Intel Cascade Lake X: 10- und 18-Kerner im Geekbench

Im Geekbench sind zwei Prozessoren der Reihe Cascade Lake X aufgetaucht. Die Ergebnisse sollten nicht überbewertet werden, sind aber ganz interessant auch im Hinblick darauf, dass AMD ja noch Threadripper 3000 und den Ryzen 9 3950X in der Hinterhand hat. Im Segment der stark parallelisierten Rechenleistung ist AMD bisher kompetitiver gewesen.
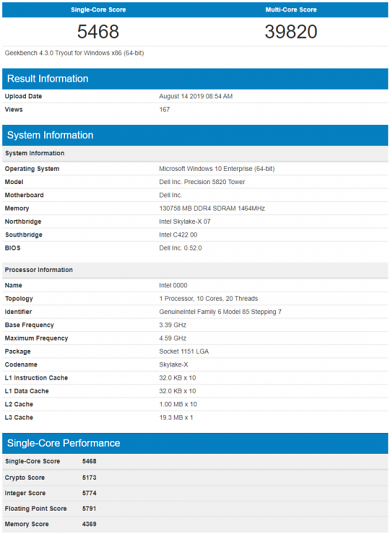
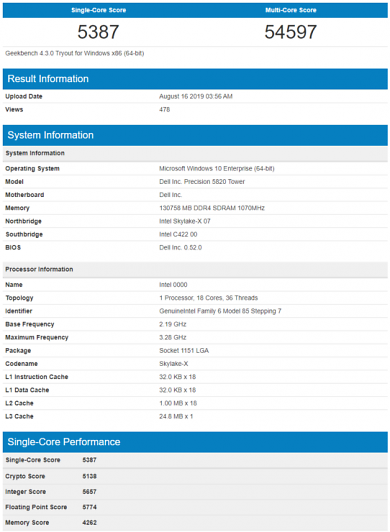
In der Datenbank von Geekbench sind zwei Cascade-Lake-X-Prozessoren aufgetaucht, die im Herbst auf der HEDT-Plattform mit X299-PCH erscheinen sollen. Bei den gelisteten Modellen handelt es sich um einen 18-Kerner und einen 10-Kerner. Vermutlich stammen die Tests aus den Laboren von Dell, wo sie für einen PC vom Typ Precision 5820 X Series getestet worden sein könnten. Dabei handelt es sich um Workstations von Dell, die aktuell mit LGA-2066-Prozessoren der aktuellen Generation ausgestattet sind.
Die neuen Modelle indes werden als "GenuineIntel Family 6 Model 85 Stepping 7" aufgeführt. Der 18-Kerner wird mit 2,19 GHz Basis- und 3,28 GHz Boost-Takt gelistet. Der 10-Kerner steht in der Datenbank mit 3,39 GHz Basis- und 4,59 GHz Boost-Takt. Wie final die Werte sind, sei dahingestellt. Für gewöhnlich sind Engineering Samples mit reduziertem Tempo unterwegs. Wie die Lage bei den konkret gelisteten zwei Modellen ist, ist unklar. Der 18-Kerner ist jedenfalls langsamer unterwegs als das aktuell verfügbare Modell Intel Core i9-9980XE (3,0/4,5) und auch der 10-Kerner kommt nicht an sein aktuelles Pendant, Core i9-9900X (3,5/4,4), heran.
Auch lesenswert: AMD Threadripper: Dritte Generation im Oktober?
Entsprechend vorsichtig sollte man auch die Werte behandeln, die für den 18-Kerner bei 5.387/54.597 Punkten liegen. Der 10-Kerner hat 5.468/39.820 Punkte. Damit wäre der 18-Kerner auf dem Leistungsniveau eines Ryzen Threadripper 2970WX und der 10-Kerner auf dem Niveau eines Ryzen Threadripper 2920X. Natürlich wird von AMD im Herbst ebenfalls eine neue HEDT-Plattform erwartet, die - zusammen mit genaueren Werten von Intel-Modellen - ein bisschen Würze in das Segment bringen dürfte, denn AMD rüstet auf Zen 2 um. Threadripper 3000 dürfte vor allem im Mehrkern-Ergebnis einige Punkte mehr holen als der Vorgänger, aber auch bei der Pro-Takt-Leistung auf einem Kern näher an Intel liegen.
Was man auf jeden Fall erwarten darf, ist, dass es die ganze Leistung nicht ohne Haken geben wird und der dürfte bei der Leistungsaufnahme liegen. Die auf der Computex gezeigten Mainboards für die HEDT-Plattform haben umfangreiche Spannungsversorgungen mit noch größeren Kühlern als noch bislang üblich. 165 Watt TDP sind sicher gesetzt und werden wohl auch wieder die Grenze auf dem Papier darstellen, ungezügelt dürfte es aber auch darüber hinaus gehen.









Edit: Hier noch eine Ergänzung aus eine Diskussion bei CB.
"Looking at the AMD numbers above 16 MB, it is clear that is no large 256 MB L3-cache. The AMD EPYC 7742 rather consist of 16 CCX which alll have a relatively fast 16 MB L3. So although the 64 cores are one big NUMA node now, the 64-core chip is basically 16x 4 cores, each with 16 MB L3-caches. Once you get beyond that 16 MB cache, the prefetchers can soften the blow, but you will be accessing the main DRAM."
Quelle
Also leider kein Shared Cache. Die leichten Vorteile kommen vom Prefetcher.
Umgekehrt resultieren daraus natürlich kaum Geschwindigkeitsvorteile, man spart sich nur die reinen Zugriffslatenzen von DRAM und hält Arbeitsspeicher-Datentransferrate für andere Tasks frei. Aber genau diese Minimalvorteile zeichnen sich auch in den Messergebnissen ab.
Von Hand in 3 Projekte zu teilen braucht mehr Zeit als man durch gleichzeitiges Rendern jemals wieder reinholt. Ich müsste dann alle auf einander abhängig und dubliziert erstellte Videos 3 mal machen. Gefällt einem etwas nicht muss man es nicht 1x ändern, sondern in allen 3 Projekten.
Adobe Premiere hat nichts mit V-Ray oder Tomatenmark aus der Tube zu tun.
Was du also bräuchtest wäre eine Netzwerklösung bei der alle Rechner gemeinsam am selben Frame arbeiten oder aber einen Job der vorab die Keyframes berechnet und diese segmentiert an die Rechner verteilt, damit diese dann eine jeweilige Range rendern können. Technisch bräuchtest du wohl einen GBit Downlink je Client.
Am billigsten ist es mittels eines KVM Switch, denn beim Rendern musst du ja nicht eingreifen, also Job erstellen Rendern lassen und einfach zum nächsten Hardware Rechner switchen. Moderner geht es über RemoteDesktop.
Und die Möglichkeiten von HPC Cluster sind da noch gar nicht genannt.
Aber wenn man natürlich gebunden ist an Mac oder Windows, dann sind die o.g. Möglichkeiten wohl die simpelsten.
P.S.
Ist natürlich nur eine andere Art der Parallelisierung, aber ich hoffe doch ,dass du nicht ständig jedes Video neu renderst und dafür das zuvor gemachte brauchst! Weil dann ist dir in vielerlei Hinsicht nicht zu helfen.
Von Hand in 3 Projekte zu teilen braucht mehr Zeit als man durch gleichzeitiges Rendern jemals wieder reinholt. Ich müsste dann alle auf einander abhängig und dubliziert erstellte Videos 3 mal machen. Gefällt einem etwas nicht muss man es nicht 1x ändern, sondern in allen 3 Projekten.