HBM-Speicher: Auch Micron steigt ein, noch 2020 erste Produkte
Während der Bekanntgabe der Quartalszahlen hat Micron auch einen knappen Ausblick auf die kommenden Produkte des Unternehmens gegeben. Demnach will Micron 2020 endlich die Konkurrenz zu Samsung und SK Hynix aufnehmen und ebenso HBM-Speicher auf den Markt bringen.
Der Markt für RAM-Chips wird derzeit hauptsächlich von drei großen Unternehmen unter sich aufgeteilt: Samsung, SK Hynix und Micron. Die Produktpaletten sind dabei oft vergleichbar: Beispielsweise bieten alle drei Unternehmen DDR4- und GDDR6-Speicherchips an. Bei einem Speicherstandard gibt es aber bislang nur zwei Produzenten: HBM wird nur von Samsung und SK Hynix produziert, Micron bietet derzeit keine entsprechenden Chips an.
Micron endlich mit HBM statt HMC
Genau das soll sich nun aber ändern, wie das Unternehmen bei der Bekanntgabe der aktuellen Quartalszahlen ankündigte. Mit Hinblick auf den Entwicklungsfortschritt im zweiten Quartal verkündete das Unternehmen, derzeit die ersten DDR5-Chips zu samplen und auf gutem Wege zu sein, noch 2020 erste HBM-Chips anzubieten. Eine genauere Zeitangabe fehlt aber leider, und auch technische Daten bleibt das Unternehmen schuldig.
"In FQ2, we began sampling 1Z-based DDR5 modules and are on track to introduce high-bandwidth memory in calendar 2020. We are also making good progress on our 1-alpha node."
Mit Micron werden Ende des Jahres dann endlich alle drei großen Speicherhersteller HBM-Chips anbieten, was der Verfügbarkeit und somit dem Preis zugute kommen dürfte. Mit beidem hatten diverse Consumer-Produkte wie AMDs Fiji-Grafikkarten zu kämpfen, sodass HBM zumindest vorerst nur noch im professionellen Bereich zu finden ist.
Passend zum Thema: Samsung kündigt HBM2E mit bis zu 538 GB/s an
Warum Micron erst jetzt HBM-Produkte anbietet, liegt in der Geschichte des Standards begründet. HBM wurde von AMD und SK Hynix entwickelt und sollte eine schnellere, platz- und stromsparende Alternative zum GDDR-Speicher darstellen. In dieselbe Richtung ging Hybrid Memory Cube (HMC), das von Micron und Samsung entwickelt wurde.
Im Gegensatz zu HBM konnte sich HMC aber nicht wirklich durchsetzen, obwohl Micron recht lange an dem Speicherstandard festhielt. Erst 2018 kündigte das Unternehmen an, sich von HMC abzuwenden und sich fortan den Produktion von HBM-Speicher anzuschließen, wie es Samsung 2016 getan hat. Das Ergebnis dieser Entscheidung sehen wir jetzt.

 Einerseits Marge, andererseits der geringe Marktdruck für 16 GiB und zu guter Letzt noch der Umstand, dass die Verwendung von HBM eine entsprechend angepasste Architektur erfordert und damit meine ich nicht nur den Tausch der Speichercontroller. Typischerweise wird das ganze Cache-Subsystem einer solchen Architektur auf die Verwendung von HBM ausgelegt, die dementsprechend anders aussieht, als wenn sie für einen Betrieb zusammen mit GDDR6 konzipiert worden wäre.
Einerseits Marge, andererseits der geringe Marktdruck für 16 GiB und zu guter Letzt noch der Umstand, dass die Verwendung von HBM eine entsprechend angepasste Architektur erfordert und damit meine ich nicht nur den Tausch der Speichercontroller. Typischerweise wird das ganze Cache-Subsystem einer solchen Architektur auf die Verwendung von HBM ausgelegt, die dementsprechend anders aussieht, als wenn sie für einen Betrieb zusammen mit GDDR6 konzipiert worden wäre. ) aber
) aber







"Gibt natürlich x Gründe wieso es am Ende doch nur 384Bit 16-18Gbps für arme werden."
Da bedarf es tatsaächlich nicht viel.
Aktuell dürfte es für AMD diesbezüglich noch zu früh sein, denn die sind derzeit noch zu klein für derartige Anpassungen, insbeondere in einem Segment, in denen ihnen ein starker Wind entgegen bläßt und die Absätze/Marktanteile ungewiss sind (und aktuell eher klar zugunsten von nVidia tendieren). AMD wird für RDNA2 voraussichtlich nur ein Design abliefern und das wird dann die ganze Palette von (Low?), MidRange bis HighEnd abdecken und entsprechend voraussichtlich ausschließlich auf GDDR6 ausgelegt sein.
Hinzu kommt, dass AMD bereits ein zweites, komplett eigenständiges Design in der Entwicklung hat; das nennt sich CDNA und ist explizit auf das Datacenter (Instinct-Beschleunigerkarten) ausgelegt. Entsprechend dürfte AMD seine Ressourcen aktuell schon ausgeschöpft haben.
Bei nVidia wird es diesmal wohl etwas anders aussehen als zuletzt. Wenn man hier tatsächlich nur im Grunde eine Architetur präsentiert (aktuell ist immer nur von Ampere und GA-Chips die Rede). nVidia wird hier voraussichtlich bei den konkreten Chips differenzieren (wenn die bisher gerüchteweise in Umlauf gebrachten Namen denn korret sind) und den GA100 explizit für das Datacenter konzipieren und mit einem HBM-Interface ausstatten. Die kleineren Ampere-Chips werden auch hier voraussichtlich auf GDDR6 ausgelegt sein und für den Consumer- und Professional Vizualization-Markt verwendet werden.
Ich bin auf jeden Fall gespannt was es im Herbst bzw. 4Q20 werden wird auf beiden Seiten und hoffe natürlch auch, dass AMD im Consumer-Markt was konkurrenzfähiges auf die Beine stellen kann.
Ich verweise hier mal auf die letzten Gerüchte bzgl. NAVI 12 (Aka Navi 10 + HBM2 + deep learning capabilities) : Unknown Navi GPU with HBM2 to Feature Machine Learning Capabilities – AdoredTV
Die Chance das HBM2 beim (Top Dog) wirklich auch bei den Gaming-Grafikkarten Einzug halten wird würde ich allerdings auch nicht als allzu groß ansehen (<50%)
Bei Grafikkarten für die Apple Mac Pro Workstations bin ich mir allerdings zu >90% sicher das es RDNA2 Karten mit HBM2 eh geben wird.
Warum nicht Synergien schaffen wenn man für Apple eh einen Sonderweg fahren wird.
Alleine schon die Benötigte Menge an HBM2 die Apple, AMD (CDNA) und NVIDIA bei ihren kommenden Karten benötigen werden, sollte die Kosten
für HBM2 weiter in Richtung GDDR6 drücken, damit sollten auch gewisse Skaleneffekte möglich sein.
Gerade in Hinsicht das Micron dieses Jahr ebenfalls mit der Produktion von HBM2 beginnen wird und sich somit ein dritter Player am Spiel beteiligt sollte dem Preis förderlich sein.
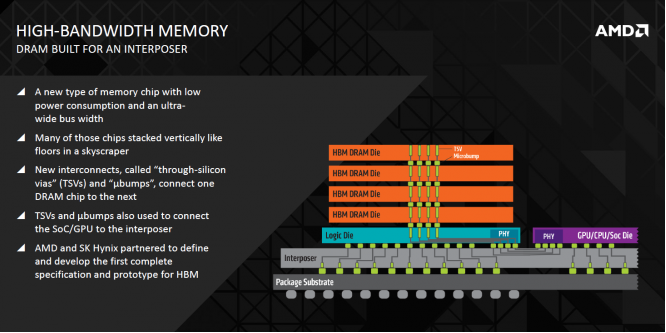
So nebenbei auch wenn es eher symbolisch ist, hat AMD mit SK-Hynix HBM entwickelt un d das eigene Baby ist einem doch am liebsten.
Für mich ist die Sache auf jeden Fall klar ohne HBM2 keine Performance Krone.
Mit einem 384 Bit Si wird man wohl auch weiterhin auf dem 2. Platz aushalten müssen.
Dabei hätten sie jetzt fast alle Trümpfe selbst in der Hand.
HBM2 zum jetzigen Zeitpunkt passt einfach wie die Faust aufs Auge.
[Ins Forum, um diesen Inhalt zu sehen]
Allein schon die Flächenersparnis um den Faktor 1.5-175 für den PHY Controller, würde Hochgerechnet in etwa der benötigten Fläche für die RT / Tensor cores entsprechen.
Bei der Energieerparnis wird man bei einem Kolportierten 500mm2 Chip wohl auch in etwa 50W im Vergleich zu einem 384Bit Si einsparen können.
Ausgehend von der next gen. XBox wo 56CU's inkl. RT auf ca. 300mm2 verbaut wurden würde ein 80CU unter der Annahme das sonst nichts verbessert wurde, lediglich einer Fläche von 429mm2 benötigen, bzw. mit HBM2 sogar nur ca. 400mm2.
Wenn man sich die Taktrate der PS5 und Xbox genauer ansieht sollten dabei ca. 2GHz realistisch sein.
Wie man sieht, könnten auf einer Fläche von 500mm2 auch locker 96 oder gar 112 CU's platz finden, allerdings ist es wohl doch am wahrscheinlichsten das es bei 80 relativ hochgetakteten (vorausgesetzt HBM2 da sonst nicht nötig) bleiben wird.
Bei 384 Bit GDDR6 können sie auch gleich wieder auf 1.5GHz runter takten, da eh das Si limitiert. (Hätte natürlich für eine solche Karte natürlich einen Verbrauch von < 200W zur Folge, was auch nicht schlecht wäre wenn man bedenkt das sie doch deutlich schneller als eine 2080ti wäre.
Die Frage wäre also was wird mit den restlichen ca. 100mm2 Die Fläche angestellt.
Nvidia benötigt z.B. eine Fläche von ca. 1.95mm2 pro TPC (tensor 1.25 / RT 0.7) ---> 10.89mm2 TU106 - 1.95mm2 = 8.94mm2 ---> +21.8% ----> x1.5 (Ampere???) ----> 32.7%
AMD (NAVI 10) Shader Engine WGP (20) 4.53mm2 (ohne RT / tensor cores für deep learning) ----> +32.5% (6.0mm2) bzw. 240mm2 bei 40WGP (80CUs)
+ gleichzeitig einer nahezu Verdoppelung des Frontends: L1 /L2 Chache ROPS .... um ca. 70% (L1/L2 x2???) ----> 93.2 auf 160mm2
Das hätte massive Verbesserungen zum bereits sehr performanten RDNA2 Derivat in der XBox / PS5 zur Folge. (240 + 160 + CPU command core 10mm2 + I/O 40mm2 = 450mm2 + SI (HBM2 ca. 50-60 / 384Bit ca. 100mm2)
Das alles mit einem 384Bit Si wo 18Gbps Speicher noch in der Schwebe stehen zu befeuern wäre als würde man Perlen vor die Säue werfen.
Klar NVIDIA könnte mit einem Salvage seines >800m2 konntern und wohl eher Symbolisch wieder die Performance-Krone einnehemen aber hat es NVIDIA so nötig dies zu tun (ich denke schon falls HBM2 kommen sollte
das teil wird so unnötig und überhaupt wie hoch will man denn 7000-8000 Shader takten wollen. Da kann man ja froh sein wenn sie am Ende überhapt noch 20% schneller als Ampere / Big Navi >5000 für den doppelten Preis ist.
"Gibt natürlich x Gründe wieso es am Ende doch nur 384Bit 16-18Gbps für arme werden."
Da bedarf es tatsaächlich nicht viel.
Aktuell dürfte es für AMD diesbezüglich noch zu früh sein, denn die sind derzeit noch zu klein für derartige Anpassungen, insbeondere in einem Segment, in denen ihnen ein starker Wind entgegen bläßt und die Absätze/Marktanteile ungewiss sind (und aktuell eher klar zugunsten von nVidia tendieren). AMD wird für RDNA2 voraussichtlich nur ein Design abliefern und das wird dann die ganze Palette von (Low?), MidRange bis HighEnd abdecken und entsprechend voraussichtlich ausschließlich auf GDDR6 ausgelegt sein.
Hinzu kommt, dass AMD bereits ein zweites, komplett eigenständiges Design in der Entwicklung hat; das nennt sich CDNA und ist explizit auf das Datacenter (Instinct-Beschleunigerkarten) ausgelegt. Entsprechend dürfte AMD seine Ressourcen aktuell schon ausgeschöpft haben.
Bei nVidia wird es diesmal wohl etwas anders aussehen als zuletzt. Wenn man hier tatsächlich nur im Grunde eine Architetur präsentiert (aktuell ist immer nur von Ampere und GA-Chips die Rede). nVidia wird hier voraussichtlich bei den konkreten Chips differenzieren (wenn die bisher gerüchteweise in Umlauf gebrachten Namen denn korret sind) und den GA100 explizit für das Datacenter konzipieren und mit einem HBM-Interface ausstatten. Die kleineren Ampere-Chips werden auch hier voraussichtlich auf GDDR6 ausgelegt sein und für den Consumer- und Professional Vizualization-Markt verwendet werden.
Ich bin auf jeden Fall gespannt was es im Herbst bzw. 4Q20 werden wird auf beiden Seiten und hoffe natürlch auch, dass AMD im Consumer-Markt was konkurrenzfähiges auf die Beine stellen kann.
Bei nVidia würde ich davon ausgehen, dass bestenfalls der GA100 auf HBM2 setzen wird und dieses Die wird voraussichtlich Datacenterprodukten vorbehalten bleiben. Wenn der GA102 zumindest auch auf den Consumer-Karten die vollen 384 Bit bietet, werden das hier 12 GiB GDDR6 werden, dann voraussichtlich mit etwas schnelleren 16 Gbps-BGAs, was die Speicherbandbreite einer möglichen 3080 Ti ggü. einer 2080 Ti um rd. +25 % steigert. *)
Beispielsweise zur Vega 64/56 schätzte man die 8 GiB HBM2 auf in Summe 150 - 160 US$ zzgl. weiteren 25 US$ für Interposer und Packaging. Der Wert blieb auch bis Anfang 2019, zur Veröffentlichung der Radeon VII, erhalten und wurde erneut mit ihr zusammen in Umlauf gebracht, d. h. etwa um die 80 US$ für 4 GiB HBM2, was nahezu doppelt so teuer wie GDDR6 ist.
Hoffen dürfte man hier also wahrscheinlich wenn dann bestenfalls auf AMD, wenn die "um jeden Preis" wieder oben mitspielen wollen würden und dafür einen Teil ihrer Marge opfern ... wahrscheinlich ist das jedoch nicht, wenn man L.Su's Aussagen aus 3Q19 berücksichtigt, aber vielleicht macht man ja bei einem derartigen Prestige-Objekt eine Ausnahme?
*) Die Verwendung von HBM2 würde bei nVidia wohl nur eine Option werden, wenn man tatsächlich gedenkt 16 GiB anzubieten, denn die ließen sich mit zwei HBM2-Stacks besser implementieren, als wenn man mittels GDDR6 ein 512 Bit-Speicherinterface zu implementieren versuchen würde. Für 16 GiB in Consumer-Grafikkarten besteht jedoch aktuell noch kein ausreichender Marktdruck ... von daher, eher unwahrscheinlich.
Laut einem Beitrag von Semiengineering von Ende 2019 beläuft sich der Preis:
What’s Next For High Bandwidth Memory
"Three years ago, HBM cost about $120/GB. Today, the unit prices for HBM2
(16GB with 4 stack DRAM dies) is roughly $120, according to TechInsights. That doesn’t even include the cost of the package."
+ interposer and packaging should be $25 (laut deinen veralteten Informationen von 2017)
Für einen wohl anvisierten Preis von 1000$ bei Big Navi / (Hier würde ich eigentlich Ampere noch erwähnen, aber NVIDIA ist zu geizig daher werden es wohl bei NVIDIA nur 352 / 384 Bit Si werden)
Was wiederum heißen würde, das die kolportierten 5376 gnadenlos selbst mit 18 Gbps ausgebremst würden:
(18/14=1.29) 5376/4352=1.24 + 3080ti (2GHz???) / 2080ti FE 1635 = 1.22 --> 1.24 x 1.22 = 1.51
Es kommen also von den theoretisch möglichen +51% am Ende wohl nur 30-35% beim Kunden an.
Ach ja 512 Bit ist ausgeschlossen das ist zu komplex und würde den anvisierten Verbrauchsrahmen sprengen.
352 Bit 18 Gbps ----> 792 GB/s
384 Bit 18 Gbps ----> 864 GB/s
Big Navi 4 Stacks a 307 GB/s ----> 1229 GB/s inkl. die nötige Energieersparnis die es erst ermöglicht sich in diesem Leistungsniveau zu bewegen.
Da sag ich nur ...... auf die paar Kröten und trete dem geldgierigen Kobold unter der Brücke dort hinein wo die Sonne nie scheint.
Gibt natürlich x Gründe wieso es am Ende doch nur 384Bit 16-18Gbps für arme werden.
Aber die Vorteile überwiegen mittlerweile. Die paar Kröten sind doch nicht die Rede wert in Anbetracht einer 1000€ Karte.
naja, egal. Wenn sie dann alle HBM2 herstellen wird der Preis hoffentlich sinken - wenn sie nicht wieder Preisabsprache machen.
Was stimmt: Noch Mitte 2017 hoffte man, bis Ende 2018 die bestehenden Probleme zu lösen und dann in Großserie gehen zu können. Genauso, wie man das 2015 für 2016 geplant hatte und es 2019 für die 2020er Desktops erwartet wurde.
Wäre für mich schon interessant, wenn 2080ti-Leistung, gepaart mit einem Querschnitt einer R9 nano in Verbindung mit ner AIO (H55 oder mehr) möglich und dann auch gebaut würde.
Man schaue es sich noch mal an : klick . Ich würde steil gehen.
Nun 16 GiB via 512 Bit sind zweifelsfrie nicht kostengünstig, keine Frage, breiterer Bus (größeres Die mit mehr Speichercontrollern; mehr Transistoren und Verlustleistung), teueres PCB, mehr BGAs auf das PCB aufzubringen und dazu (je nach Ausgangslage) +5 oder +4 BGAs zusätzlich einkaufen müssen.
Dein 256 Bit/32 GiB-Vorschlag war nicht überraschend (weil das Quadro RTX 8000-Äquivalent, nur mit kleinerem Bus), sondern erschien mir unpassend, denn so viel Speicher macht nur im HighEnd Sinn (oder für ein sehr spezifisches, kapazitätslastiges Szenario), dann jedoch wäre voraussichtlich die Bandbreite viel zu gering. (Dementsprechend verwundert war ich über den "Vorschlag", aber dir ging es voraussichtlich nur darum aufzuzeigen, dass das grundsätzlich geht.)
Ansonsten nur Anmerkunge, weil wir hier offensichtlich auf einer Linie sind:
- Aktuell nutzt einzig die RTX 2080 Super 16Gbps-Chips. 18Gbps- scheinen im Massenmarkt (vorerst auch absehbar) nicht wirklich verfügbar zu sein, sodass man man hier wohl diesbezüglich in diesem Jahr keine breite Anwednung zu sehen bekommen wird. Für die HighEnd-Modelle, bestünde aber noch die Option direkt 16Gbps-Chips zu verbauen, da die Mehrkosten überschaubar sind. (Vielleicht setzt nVidia 18er-Chips in 2021 auf die neuen Super-Refreshes?
- Im HighEnd erwarte ich auch bestenfalls 384 Bit GDDR6 (wie bisher) und möglicherweise muss nVidia die Differenzierung durch das Streichen eines Controllers entfallen lassen, um wenigstens die vollen 12 GiB anbieten zu können (denn gefühlt geht ja jetzt schon das halbe Forum steil, weil es voraussichtlich keine 16 GiB werden).
Im Performance-Segment (aka 2070/2080) wird es interessant zu sehen sein, ob bspw. nVidia bei 256 Bit bleiben können wird. Mit 16Gbps-Chips ließen sich ggü. der aktuellen Generation damit lediglich +14 % mehr Bandbreite rausholen und hier wird sich zeigen müssen, ob die den geringen Zugewinne auf architektonische Art kompensieren können, da sie ja angeblich deutlich mehr (Raytracing)Performance versprachen.
- Zu meiner Überlegung "wenn 16 GiB, dann besser HBM2": Hierbei ging es nur darum, unter welchen Bedingungen die Verwendung von HBM2 in einem Consumer-Design eher infrage kommen könnte. Das heißt nicht, dass es so kommen muss, denn wie am Ende die Fertigungskosten konkret aussehen, kann ich auch nicht sagen, nur dass es dabei im Vergleich GDDR6 < > HBM2 schon nicht mehr "ganz so übel" aussieht (auch wenn die HBM-Implementation zweifelsfrei immer noch deutlich teuerer bleiben wird). Wenn man sich auf zwei Stacks beschränkt, könnte man mit einem 2048 Bit-Interface "halbwegs preisgünstig" hinkommen und um die 900 - 1000 GiB/s an Bandbreite bereitstellen. Da das "halbwegs" in diesem Fall aber unterstrichen werden muss, käme so etwas nur auf dem Top-Modell infrage. (Kleinere Karten/Modelle könnte man mit HBM2 fertigungskostentechnisch nicht sinnvoll runterstrippen.)
Abschließend noch mit Blick auf die (obien) Nachposter bzgl. Effizienz und Power Consumption:
HBM steht hier deutlich besser da als GDDR5/6, jedoch kann dieses natürlich nicht alles rausreißen, was eine durchwachsene GPU-Architektur bzgl. der Effizienz "verbockt" (angelehnt an Chicien).
16Gbps-GDDR6-BGAs (4 x 2 GiB = 8 GiB) benötigen um die 10 W, wohingegen ein 2,8Gbps-HBM2E-Chip mit 8 GiB um die 5 W benötigt (und zusätzlich noch +40 % mehr Bandbreite bietet). Hinzu kommt, dass das GDDR6-PHY mit vergleichsweise hohem Takt und Strömen läuft, während das HBM-PHY hier signifikant effizienter ist und daher auch direkt auf dem GPU-Die den Verbrauch senkt. (Die absoluten Verluste durch die Speichercontroller stehen natürlich in keinem Vergleich zu den Verlusten durch voll ausgelastete Shader Prozessoren in hoher Zahl.)