Intels CPU-Architektur: Einblicke der ehemaligen Chefentwicklerin - Temperatur als Problem

Debbie Marr, ehemalige CPU-Architektur-Chefin bei Intel, hat Details über die Probleme und Lösungen in der Entwicklung verraten. Besonders kritisch ist demnach die rasante Temperaturentwicklung.
Mit Ahead Computing war dieses Jahr auch ein kleineres Unternehmen auf der Halbleitermesse IEDM aktiv und beleuchtete in einem Paper die wichtigsten Eckpunkte moderner CPU-Designs. Spannend dabei ist, von wem die Informationen stammen: Autorin ist Debbie Marr. Diese ist CEO von Ahead Computing, sie war aber ab 1988 bei Intel tätig. Seit 1992 wirkte sie an verschiedenen CPU-Architekturen mit, und von 2019 bis Juli 2024 war sie sogar als leitende Managerin für die Architekturentwicklung verantwortlich. Ihre Handschrift prägt also alle aktuellen Intel-Prozessoren - und wohl auch noch die kommenden Generationen.
Weg mit der Wärme
Das Paper gibt damit einen guten Einblick, wie und warum Intel so vorgeht, wie es das Unternehmen derzeit tut. Das von Marr beschriebene, grundlegende Problem ist aber allgemeingültig. Demnach wurde die Rechenleistung von Prozessoren früher vorwiegend durch die Anzahl und Schaltgeschwindigkeit der Transistoren begrenzt. Inzwischen ist das größte Problem aber die Temperaturentwicklung. Durch hohe Integrationsdichten und die Zunahme von 3D-Designs wird es immer wichtiger, die entstehende Hitze im Blick zu behalten.
 Quelle: Debbie Marr
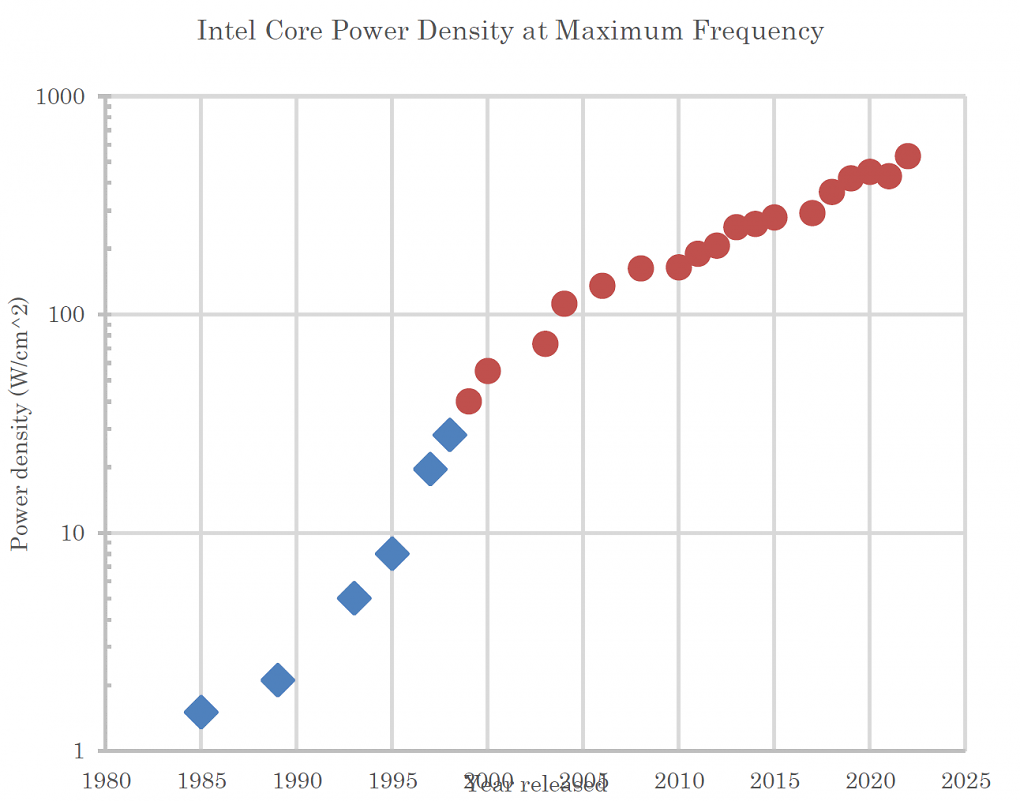
Bis grob zur Jahrtausendwende stieg die Leistungsdichte in CPUs exponentiell an. Seitdem ist die Wärmeentwicklung ein zunehmendes Problem.
Schon 1999 erreichte die Wärmedichte in Prozessoren angeblich das Niveau einer Kochplatte, und seitdem wurde es noch schlimmer. Gleichzeitig bleibt angesichts der hohen Ströme auf winzigem Raum kaum Reaktionszeit; die Temperatur kann rasant ansteigen und hohe Werte erreichen. Wasserkühlungen oder Vapor Chambers können zwar helfen, das Problem aber nicht lösen.
Quelle: Debbie Marr
Bis grob zur Jahrtausendwende stieg die Leistungsdichte in CPUs exponentiell an. Seitdem ist die Wärmeentwicklung ein zunehmendes Problem.
Schon 1999 erreichte die Wärmedichte in Prozessoren angeblich das Niveau einer Kochplatte, und seitdem wurde es noch schlimmer. Gleichzeitig bleibt angesichts der hohen Ströme auf winzigem Raum kaum Reaktionszeit; die Temperatur kann rasant ansteigen und hohe Werte erreichen. Wasserkühlungen oder Vapor Chambers können zwar helfen, das Problem aber nicht lösen.
Deshalb ist laut Marr ein intelligentes Design notwendig. Die Entwickler versuchen, energiehungrige Schaltwerke neben sparsamen Bereichen zu platzieren, oder besonders kritische Bereiche doppelt zu verbauen und abwechselnd anzusprechen. Teils werden Schaltungen auch absichtlich größer ausgelegt, damit sich die Hitze besser verteilt. Lösen ließe sich das alles zwar durch niedrigere Verbrauchswerte der Transistoren, doch diese würden die Hersteller wohl nur für höhere Taktraten nutzen und dann wieder vor demselben Problem stehen.
 Quelle: Debbie Marr
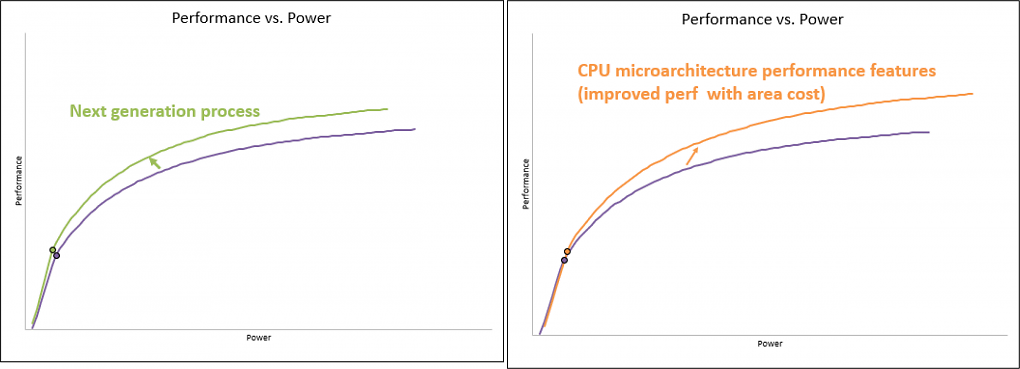
Eine bessere Fertigung ermöglicht tendenziell mehr Leistung bei weniger Verbrauch (links). Bei einer besseren Architektur wird das Performance-Plus hingegen durch einen höheren Verbrauch erkauft (rechts).
Quelle: Debbie Marr
Eine bessere Fertigung ermöglicht tendenziell mehr Leistung bei weniger Verbrauch (links). Bei einer besseren Architektur wird das Performance-Plus hingegen durch einen höheren Verbrauch erkauft (rechts).
 Quelle: Debbie Marr
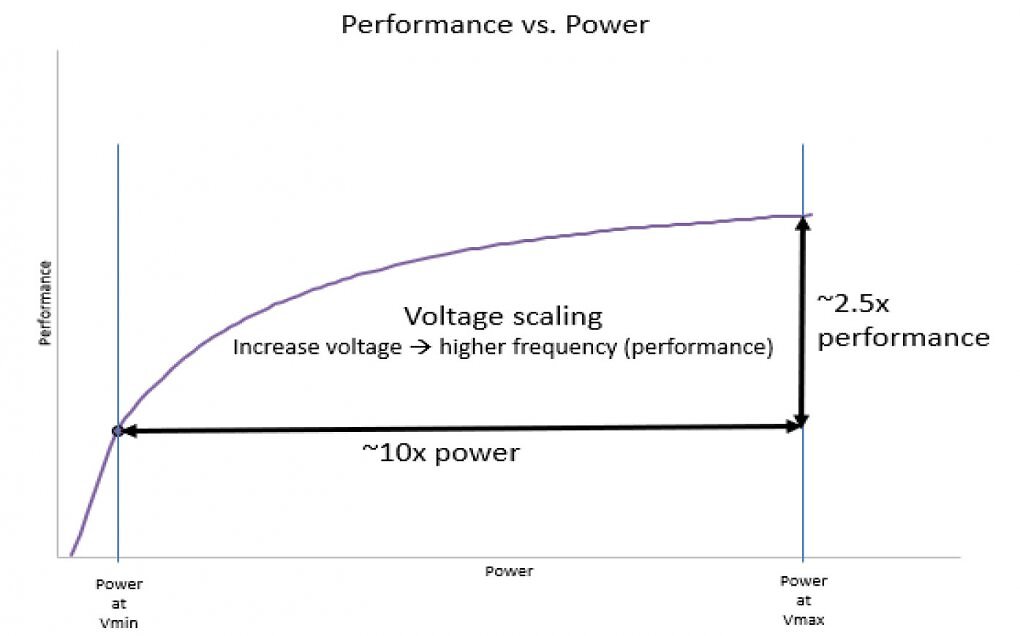
Prozessoren können sich durch Taktänderungen auf der durch den Prozess und die Architektur vorgegebenen Leistungs-/Verbrauchskurve bewegen.
Quelle: Debbie Marr
Prozessoren können sich durch Taktänderungen auf der durch den Prozess und die Architektur vorgegebenen Leistungs-/Verbrauchskurve bewegen.
Ebenso interessant: CPUs mit Core Ultra 400: Konkretere Hinweise zu Intels X3D-Konkurrenz
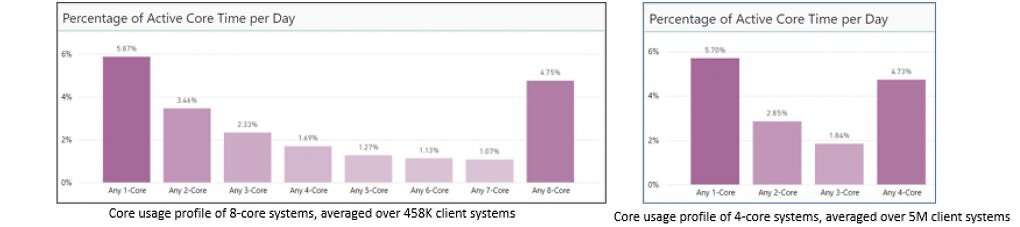
Eine größer gedachte Lösung, um die Hitzeentwicklung in den Griff zu bekommen, ist laut Marr die Aufteilung in P- und E-Kerne. P-Kerne setzen auf hohe Leistung und ein entsprechendes Temperaturmanagement, E-Kerne dienen hingegen als effiziente und platzsparende Erweiterung für Multicore-Aufgaben. Das soll gut zur Realität passen: Angeblich laufen die meisten Anwendungen nur auf einem (P-)Kern. Am zweithäufigsten kommen hingegen Anwendungen, die alle Kerne belasten. Dann kommen die vielen E-Kerne zum Tragen.
 Quelle: Debbie Marr
Die meisten Anwendungen nutzen angeblich nur einen oder alle CPU-Kerne.
Gleichzeitig sieht Marr eine stärkere Zusammenarbeit der Entwicklungsabteilungen als Lösungsweg an. Nur wenn die Architektur, die Fertigung und das Packaging aufeinander abgestimmt sind, kann es demnach gelingen, das Wärmeproblem möglichst effektiv anzugehen. Und das sorgt wiederum dafür, dass Endkunden möglichst schnelle Prozessoren kaufen können.
Quelle: Debbie Marr
Die meisten Anwendungen nutzen angeblich nur einen oder alle CPU-Kerne.
Gleichzeitig sieht Marr eine stärkere Zusammenarbeit der Entwicklungsabteilungen als Lösungsweg an. Nur wenn die Architektur, die Fertigung und das Packaging aufeinander abgestimmt sind, kann es demnach gelingen, das Wärmeproblem möglichst effektiv anzugehen. Und das sorgt wiederum dafür, dass Endkunden möglichst schnelle Prozessoren kaufen können.
Halten Sie Intels Konzept für gelungen? Nutzen Sie die Kommentarfunktion und teilen Sie uns Ihre Meinung mit. Zum Kommentieren müssten Sie auf PCGH.de oder im Extreme-Forum eingeloggt sein. Sollten Sie noch keinen Account haben, könnten Sie über eine Registrierung nachdenken, die viele Vorteile mit sich bringt. Beachten Sie beim Kommentieren aber bitte die gültigen Forenregeln.
Quelle: Debbie Marr (Ahead Computing, IEDM 2025)









Ich hab mal einen Die- Shot Photogeshoppt um zu zeigen wie eine 4- Core Group aussehen MUSS. Warum legt man hoch taktende Kerne im Standard direkt nebeneinander?! Das spricht doch so vieles dagegen. Interferenzen, Hitze etc.. Ich glaube kaum das man langsamer Unterwegs ist weil die Leiterbahnlänge nach oben geht. So ist ein inaktiver oder niedrig taktender Kern der Nachbar und keiner der gerade zieht was geht.
Bei den E- Core Clustern könnte man konsequenterweise auch so vorgehen. Simples Checkerboard.´Und man kommt ja auf die "kühlen" Kerne wenn man die bei Vollast monitored, so kann man das auch noch in Betracht ziehen.
Macht das so wenn ihr einen Prozessor der Serie habt- das funkt richtig gut. Und es wäre wohl kaum ein Problem das zu patchen. Zumindest im groben. Ist die Latenz gut genug und man rennt nicht in einen Waitstate, kann man das doch im Wechsel machen, vielleicht sogar mit Temp Tresholds für die Kerne. So werden die tatsächlich gleichmäßig belastet.
Ah und zu "welcher Kern für welchen Task". Ich suche lange nach einem Tool mit dem man das permanent zuordnen kann.
Vielleicht ginge der Spaß so auch verloren.
P.S.: Kern drei- warum 7 Grad mehr als der Rest XD
[Ins Forum, um diesen Inhalt zu sehen]
Jetzt mit Intels TSMC N3B Chips (Core 9 285K z.B.) werden die plötzlich mit AMDs Prozessoren im Effizienz-Index vergleichbar. Thermisch ist der Unterschied im realen Betrieb selbstverständlich geringer - was nützt denn die kühlere CPU, man reizt das Potential dennoch aus.
[Ins Forum, um diesen Inhalt zu sehen]
Geiles Video btw
Für professionelles Recording mag das kein KO-Kriterium sein, aber native Thunderbolt-Implementierungen sind m.E. robuster, homogener und berechenbarer.
Die Interconnect Latenzen von CPU Dies sind um Faktoren 1000x oder mehr kleiner als deine Latenz zwischen einzelnen aufgenommenen Frames. Daher sollte das nicht ins gewicht Fallen.
Aber auch bei Intel sollte das kein Problem sein. Moderne Aufnahmesoftware lässt den Codec ja auch über die GPU laufen für die RealTime komprimierung. Da dürfte die Latenz massgeblich grösser sein aus auf einer CPU.