Kampf der Giganten: Neuer Benchmark vergleicht Nvidias H100 mit AMDs MI300X

In einem neuen Benchmark wird die KI-Performance von Nvidias H100 mit der von AMDs MI300X verglichen. Trotz einer deutlich höheren Transistoranzahl kann sich AMDs gigantischer Chip dabei nicht vom Konkurrenzmodell absetzen.
Für Gaming-Grafikkarten gibt es glücklicherweise eine Vielzahl an unabhängigen Tests, die den Pixelbeschleunigern in den verschiedensten Disziplinen auf den Zahn fühlen. Im Datacenter-Bereich ist der Überblick, zumindest für Außenstehende, hingegen weniger gut. Proprietäre Software ist häufiger verbreitet und sorgt teils für Kompatibilitäts- oder Performance-Probleme. Trotzdem gibt es aber natürlich auch dort Benchmark-Resultate, mit denen verschiedene GPU-Beschleuniger verglichen werden. Und ein ebensolches wurde kürzlich vom KI-Konsortium ML Commons präsentiert.
Fast identisch
Das Konsortium hat soeben den neuen Benchmark ML Perf Inference 4.1 veröffentlicht, der die Leistung im Ausführen von KI-Modellen ermitteln soll. Getestet wurden dabei verschiedene, fertig verfügbare Server. Gleichzeitig gibt es aber auch einen direkten Vergleich von Nvidias KI-Beschleuniger H100 und dem Konkurrenzmodell von AMD, der MI300X. Auf dem Papier sind beide Chips dabei recht unterschiedlich.
Nvidias GPU kombiniert 80 Milliarden Transistoren in TSMCs 5-nm-Prozess auf einer Fläche von 814 mm². Im genutzten Server wurden acht der KI-Beschleuniger mit einer TDP von je 350 W betrieben. Bei AMD kamen ebenso acht Beschleuniger zum Einsatz, unter den riesigen GPUs ist die MI300X aber noch etwas gigantischer. Bei ihr finden 153 Milliarden Transistoren auf 1.017 mm² Platz - ebenso in TSMCs 5-nm-Prozess. Passend zur fast verdoppelten Transistorzahl ist dabei auch die TDP deutlich höher - sie liegt bei 750 Watt.
 Quelle: ML Commons
Bei der Ausführung des LLaMa-2-Modells mit 70 B Parametern befinden sich die gigantischen KI-Beschleuniger grob auf Augenhöhe.
Quelle: ML Commons
Bei der Ausführung des LLaMa-2-Modells mit 70 B Parametern befinden sich die gigantischen KI-Beschleuniger grob auf Augenhöhe.
 Quelle: ML Commons
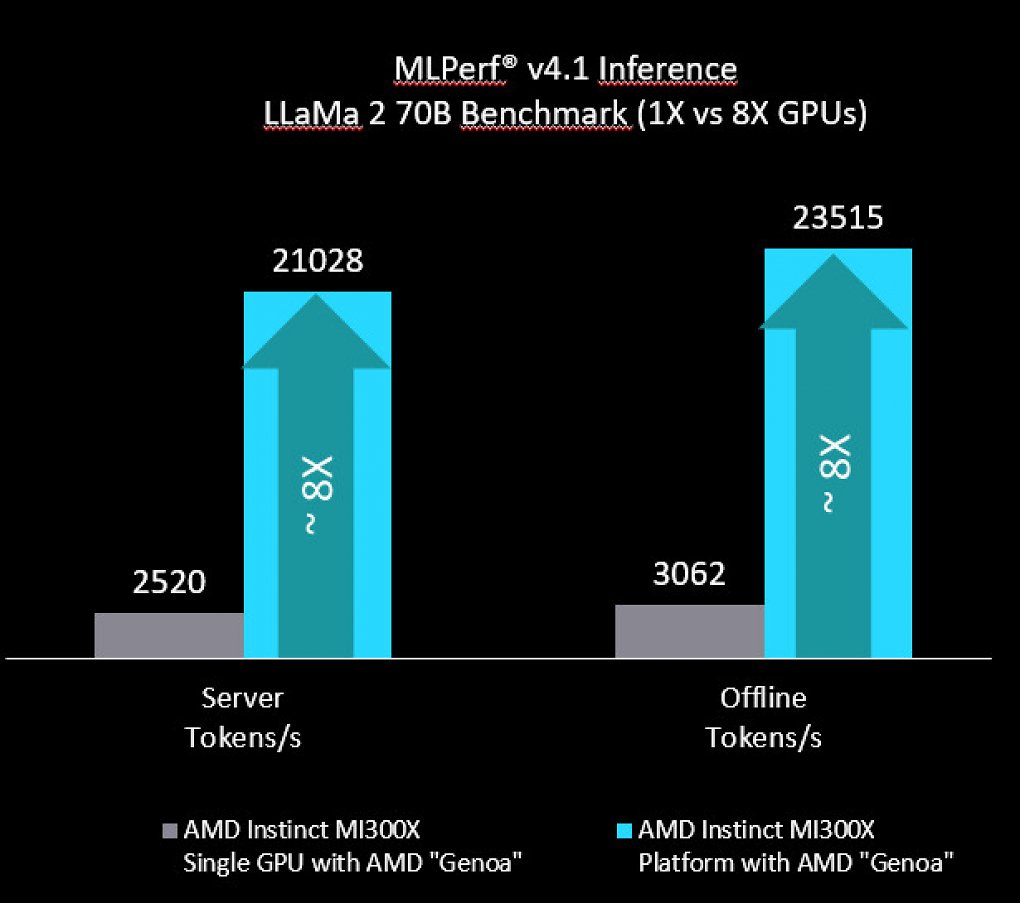
Mit der Skalierung hat AMDs MI300X offenbar kein Problem. Im Vergleich zwischen einer und acht GPUs steigt die Leistung fast linear.
In dem veröffentlichten Benchmark kann diese zusätzliche, theoretische Rechenleistung aber nicht in praktische Resultate umgemünzt werden. Im KI-Modell LLaMA2-70B agieren beide Systeme grob auf Augenhöhe. Zumindest in diesem Szenario scheint es also weiterhin Auslastungsprobleme zu geben. Passende Verbrauchswerte, die das womöglich bestätigen könnten, wurden dabei leider nicht veröffentlicht.
Quelle: ML Commons
Mit der Skalierung hat AMDs MI300X offenbar kein Problem. Im Vergleich zwischen einer und acht GPUs steigt die Leistung fast linear.
In dem veröffentlichten Benchmark kann diese zusätzliche, theoretische Rechenleistung aber nicht in praktische Resultate umgemünzt werden. Im KI-Modell LLaMA2-70B agieren beide Systeme grob auf Augenhöhe. Zumindest in diesem Szenario scheint es also weiterhin Auslastungsprobleme zu geben. Passende Verbrauchswerte, die das womöglich bestätigen könnten, wurden dabei leider nicht veröffentlicht.
Auch interessant: Neues zu RDNA 4: Vier GPU-Varianten und drei Speicherkonfigurationen [Gerücht]
Allzu lang dürften sich die beiden genannten KI-Beschleuniger aber wohl ohnehin nicht mehr duellieren - zumindest nicht an der Spitze. Denn dort dürften bei Nvidia bald die neuen Blackwell-GPUs nachrücken, während AMD 2025 mit der MI350 antworten will. Trotz des ähnlichen Namens ist für diese dabei der Einsatz einer neuen Compute-Architektur geplant. Ob es AMD mit dieser gelingen wird, im KI-Bereich weiter zu Nvidia aufzuschließen, bleibt abzuwarten.
Was erwarten Sie von Blackwell und AMDs MI350? Nutzen Sie die Kommentarfunktion und teilen Sie uns Ihre Meinung mit. Zum Kommentieren müssten Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie noch keinen Account haben, könnten Sie über eine Registrierung nachdenken, die viele Vorteile mit sich bringt. Beachten Sie beim Kommentieren aber bitte die gültigen Forenregeln.
Quelle: ML Commons via Techpowerup









Ja..zur Kenntnis genommen.