BB Cube 3D: Neuer Speicher soll viermal so schnell wie HBM2e sein

Eine neue Speichertechnologie namens BB Cube 3D soll gleichzeitig deutlich schneller und effizienter als HBM2e sein. Möglich wird das durch einen gestapelten Aufbau mit zahlreichen TSV-Verbindungen. Eine direkte Umsetzung als Produkt ist aber offenbar leider nicht geplant.
Forscher des Tokyo Institute of Technology haben eine neue Speichertechnologie vorgestellt, die bisherige Ansätze deutlich überflügeln soll. BB Cube 3D, kurz für Bumpless Build Cube 3D, soll sowohl schneller als auch effizienter als der aktuell verfügbare HBM2e sein. Die neue Technik soll sich dabei für alle Arten von Rechenchips eignen, also unter anderem auch für CPUs und GPUs.
Deutliche Vorteile
Besonders an BB Cube 3D ist der extensive Einsatz von Through-Silicon-Vias (TSVs), die Daten durch jeweils eine Silizium-Ebene leiten. Bei der Technik werden zahlreiche Chips gestapelt und offenbar direkt über kaskadierte TSVs miteinander verbunden. Eine klassische Verlötung zwischen den einzelnen Chips entfällt dabei.
 Quelle: Tokyo Institute of Technology
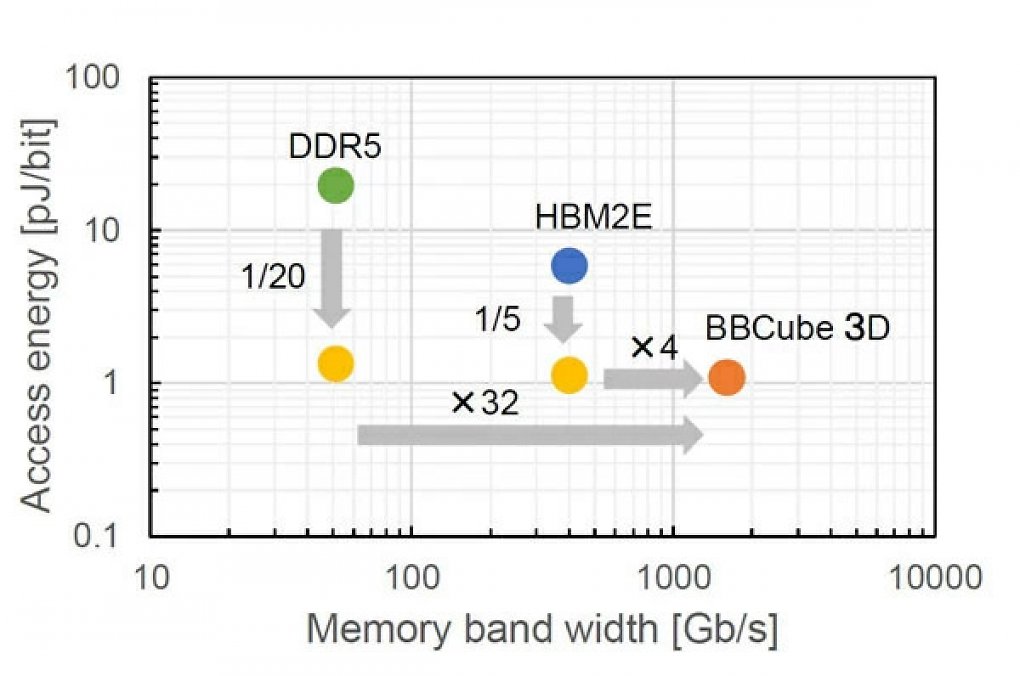
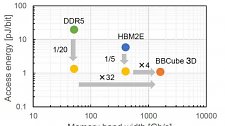
BB Cube 3D bietet angeblich die vierfache Geschwindigkeit von HBM2e bei einem Fünftel des Energieverbrauchs.
Zusammen mit einem optimierten Ansprechmuster der Verbindungslinien konnte so offenbar eine deutlich höhere Übertragungsgeschwindigkeit als bisher erzielt werden. Stapelt man den BB-Cube-3D-Speicher auf einem Cache-Chip, der wiederum auf der CPU/GPU sitzt, soll im Extremfall die vierfache Bandbreite von HBM2e möglich sein. Gegenüber DDR5-Speicher wäre die neue Technologie sogar 32 Mal so schnell. Gleichzeitig soll zudem der Energieverbrauch sinken: von DDR5 aus auf ein Zwanzigstel, und aus Sicht von HBM2e auf ein Fünftel.
Quelle: Tokyo Institute of Technology
BB Cube 3D bietet angeblich die vierfache Geschwindigkeit von HBM2e bei einem Fünftel des Energieverbrauchs.
Zusammen mit einem optimierten Ansprechmuster der Verbindungslinien konnte so offenbar eine deutlich höhere Übertragungsgeschwindigkeit als bisher erzielt werden. Stapelt man den BB-Cube-3D-Speicher auf einem Cache-Chip, der wiederum auf der CPU/GPU sitzt, soll im Extremfall die vierfache Bandbreite von HBM2e möglich sein. Gegenüber DDR5-Speicher wäre die neue Technologie sogar 32 Mal so schnell. Gleichzeitig soll zudem der Energieverbrauch sinken: von DDR5 aus auf ein Zwanzigstel, und aus Sicht von HBM2e auf ein Fünftel.
Auch spannend: Micron: GDDR7-Speicher für 2024 und Next-Gen-GPUs angekündigt
Auf dem Papier liest sich BB Cube 3D damit hervorragend. Eine Produktion ist aber offenbar nicht geplant, es scheint sich rein um ein Entwicklungsprojekt zu handeln, das die Forschung vorantreiben soll. Vermutlich dürften die großen Speicherhersteller für die Zukunft aber bereits an ähnlichen Lösungen arbeiten. Das zunehmende Stapeln von Speicher- auf Rechenchips wird schließlich schon länger prognostiziert und beispielsweise mit AMDs X3D-Prozessoren inzwischen auch in ersten Schritten umgesetzt.
Quelle: Tokyo Institute of Technology via Tom's Hardware









a) "in diesen Zeiten" ... impliziert was anderes als das, worum es der Industrie hier geht. Hier wird zwar eingespart aber nur in relativem Sinne, nicht im absoluten, denn die Einsparungen helfen noch größere Datacenter-/HPC-Designs zu entwickeln.
b) Das "1 TB/s" in Verbindung mit dem "auch" passt hier nicht. Die Forscher prognostizieren hier bis zur vierfachen Bandbreite von HBM2E, d. h. das geht weit über die Bandbreite von HBM3E hinaus.
c) Jedoch nur als Anmerkung: Der Link/die News von Igor ist schon eher eine Nicht-News bzw. überflüssig, denn selbstredend beobachtet nVidia als einer der größten HBM-Abnehmer die Marktentwicklung sehr genau, zumal nVidia mit Hopper schon längst HBM3 nutzt.
Ergänzend zum Artikel: Der abschließende Vergleich mit AMDs ist eher schlecht gewählt. Hier geht es um sogenannten Near-Memory und die damit einhergehenden Einsparungsmöglichkeiten/Effizienzsteigerungen. AMD bietet hier derzeit lediglich eine marginale Cache-Erweiterung, die noch dazu oben auf den Die gestapelt wird und nur in einer Lage. Etwas zumindest halbwegs in diese Richtung gehendes als reales Produkt ist aktuell bestenfalls Intels SPR Max mit 64 GB HBM2E. Ergänzend könnte man die PIM-Designs der Speicherhersteller als eine Art Vorläufer erwähnen, so die entsprechenden HBM-Varianten *), die durch das Zusammenbringen von Recheneinheiten und dem DRAM beträchtliche Effizienzvorteile mit sich bringen, auch wenn es sich bei den PIM-Designs vorerst um sehr spezifische Designs handelt, die (nahezu) ausnahmslos auf ML-Workloads abzielen und damit primär MMA-Funktionalität implementieren.
*) Auch GDDR-PIM-Designs für günstigere Anwendungszwecke sind in Arbeit, daher die Abgrenzung.
PIM steht hierbei für Process In Memory, d. h. inkl. Funktionseinheiten, die sehr nahe beim dazugehörigen Speicher liegen, sodass hier die Bit-Zugriffskosten sowie die Latenz drastisch sinken.
Andere Hersteller geben dem Kind einen etwas anderen Namen, so SK Hynix bspw. als AIM für Accelerator In Memory, letzten Endes aber das gleiche Prinzip, also MMA-Einheiten direkt im Speichermodul.
1 TB/s soll auch der neue HBM3e schaffen/können.
[Ins Forum, um diesen Inhalt zu sehen]