Detailverbesserungen Nehalem
Intel hat heute im Rahmen des hauseigenen Forums IDF genaue Informationen zur Architektur der kommenden Nehalem-Prozessoren bekanntgegeben. PCGH fasst alle Infos für Sie zusammen.
Nehalem: Detail-Verbesserungen
Macrofusion: Grundsätzlich mehr Möglichkeiten - Nehalem kann nun auch einige weitere Sprungbefehle zusammen mit einer Vergleichsoperation umsetzen (zum Beispiel JGE [Jump if greater or equal] oder JL [Jump if less])
Macrofusion: Die Befehlsvereinigung funktioniert nun auch im 64-Bit-Modus - bei bisherigen Core-Prozessoren ist Macrofusion nur im 32-Bit-Betrieb möglich.
 Nehalem Detailinfos vom IDF
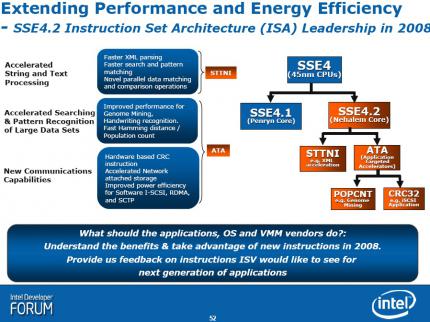
SSE 4.2: Befehlssatz-Erweiterung, die neue Möglichkeiten bei Textoperationen schafft (Details siehe Bildergalerie). Nach Angaben von Intel soll dies besonders der XML-Verarbeitung zugute kommen.
Nehalem Detailinfos vom IDF
SSE 4.2: Befehlssatz-Erweiterung, die neue Möglichkeiten bei Textoperationen schafft (Details siehe Bildergalerie). Nach Angaben von Intel soll dies besonders der XML-Verarbeitung zugute kommen.
Loop Stream Detector: Eine Einheit, welche Schleifen im Programm ohne die Out-of-Order-Execution-Engine ausführen kann, was Ressourcen spart und die Verarbeitung beschleunigt. Diese bereits bei Core-Prozessoren implementierte Einheit soll nun mehr Schleifen erkennen und damit schneller arbeiten. Zudem kann nun auch die Dekodierungsstufe umgangen werden, was Energie sparen hilft.
Sprungvorhersage: Sprungvorhersagen ("Branch Predictions") beschleunigen immer dann die Verarbeitung, wenn der Programmcode viele Schleifen enthält, die auf eine gleiche Datenbasis zurückgreifen - die Arbeit kann dann "auf Verdacht" ausgeführt werden. Bei Datenbanken dagegen werden häufig wechselnde Daten verwendet, was die Effizienz der Sprungvorhersage stark vermindert. Nehalem enthält eine mehrstufige Sprungvorhersage, welche dieses Problem lindern soll.
 Nehalem Detailinfos vom IDF
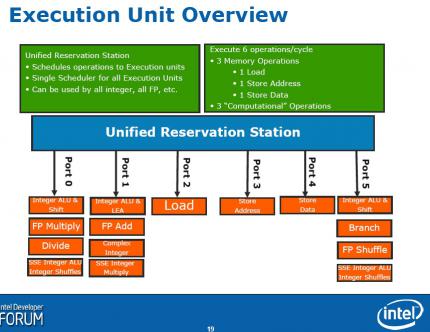
Ausführungseinheiten: Die Ausführungseinheiten ("Execution Units") sind nun etwas breiter und erlauben nun 36 Mikrooperationen in der Reservation Station (verteilt dekodierte Befehle an die Einheiten, beim Merom waren es noch 32), 48 in den Load Buffers (32) und 32 in den Store Buffers (20). Das vergrößert nach Angaben von Intel das Potenzial der Out-of-Orde-Ausführung um 33 Prozent.
Nehalem Detailinfos vom IDF
Ausführungseinheiten: Die Ausführungseinheiten ("Execution Units") sind nun etwas breiter und erlauben nun 36 Mikrooperationen in der Reservation Station (verteilt dekodierte Befehle an die Einheiten, beim Merom waren es noch 32), 48 in den Load Buffers (32) und 32 in den Store Buffers (20). Das vergrößert nach Angaben von Intel das Potenzial der Out-of-Orde-Ausführung um 33 Prozent.
Speicher-Subsystem: Änderungen betreffen vor allem den Translation-Lookaside-Buffer, die bekanntlich bei AMD zu einigen Kopfschmerzen geführt haben, sowie die Datenausrichtung ("Alignment"). Zusammengefasst werden die TLB-Puffer größer, können also mehr Einträge in zwei Stufen verwalten - damit soll den immer größer werdenden Anwendungen Rechnung getragen werden. Daten, die "unaligned" im Cache vorliegen, soll Nehalem schneller berechnen können.
Virtualisierung: Eine Handvoll Verbesserungen. Erwähnenswert ist die Verwaltung der Speichertabellen ("Page Tables") der virtuellen Gast-Maschinen, die im Gegensatz zu Core-Prozessoren mit weniger Overhead auskommen soll.
Eine ausführliche Erklärung der Architektur bringt PC Games Hardware in einer der nächsten Ausgaben.








