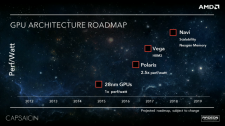
Navi: Vega 10 könnte AMDs letzte große GPU sein

Vega 10 ist mit einer Chipfläche von 484 mm² eine der größeren GPUs, die AMD in den vergangenen Jahren hergestellt hat. Und es könnte die letzte große GPU in absehbarer Zukunft sein (abgesehen vom kolportierten reinen HPC-Ableger Vega 20). Dahingehend lassen sich jedenfalls die Informationen zu AMDs Vega-Nachfolgerarchitektur Navi zusammenfassen, die mehrere kleine Chips zu einer großen GPU vereinen könnte.
Im Prozessorbereich hat AMD mit dem Zusammenspiel aus Infinity-Fabric-Interconnect und dem Zeppelin-Die einen großen Coup gelandet: Mit nur einem einzigen Die lässt sich das komplette CPU-Portfolio von Vier- bis 32-Kernern abdecken, wobei die Fertigungskosten vergleichsweise gering und die Ausbeute hoch ausfallen dürften. Achtkerner lassen sich nativ mit einem Siliziumchip realisieren, für Sechs- und Vierkerner werden Teile deaktiviert. Für Ryzen Threadripper und Epyc hingegen werden zwei beziehungsweise vier Dies als Multi-Chip-Modul zusammengefasst.
Spekulationen gehen schon lange dahin, dass AMD diese Taktik künftig auch im GPU-Bereich einsetzen könnte. Grundlage dafür stellt AMDs Roadmap dar, die unter dem Vega-Nachfolger Navi den Kernpunkt "Skalierbarkeit" nannte. Der Infinity Fabric kommt bereits bei Vega 10 und den Raven-Ridge-APUs zum Einsatz, um die unterschiedlichen IP-Blöcke miteinander zu verbinden. AMD bestätigte, dass der Interconnect auch die Möglichkeit schaffe, mehrere Dies zu einer GPU zu vereinen - analog zu Ryzen Threadripper und Epyc.
Die Radeon Vega Frontier Editions und AMDs Vorabinformationen zur Radeon RX Vega 64 zeigen, dass die Ressourcen knapp sind, um eine weitgehend überarbeitete Architektur in einer GPU zu realisieren und das Software-Ökosystem entsprechend anzupassen. AMD selbst sieht sich nur auf dem Niveau einer Geforce GTX 1080, die schon vor über einem Jahr erschien. Vega 11 und weitere Ableger lassen noch länger auf sich warten. Ebenso vertröstete AMD auf bessere Treiber, die die Vega-Features in Zukunft ausnutzen werden.
Mit Multi-Chip-Designs könnte AMD mehrere Fliegen mit einer Klappe schlagen. Die Entwicklungskosten von einem, vielleicht zwei Grafikchips hielten sich in Grenzen. Ein komplettes Grafikkartenportfolio ließe sich über einen kurzen Zeitraum realisieren, ohne allzu großen Validierungsaufwand betreiben zu müssen. Und die Fertigungskosten wären geringer, womit sich AMD aggressiver am Markt positionieren könnte (s. Preislage von Ryzen). Zudem könnte AMD größere Verbünde bauen, als sie monolithisch als einzelner Chip machbar wären. Das Risiko, ein finanziellen Flop auf den Markt zu bringen, der Entwicklungs- und Fertigungskosten nicht wieder einspielt, würde minimiert.
Ein großes Aber gibt es jedoch. Die Treiberarbeit ist nicht zu unterschätzen, um mehrere Grafikchips als eine große GPU anzusprechen. Ob das überhaupt vollumfänglich funktioniert, muss auch erst einmal bewiesen werden.
Quelle: pcgamesn.com








Ich glaube, von den multiplen Chips auf NV1-Karten war nur einer für die 3D-Bearbeitung zuständig. Aber zusammen mit dem 3dfx-Altlasten sollte Nvidia die Voodoo-1- und -2-Details eingekauft haben. Bei denen arbeiteten tatsächlich zwei respektive drei Chips am Rendering mit.
hab da aber eine andere Idee....
Wie wäre das mit stacking, a la HBM?
Evtl hat sich AMD ja auch deswegen so früh für HBM interessiert?!
Wäre sowas überhaupt möglich zu realisieren?
Wären die Latenzen dann nicht erheblich besser?
Ich hab keine Ahnung, nur ne idee^^
Ist es eine Technologie die Nvidia nicht zur Verfügung hat? Nein, Infinity-Fabric hat weder Intel noch Nvidia. Die Inter-Chip-Kommunikation können beide nicht bzw. aktuell (scheinbar) nicht gut genug. OB Nvidia da eventuell schon was fertig entwickelt hat, das in der nächsten Generation aufschlägt... keine Ahnung. Nix bekannt. Aber AMD hat und kann.
HMC hat ein gewisses Imageproblem, denn als jenes fertig war, war GDDR5 auch nicht mehr langsamer. Folglich war jener zu dem Zeitpunkt nur teurer für den Einsatz in Grafikkarten. Der Nachfolger HMC2 hat dasselbe Problem mit einer Bandbreite von maximal 480GB/s - es braucht also quasi ein MCM um HMC wirklich interessant zu machen
Der HM-RAM von Knight's Landing ist übrigens kein vollwertiger HMC. Details sind leider nicht bekannt, es gibt aber Spekulationen das Intel auf den Basis-Logik-Die verzichtet und nur die für HMC entwickelten Speicher-Dies als stacked DRAM nutzt. Das wäre deutlich billiger und für einen (Single-)GPU-ähnlichen Beschleuniger angemessen, aber die entscheidenden Vorteile des Hybrid-Konzeptes (Speicher + Logik) einschließlich der Netzwerk-Option gingen verloren.
Ja wie oft denn noch? Natürlich haben beide ein Bus-system zur Verfügung. Das ist ja jetzt keine neue, revolutionäre Erfindung von AMD.
http://extreme.pcgameshar...
Natürlich hat Intel sowas schon längst, solche Verbindungen gibts, seit es Computer gibt. Dass AMD dafür einen neuen Namen einführt ist auch nix besonderes.
Und AMD "hat und kann" nicht. Mit der aktuellen Version ihres tollen IF "hat" man weder, noch "kann" man damit GPUs so verbinden wie es sinnvoll wäre.
Das wurde hier jetzt auch schon 10x besprochen, ich weiß nicht warum man wieder von vorne anfangen muss...
NV1 - Wikipedia
Bei der Überschrift ist erstmal mein Herz stehengeblieben!
Aber der Text... hats dann gerettet! Finde die skalierbaren Produkte vom AMD echt gut, sieht man ja jetzt bei Zen.
Wenn AMD das so bei den GPUs hinkriegt, das wäre schon der Hammer. Man sollte nur ein gutes halbes bis dreiviertel Jahr auf das von AMD gegebene Release draufrechnen.
Ich sehe es schon kommen, dass NVIDIA in ein paar Jahren dagegen wettert, dass AMD seine Chips "zusammenklebt" xD
HMC hat ein gewisses Imageproblem, denn als jenes fertig war, war GDDR5 auch nicht mehr langsamer. Folglich war jener zu dem Zeitpunkt nur teurer für den Einsatz in Grafikkarten. Der Nachfolger HMC2 hat dasselbe Problem mit einer Bandbreite von maximal 480GB/s - es braucht also quasi ein MCM um HMC wirklich interessant zu machen