeitig mit voller Last arbeiten können. Aber selbst wenn Intel nur halb so viel Fortschritt bringt, wie suggeriert wird, könnte man AMDs 5950X schlagen. In Spielen möglicherweise sogar deutlich, denn bei latenzkritischen Anwendungen laufen AMDs 16-Kerner oft in Single-Core- oder in Fabric-Limits. Der große Fallstrick bei Alder Lake ist allerdings das Betriebssystem. Intels "hardware"-Scheduling kann letztlich nur die Datengrundlage für eine bestmögliche Threadverteilung liefern, umsetzen muss diese aber Microsoft








Das alles aber nichts mit der Forderung nach "nur P-Cores" zu tun. Die sind genau das, was man braucht, wenn man nicht weiter parallelisieren will oder kann. Ein gewissen Grad der Parallelisierung haben wir aber längst erreicht und der ermöglicht es, einige Berechnungen auf E-Cores auszulagern und so Ressourcen freizuschaufeln. Nur perfekte Parallelisierung und E-Core-only ist schlichtweg unmöglich. Sonst wären wir schon vier Jahre vor Ryzen auf 8-Core-Atoms umgestiegen.
Mir fällt da spontan keine ein.
Von gamedesign hab ich absolut keine Ahnung, das stimmt. Kannst du mir erklären welche einzelne Aufgabe an einem Spiel wie beispielsweise Battlefield unbedingt nur an sagen wir vier hauptthreads gebunden ist und sein muss? Was kann man absolut und unmöglich nicht aufteilen, so dass ein Spiel nicht auch noch von 64 threads so profitiert wie von vier auf acht? Warum nicht maps mit etlichen hunderten NPCs gleichzeitig? Warum nicht zwei parallele Instanzen eines Spiels und beide befeuern eventuell je eine GPU und in einer dritten wird es abgeglichen und zusammengefügt?
Wie gesagt, ich hab keine Ahnung davon was daran unmöglich sein könnte.
Genauer gesagt: Wenn es so funktioniert im Sinne von auch auf dem Bildschirm ankommt, ist das zwar okay, aber nicht der Weg den ich für richtig halte. Schon seit Jahren stört mich diese Entwicklung. Ich will keine CPUs die es möglich machen dass weiterhin wie beispielsweise in deinem Szenario nur vier Main threads beansprucht werden. Selbst bei so alten und simplen Schinken wie Starcraft 2 hätte man schon für jede Fraktion einen eigenen Kern mit selbstständiger KI belegen können. Das wäre bei shootern beispielsweise eine Option. Jede Klasse von NPC-Gegner bekommt eine eigene "Anwendung". Wasser, Wind, Vegetation, alles könnte! selbstständig arbeiten. Das scheuen die entwickelt aber. Nur ist der einzige Weg um sie dazu zu bewegen eben, dass sie es müssen. Gibt man ihnen aber Auswege, dann wird so etwas noch ewig dauern.
Ich persönlich (und damit meine ich wirklich nur mich und spreche nicht für andere), würde mir so eine Entwicklung aber wünschen. Mir passiert diesbezüglich zu wenig. Ich möchte nicht dass die CPU Hersteller CPUs bauen die es den Entwicklern leichter macht beim alten zu bleiben und auf ersten benches super aussehen. Ich möchte dass sie CPUs bauen die jeder Situation gewachsen und nicht auf eine besondere Ansprache (sheduler) angewiesen sind.
Ich weiß selbst, dass dies einfältig klingt und viel Kopfschütteln hervorruft. Allerdings meine ich eben, dass wir aktuell den falschen Weg gehen.
Ich hoffe das es Ende Oktober nicht nur eine konkrete Ankündigung gibt, mit allen Eckdaten und Releasedatum, sondern auch schon erste Tests
Beispiel: Die P-Cores sollen +20 Prozent gegenüber Cypress-Cove bieten. Der wiederum ist (11900K vs. 10700K) in Spielen 15 Prozent schneller als Skylake. Das zwei P-Cores haben die Leistung von 2,8 Skylake-Kernen auf der Grundfläche von zwei Skylake-Kernen. Der gleiche Platz soll aber für zwei E-Core-Quads mit JEWEILS der Leistung von zwei Skylake-Kernen PLUS 80 Prozent reichen. Also zusammengenommen die Leistung von 7,2 Skylake-Kernen.
Es bleibt abzuwarten, wie gut Intels versprechen aufgehen, wenn die ganzen Kerne auch zusammenarbeiten, aber rein von der Rohrechenleistung gilt auch für Gamer: Soviel P-Cores wie nötig, soviel E-Cores wie möglich. Eine 4+24-Konfiguration wäre beispielsweise genauso groß, wie die geplante 8+8, hätte aber 50 Prozent mehr Leistung. Und solange die Anwendung nicht mehr als vier "Big"-Threads spawnt, könnte sie die Kerne auch auslasten.