Intel Core Ultra: Meteor Lake soll der erste 3D-Hybrid-Prozessor werden

Die kommenden Core-Prozessoren der Generation "Meteor Lake", die als Intel Core und Intel Core Ultra vermarktet werden, sollen als erste "3D-Hybrid-Prozessoren" insbesondere auf hohe Effizienz und KI optimiert worden sein. Im Rahmen der "Intel Tech Tour: Meteor Lake" gibt der Hersteller erstmals einen tiefen Einblick in die Mikroarchitektur der CPUs.
Die kommenden Core-Prozessoren der nächsten Generation "Meteor Lake", welche in Zukunft als Intel Core und Intel Core Ultra vermarktet werden, sollen laut Intel als erste "3D-Hybrid-Prozessoren" insbesondere auf höchste Effizienz und KI optimiert worden sein. Im Rahmen der "Intel Tech Tour: Meteor Lake" gibt der Hersteller nun erstmals einen tiefen Einblick in die Mikroarchitektur der CPUs und deren Aufbau. Die Tiles, Intels Pendant zu AMDs Chiplets, und weitreichende Optimierungen vonseiten Microsofts, sollen die bisher effizientesten Mobilprozessoren hervorbringen.
3D-Hybrid-Architektur rückt Effizienz und KI in den Fokus
Intel bezeichnet die neueste Generation seiner Core-Prozessoren nicht ohne Grund als "Next Gen Power Efficient Processors", sondern zielt ganz bewusst auf die Bereiche Effizienz und KI ab. Erstmals soll hierfür nun ein "3D-Hybrid-Design" zum Einsatz kommen, welches einem neuen Aufbau folgt. Die explizite Ausrichtung als Mobilprozessor mit höchster Energieeffizienz ist dabei unverkennbar.
 Quelle: Intel
Quelle: Intel
 Quelle: Intel
Quelle: Intel
Während die Core-Prozessoren der 12., 13. und 14. Generation alias "Alder Lake", "Raptor Lake" und "Raptor Lake Refresh" auf ein "2D-Hybrid-Design" aus E-Cores und P-Cores gesetzt haben, kommen bei "Meteor Lake" gleich zwei Stufen der effizienteren kleinen Efficiency-Cores zum Einsatz. Intel spricht in diesem Zusammenhang jetzt erstmals von einer neuen "3D Perfomance Hybrid Architecture".
 Quelle: Intel
Die zweistufigen E-Cores und die P-Cores der 3D-Hybrid-Architektur
Wie zuvor bilden P-Cores und E-Cores die eigentliche CPU, welche jetzt als CPU-Die oder Compute Tile bezeichnet wird, während weitere nochmals sparsamere E-Cores auf dem SoC Tile platziert werden. Die Architektur arbeitet dabei dreistufig und wechselt je nach Lastzustand zwischen SoC Tile und Compute Tile.
Quelle: Intel
Die zweistufigen E-Cores und die P-Cores der 3D-Hybrid-Architektur
Wie zuvor bilden P-Cores und E-Cores die eigentliche CPU, welche jetzt als CPU-Die oder Compute Tile bezeichnet wird, während weitere nochmals sparsamere E-Cores auf dem SoC Tile platziert werden. Die Architektur arbeitet dabei dreistufig und wechselt je nach Lastzustand zwischen SoC Tile und Compute Tile.
 Quelle: Intel
Quelle: Intel
 Quelle: Intel
Quelle: Intel
Zum Einsatz kommen Prozessorkerne vom Typ "Crestmont" für die E-Cores und "Redwood Cove" für die P-Cores. Neben dem bereits genannten Compute Tile und dem SoC Tile ergänzen ein Graphics Tile mit Intel Xe und ein IO Tile den Aufbau der 3D-Hybrid-Prozessoren. Dieser Aufbau soll Intel dabei helfen, einzelne Tiles noch einfacher kombinieren und so spezifische Lösungen realisieren zu können.
 Quelle: Intel
Die Tile Architektur kombiniert vier Tiles zu einem 3D-Hybrid-Prozessor
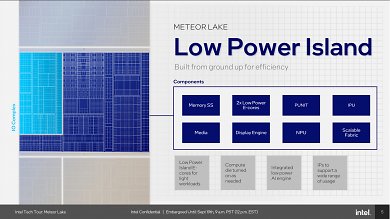
Das SoC Tile ist dabei ganz speziell auf höchstmögliche Effizienz hin ausgelegt und beheimatet die sogenannte "Low Power Island", welche unter anderem zwei dedizierte E-Cores ("Crestmont"), einen IO-Prozessor ("IPU"), einen Neural-Prozessor ("NPU") sowie die Display- und Media-Engine bereitstellt. Insbesondere die leichtesten Workloads sollen vollständig auf der "Low Power Island" laufen und so die Energieeffizienz und Akkulaufzeiten noch einmal deutlich erhöhen.
Quelle: Intel
Die Tile Architektur kombiniert vier Tiles zu einem 3D-Hybrid-Prozessor
Das SoC Tile ist dabei ganz speziell auf höchstmögliche Effizienz hin ausgelegt und beheimatet die sogenannte "Low Power Island", welche unter anderem zwei dedizierte E-Cores ("Crestmont"), einen IO-Prozessor ("IPU"), einen Neural-Prozessor ("NPU") sowie die Display- und Media-Engine bereitstellt. Insbesondere die leichtesten Workloads sollen vollständig auf der "Low Power Island" laufen und so die Energieeffizienz und Akkulaufzeiten noch einmal deutlich erhöhen.
 Quelle: Intel
Quelle: Intel
 Quelle: Intel
Quelle: Intel
Damit die neuen Intel Core und Intel Core Ultra auch bestmöglich zwischen den Low-Power-E-Cores, den regulären E-Cores und den P-Cores wechseln können, benötigt es weitreichender Anpassungen am sogenannten "Intel Thread Director" sowie an dem Scheduler des Betriebssystems. Gemeinsam mit Microsoft wurde Windows 11 so angepasst, dass der bestmögliche Support für Meteor Lake gegeben sein soll.
 Quelle: Intel
Windows 11 wurde vonseiten Microsoft entsprechend optimiert
Der Intel Thread Director und der Scheduler von Windows 11 können dabei zwischen den Szenarien "Effiziency" und "Perfomance" unterscheiden und die Threads für die höchste Effizienz und die beste Leistung entsprechend den E-Cores und P-Cores zuweisen. Hierbei sollen das Compute Tile und SoC Tile zusammenarbeiten.
Quelle: Intel
Windows 11 wurde vonseiten Microsoft entsprechend optimiert
Der Intel Thread Director und der Scheduler von Windows 11 können dabei zwischen den Szenarien "Effiziency" und "Perfomance" unterscheiden und die Threads für die höchste Effizienz und die beste Leistung entsprechend den E-Cores und P-Cores zuweisen. Hierbei sollen das Compute Tile und SoC Tile zusammenarbeiten.
 Quelle: Intel
Quelle: Intel
 Quelle: Intel
Quelle: Intel
Neben der höchstmöglichen Effizienz hat Intel auch den immer wichtiger werdenden Bereich der KI in Angriff genommen und den neuen Core-Prozessoren einen ebenfalls auf Effizienz optimierten Neural-Prozessor ("NPU") der neuesten Generation spendiert, welcher in Zusammenarbeit mit der CPU und der integrierten Grafikeinheit für die bestmöglichen Ergebnisse in KI-Anwendungen sorgen soll.
 Quelle: Intel
Der neue Neural-Prozessor ("NPU") arbeitet mit CPU und GPU zusammen
Zu guter Letzt hat Intel noch einen Ausblick auf sein Foundry-Geschäft und die kommenden Fertigungsverfahren ("Nodes") gegeben. Die nächsten großen Schritte nach Intel 4 soll demnach Intel 3, Intel 20A und Intel 18A sein, welche sukzessive bis zum 2. Halbjahr 2024 ausgerollt werden sollen. Bereits Intel 4 verspricht im Vergleich zu Intel 7 eine um rund 20 Prozent höhere Energieeffizienz und EUV-Lithographie.
Quelle: Intel
Der neue Neural-Prozessor ("NPU") arbeitet mit CPU und GPU zusammen
Zu guter Letzt hat Intel noch einen Ausblick auf sein Foundry-Geschäft und die kommenden Fertigungsverfahren ("Nodes") gegeben. Die nächsten großen Schritte nach Intel 4 soll demnach Intel 3, Intel 20A und Intel 18A sein, welche sukzessive bis zum 2. Halbjahr 2024 ausgerollt werden sollen. Bereits Intel 4 verspricht im Vergleich zu Intel 7 eine um rund 20 Prozent höhere Energieeffizienz und EUV-Lithographie.
 Quelle: Intel
Quelle: Intel
 Quelle: Intel
Quelle: Intel
Ihre Meinung ist gefragt!
Wie stehen Sie zu diesem Thema? Die PCGH-Redaktion freut sich über Ihre fundierte Meinung in den Kommentaren zu dieser Meldung. Um zu kommentieren, müssen Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie noch keinen Account haben, könnten Sie sich hier unverbindlich registrieren.
Quelle: Intel









[Ins Forum, um diesen Inhalt zu sehen]
[Ins Forum, um diesen Inhalt zu sehen]
Darüber hinaus kommt aber auch hinzu, dass ein komplett neuer Node niemals derart ausgereift auf dem Markt kommt, sodass er in allen Aspekten mit dem alten, über Jahre hinweg hochgradig optimierten Vorgänger mithalten kann. Das liegt schlicht in der Natur der Sache. Kein wirtschaftlich arbeitendes Unternehmen hat ein Interesse daran ein grundlegend funktionierendes, gutes Produkt zurückzuhalten und noch weitere 2 Jahre durch die R&D-Abteilungen zu jagen um dann ein "quasi perfektes" Produkt auf den Markt zu bringen. Das ist im Endeffekt schlicht unwirtschaftlich.
Darüber hinaus, das Spiel wird sich Ende 2024 erneut wiederholen, denn Intel 20A ist abermals nur ein Zwischenentwicklungsschritt hin zu Intel 18A. Dennoch wird auch bereits Intel 20A einen deutlichen Mehrwert für den Konsumenten bieten, sodass das ein Win-Win für Intel und den Konsumenten ist.
Bei AMD dagegen ist die Sache etwas anders gelagert, da die nicht die Ressourcen haben um sich mit bspw. Apple auf einen Preiskampf um den modernsten Node einzulassen und sieht man es sich genau an, sind sie grundsätzlich stärker kostenlimitiert aufgrund ihrer deutlich geringeren Absatzzahlen, sodass es für sie keinen Sinn ergab bspw. TSMCs 5 nm schon mit Zen3 zu verwenden, obwohl dieser Prozess schon seit dem 1HJ20 in der HVM war. Die verfügbaren Kontingente waren zu knapp bemessen und vor allem war der Node zu der Zeit auch viel zu teuer für AMD. Entsprechend musste man als Endkunde auf Produkte halt bis ins 2HJ22 warten, während zu dem Zeitpunkt bei TSMC schon längst 4 nm aktuell waren und 3 nm kurz vor der Tür standen.
Am Ende spielt eine derartige Betrachtung aus Sicht des Konsumenten aber auch keine Rolle, denn rein prozesstechnisch, wenn auch ein derartiges AMD-Produkt "derart spät" in den Markt eingeführt wurde, nutzt(e) Zen4 dennoch den modernsten Fertigungsprozess im x86-Markt, d. h. Was-wäre-wenn- und Aber-es-existiert-doch-Spielchen sind unsinnig, wenn es keinen Hersteller gibt, der diese alternativen Möglichkeiten nutzt und entsprechende Konkurrenzprodukte in den Markt bringt.
Und am Ende könnte man alles auch auf die einfache, plakative Formel eindampfen: Es zählt was hinten rauskommt, vollkommen egal wie bspw. Intel seinen Prozess einordnet oder ihn benennt oder ob sie diesen möglicherweise schon bspw. zwei, drei Quartale später durch einen besseren Nachfolgeprozess ersetzen.
Am ende war also der 13900k so schnell wie diese CPU gewesen.Trotz der Vorteile die diese CPU theoretisch eigentlich hätte.Doch die Realität sieht halt anders aus.So kam Intel also nicht wirklich voran.Klar wollte ja auch nur wissen wie weit die CPU kommt.Ich war schon Entäuscht gewesen.Und klar lebt die CPU von Allcore Takt aber ab einen bestimmten Takt da steigt eben der Stromverbrauch drastisch an.
Ist ja auch bei AMD so.Da ist der 7950x bei 4,8 ghz auf 142 Watt aber sobald dann da 5,1 ghz anliegt,werden es aufeinmal 200 Watt.
Genau so verhält es sich ja auch bei Intel.Ich weis nur nicht ab welchen Allcore Takt das der Fall ist.Bei 4 ghz brauchte der 13900k jedenfalls so 125 Watt aber die Rohleistung ist unterirdisch.Und warum weil meine Anwendung auf den fehlenden Takt sehr allergisch drauf reagiert.Es ist nur eine Anwendung das so drastisch drauf reagiert.
Also ich weis zwischen 5,7 ghz Allcore Takt auf 4 ghz ist wirklich sehr viel Takt unterschied.Von 350 Watt auf 125 Watt herunter gesenkt.
Achja der Core i9 9980xe den hatte ich selbst gehabt.Der Allcore takt war bei mir auf 3,8 ghz auf 140 Watt gewesen.
Eines muss man dennoch lassen,zwar ist die Leistung nicht besser geworden aber der Stromverbrauch ist minimal geringer geworden.Weil 125 Watt trotz 4 ghz ,wäre echt ein guter Wert.Leider wird sowas durch den sehr hohen Takt wieder kaputt gemacht.Ab welchen Takt geschieht sowas wo die Leistung nicht mehr mit steigt,sondern nur noch der Stromverbrauch massiv ansteigt.Welche von euch wissen das bestimmt oder?
Denke der Unterschied hier ist Generation vs. Produkt Jahr.
Ende 2020 kam auch N5 von TSMC zum Einsatz in iPhones und es hat bis 2022 gedauert bis Zen4 es genutzt hat mit wahrscheinlich entsprechender Optimierungszeit, die man hier dann theoretisch einfach nicht hat und nicht haben will.
Intel fertigt mit den Nodes in aller Regel nur CPUs und Desktop CPUs haben dann doch etwas höhere Anforderungen an einen Node, weshalb eigentlich immer schon die mobilen Chips einfacher zu produzieren waren. Intel wird mit 20A (sofern man im Plan bleibt) wahrscheinlich nach Jahren wieder einen überlegenen Prozess im Rennen haben, mit 14nm (eher vergleichbar mit TSMC 10nm) war man so lange im Rennen, musste sich aber schon gegen TSMC 7nm wehren und nun läuft man mit einem 7nm Prozess gegen TSMCs 5nm Prozess. Mit 20A wird man bei einem 2nm Verfahren liegen und vermutlich gegen 3nm TSMC laufen.
Die Prozesse werden allesamt eine ähnliche Qualität haben, wenn sie in der ersten Gen laufen, denke einfach, dass Intel die Probleme immer noch nicht im Griff hat. Man sieht ja aktuell sehr gut, dass bspw. ein 13900K in CP2077 die gleiche Effizienz aufweist, wie ein 9900K, ein Node sollte aber gerade diese Effizienz immer verbessern, mehr Leistung bei gleicher Power, oder weniger Power bei gleicher Leistung.
Dies hat Intel bisher nicht geschafft, obwohl Intel7 ja auch die dritte oder vierte Anpassung des Prozesses war. daher bin ich sehr vorsichtig, was Intel mit 20A liefern wird. In der Theorie müsste man bereits heute, vieleicht 10% hinter AMD liegen (Effizienz), die Realität sagt aber es sind mehr als 100%.
Denke der Unterschied hier ist Generation vs. Produkt Jahr.
Ende 2020 kam auch N5 von TSMC zum Einsatz in iPhones und es hat bis 2022 gedauert bis Zen4 es genutzt hat mit wahrscheinlich entsprechender Optimierungszeit, die man hier dann theoretisch einfach nicht hat und nicht haben will.