AMD CDNA: Radeon Instinct MI100 soll bei FP32-Leistung triumphieren

Laut geleakten Folien soll AMDs kommende CDNA-Architektur und damit die Radeon Instinct MI100 bei der FP32-Leistung weit vor der Konkurrenz liegen. Bei den übrigen Anwendungsgebieten soll AMD hingegen Nvidia den Vorrang lassen.
Mit der CDNA-Architektur will AMD im zweiten Halbjahr 2020 endlich eine eigene Compute-Architektur einführen, wodurch die Gaming-Grafikkarten des Unternehmens besser auf ihren Einsatzzweck zugeschnitten werden können. Als erstes Produkt mit CDNA-Architektur soll die Radeon Instinct MI100 erscheinen, zu der auch bereits erste Details bekannt wurden: Beispielsweise soll die Grafikkarte über 32 GiByte HBM-Speicher verfügen.
Radeon MI100 mit starker FP32-Performance
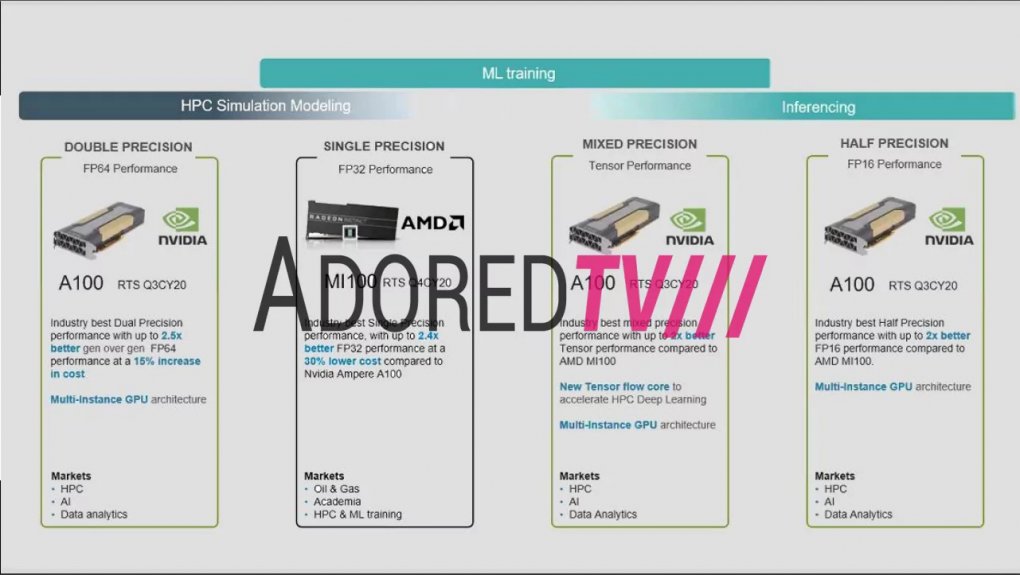
Von AdoredTV sind jetzt auch erste Leistungsdetails geleakt worden, auch wenn diese nur die grobe Ausrichtung der Grafikkarte erahnen lassen: Laut angeblich offiziellen AMD-Folien soll die MI100 mit 300W TDP bei der FP32-Leistung um 140 Prozent vor Nvidias A100-GPU liegen. Gleichzeitig soll die Radeon-Grafikkarte 30 Prozent weniger kosten. In den übrigen Anwendungsgebieten FP64, FP16 sowie FP16+FP32 ("Mixed Precision") lässt AMD Nvidia aber den Vorrang: Hier soll die A100 um etwa den Faktor 2 vorne liegen.
 Quelle: AdoredTV
Bei vielen Aufgabengebieten will AMD nicht mit Nvidia konkurrieren: Lediglich bei FP32-Anwendungen soll die MI100 vorne liegen. Damit soll sie sich besonders gut für den fossilen Energiemarkt, für akademische Anwendungen sowie für allgemeine Hochleistungsrechner und für Machine Learning eignen.
Gegenüber Nvidia soll AMD die MI100 somit vor allem im akademischen Bereich sowie für Öl- und Gasunternehmen im Vorteil sehen. Bei Letzterem geht es vor allem um die Anwendung der Reverse Time Migration (RTM), durch die sich der Erduntergrund aus seismischen Daten errechnen lässt. Dadurch können neue Öl- und Gasvorkommen gefunden werden. Außerdem soll sich die Grafikkarte auch gut für allgemeine Hochleistungsserver und das maschinelle Lernen eignen.
Quelle: AdoredTV
Bei vielen Aufgabengebieten will AMD nicht mit Nvidia konkurrieren: Lediglich bei FP32-Anwendungen soll die MI100 vorne liegen. Damit soll sie sich besonders gut für den fossilen Energiemarkt, für akademische Anwendungen sowie für allgemeine Hochleistungsrechner und für Machine Learning eignen.
Gegenüber Nvidia soll AMD die MI100 somit vor allem im akademischen Bereich sowie für Öl- und Gasunternehmen im Vorteil sehen. Bei Letzterem geht es vor allem um die Anwendung der Reverse Time Migration (RTM), durch die sich der Erduntergrund aus seismischen Daten errechnen lässt. Dadurch können neue Öl- und Gasvorkommen gefunden werden. Außerdem soll sich die Grafikkarte auch gut für allgemeine Hochleistungsserver und das maschinelle Lernen eignen.
Passend zum Thema: AMD Radeon Instinct MI100: Release 2020 und CDNA-Architektur
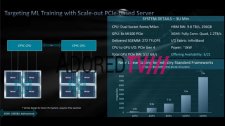
Ein konkreter Veröffentlichungszeitraum der Grafikkarte lässt sich aus den Folien zwar nicht entnehmen, doch AMD verspricht einen ersten Server für Dezember 2020: Dann soll ein System mit zwei Rome-/Milan-Prozessoren und vier MI100-GPUs auf den Markt kommen. Im Februar 2021 soll dann dasselbe System mit Xeon-Prozessoren erscheinen, bevor im März 2021 ein System mit wieder zwei AMD-Prozessoren und stolzen acht MI100-GPUs erscheinen soll.








Ist ja kaum noch auszuhalten.
HIP ist eigentlich auch ein super Ansatz, da es auf die jeweils herstellereigenen APIs zurückgreift und es sehr einfach ist CUDA Code auf HIP zu portieren. Allerdings ist auch nur eine Teilmenge von CUDA unterstützt.
PlaidML gefällt mir da besser, da es eine unanbhängige Plattform ist, die vom Start weg auch die wichtigen Tools (Keras, TensorFlow, PyTorch) unterstützt, während HIP nur auf der untersten Ebene abstrahiert. Wenn jetzt noch die Performace stimmt, wäre das eine große Erleichterung (auch für AMD).
HIP ist eigentlich auch ein super Ansatz, da es auf die jeweils herstellereigenen APIs zurückgreift und es sehr einfach ist CUDA Code auf HIP zu portieren. Allerdings ist auch nur eine Teilmenge von CUDA unterstützt.
PlaidML gefällt mir da besser, da es eine unanbhängige Plattform ist, die vom Start weg auch die wichtigen Tools (Keras, TensorFlow, PyTorch) unterstützt, während HIP nur auf der untersten Ebene abstrahiert. Wenn jetzt noch die Performace stimmt, wäre das eine große Erleichterung (auch für AMD).
Hier bischen Wissen für dich:
Porting CUDA to HIP >> ADMIN Magazine
Welten liegen Zwischen Hipp Babybrei und Cuda das eine isst man das andere ist eine Programmier-Technik
Hast du jemals ein Projekt in CUDA und HIP programmiert? Offensichtlich nicht. In der Qualität der Toolkits liegen Welten zwischen CUDA und HIP. Zugunsten von CUDA.
Aber du hast den Plan
Hier bischen Wissen für dich:
Porting CUDA to HIP >> ADMIN Magazine
Welten liegen Zwischen Hipp Babybrei und Cuda das eine isst man das andere ist eine Programmier-Technik