AMD Financial Analyst Day 2010: Bulldozer im Video, Server-CPU-Specs
Im Rahmen des diesjährigen Financial Analyst Day veröffentlichte AMD neues Material zu kommenden Technologien, darunter ein Video, in dem ein Bulldozer-System ein HD-Video beschleunigt und die Llano-APU ein DirectX-11-Spiel darstellt.
Valencia und Interlagos bieten 8 MiByte L3-Cache pro Die, jedem Doppelkernmodul steht ein 2 MiByte großer L2-Cache zur Verfügung. Die Opteron-4200-Reihe unterstützt Dual-Channel, die 6200er-Modellreihe Quad-Channel - jeweils für DDR3-1600 statt bisher DDR3-1333. Der Turbomodus ermöglicht eine Taktanhebung um 500 MHz, wenn alle Kerne aktiv sind. Eine endgültige ACP- oder TDP-Angabe fehlt bisher, geplant ist allerdings je nach Modell eine ACP von 65, 80 und 105 Watt. Trotz erhöhter Kernzahl soll die Die-Fläche geringer ausfallen, was neben dem Doppelkern-Design auch der 32-Nanometer-Fertigung anzurechnen ist.
In einem Video zeigt AMD die Grafikbeschleunigung der Quadcore-CPU Llano: Während auf einem Bildschirm das DirectX-11-Spiel Herr der Ringe: Online in HD-Qualität dargestellt wird, beschleunigt die APU zur gleichen Zeit ein HD-Video. AMD betont dabei die relativ geringe Auslastung der APU, die im Task-Manager zu sehen ist.
In einem Vorserien-Notebook von MSI arbeitet eine Zacate-APU mit 18 Watt TDP, die ein HD-Video abspielt. Mehrere Stunden kann das Notebook diese Aufgabe erledigen, ohne am Stromnetz angeschlossen zu sein. Zacate ist der große Bruder der Ontario-APU, die es auf lediglich 9 Watt TDP bringen soll und ebenfalls Teil der für Q1/2011 geplanten Brazos-Mobilplattform ist. Im Anschluss ist das gleiche HD-Video zu sehen, das von einem mit einer Bulldozer-CPU ausgestattenen PC dargestellt wird. Der Task-Manager zeigt eine geringe Auslastung der acht Kerne an.
Weitere Informationen vom AMD Financial Analyst Day 2010:
Im Desktop-Markt sind Zambezi im Performance-Segment und Llano (Mainstream/Essential) die Hoffnungsträger, für 2012 ist aber bereits das Erscheinen von Komodo und Trinity geplant. Letzterer ist wie Llano eine Fusion-APU mit DirectX-11-GPU, die 2-4 Bulldozer-Kerne sollen aber ein "Next-Generation"-Update erfahren. Komodo ist der ebenfalls auf der Bulldozer-Architektur basierende Nachfolger von Zambezi und wird gemäß AMD-Roadmap nur noch als "Next-Generation"-Achtkerner erscheinen.
Die für besonders kompakte Desktop-Systeme vorgesehenen APUs Ontario und Zacate werden 2012 durch Krishna abgelöst. Damit verdoppelt sich die Anzahl der Bobcat-Kerne von 1 bis 2 auf 2 bis 4. Statt der 40-Nanometer-Fertigung ist dann die 28-Nanometer-Fertigung angesagt, die für das erste Halbjahr 2012 angedacht ist. Die 20-Nanometer-Fertigung dagegen soll noch bis Ende 2013 auf sich warten lassen, mit dem Wechsel zur 14-Nanometer-Strukturgröße ist frühestens Ende 2015 zu rechnen.
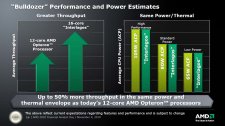
Während Zambezi im Desktop-Segment bereits im zweiten Quartal 2011 erscheinen soll, lässt die Server-Variante bis Q3/2011 auf sich warten. Darüber hinaus verriet AMD, dass ab Ende 2012 jede neue Server-CPU auf der Bulldozer-Architektur basieren soll. Interlagos soll 2011 mit acht bis 16 Bulldozer-Kernen und Quad-Channel-Unterstützung im Markt für 2-/4-Prozessor-Systeme erscheinen. Die CPUs können untereinander über vier HT-3-Links kommunizieren. Valencia soll im gleichen Jahr mit sechs oder acht Bulldozer-Kernen erscheinen und ist für günstige, energieeffiziente Server oder Workstations ausgelegt. 2012 wird Interlagos dann durch Terramar abgelöst, die Kernanzahl soll bis auf 20 steigen. Sepang wird Valencia ablösen, bis zu 10 Bulldozer-Kerne soll diese Plattform bieten. Alle genannten Server-CPUs sollen im 32-Nanometer-Verfahren hergestellt werden.








zudem sehe ich hier nichts wo ich AMD schlecht rede, es ist nunmal Fakt das BD, sofern das stimmt das eine 8 Modul BD 50% schneller ist als ein 12 Kern Magny Cours, nicht die IPC eines SB hat und auch nicht die eines Nehalem. Das hat nichts mit schlechtreden zu tun. Wenn man Fakten, wie oft von AMD Anhängern, ignoriert heisst das noch lange nicht das sie deswegen aus der Welt geschafft sind.
mfg
Das hat wohl keinen Sinn , aber auch wenn ich mich nicht beliebt damit mache ist es nett das es mal einer ausgesprochen hat ...
mfg F-4
mfg
Die GPU auf dem DIE hat den Vorteil das du deutlich geringere Latenzen hast. Damit kannste dann sehr sehr wahrscheinlich einfach vieles auf der GPU berechnen, wo sichs vorher nicht gelohnt hat, dies auf die dezidierte GPU zu packen. Auch das du die Daten direkt im RAM ablegen kannst ist ziemlich geschickt, weil du dir damit traffic sparst. Aber hauptsächlich die reduzierten Latenzen sind sehr sehr sehr interessant. So könnteste z.B. auf der dezidierten nen Reduzealgorithmus bis zu 80% durchführen, dann die Ergebnisse in den RAM packen und die letzten 20% mit der auf der CPU dann noch vollns durchrechnen, weil du da dann einfach die Latenzen sonst nicht mehr verstecken kannst.
Oder du kannst auch sonst einfach mal zwischendrin was kurz auf die GPU schmeisen ohne dir groß gedanken drüber machen zu müssen, wie ich das Zeug jetzt rüber bekomm und was ich dann solange auf der CPU mach etc etc.
Und nur mal so neben bei, es gibt auch PS3 Cluster *hust* und es man die normalen GeForce noch flashen konnte, hat die auch jeder gern genommen, trotz weniger ram, und bei das die Tesla Karten keinen Video-Out haben, ist schlicht ne Kostenfrage. Warum was anbringen, wo auch nur 1 Watt Strom verbraucht werden könnte, oder was kaputt gehen könnte, oder aber auch nur 1 Cent unnötige Produktionskosten anfallen.
@XE stimmt, hab da nicht genau genug gelesen. Da wird nur Integer Issues per Clock erwähnt. Hab da wohl zu schnell drübergelesen, wobei halt die Frage ist, wieviele Instructions du für eine Integer Issue jeweils brauchst.
Auf ner Folie zu Bulldozer stand ja mal, das >90% aller x86 Befehle (nagel mich darauf aber jetzt nicht fest) innerhalb eines Clock berechnet werden können, bzw durch die Pipeline kommen, so genau hab ich das grad nicht im Kopf. Fand das da recht interessant, da man ja für die meisten Befehle ziemlich viele Clocks braucht. So könnte man natürlich an der Performance auch schrauben. Microcode soll ja da kaum verwedet werden bei den Bulldozerkernen.
Muss ich aber nochmal raussuchen, war glaub bei GameStar gelistet die Folie, du weist aber sicher welche ich mein