High Bandwidth Memory für R9 390X & Co.: AMD-Präsentation zur Energieeffizienz und anderen Vorteilen

Eines der großen Themen im GPU-Geschäft wird bei AMD künftig High Bandwidth Memory, kurz HBM, sein. Der neue Speicherstandard gilt als eine der Ablösetechnologien für GDDR5, bei der Speicher-Chips übereinander gestapelt und über Kanäle im Silizium (Through-Silicon Vias, TSV) an die GPU angebunden werden. Fiji wird der erste Chip sein, der mit einem entsprechenden Interface daherkommt.
 Quelle: AMD
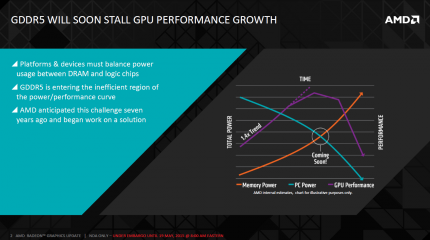
High Bandwidth Memory: Laut AMD wird GDDR5 bald die GPU-Performance bremsen
GDDR5 als Speicherstandard für GPUs nähert sich seinem Lebensabend. Zu groß sind die Limitierungen bei High-End-Lösungen: Je breiter ein Speichercontroller ausfällt, desto komplexer wird das Design. An mehr als 512 Bit hat sich bisher noch kein Chiphersteller getraut, eine Erhöhung der Bandbreite erfolgt also durch höhere Taktraten. Die erfordern höhere Spannungen und steigern damit die Leistungsaufnahme sowie Wärmeentwicklung. Als Nachfolger für GDDR5 gelten gestapelte Speicherchips, die über sogenannte Through Silicon Vias (TSVs) miteinander verbunden werden. Neben dem Hybrid Memory Cube (HMC, hauptsächlich von Micron und Intel entwickelt) setzt der JEDEC-Standard High Bandwidth Memory auf ein solches Design.
Quelle: AMD
High Bandwidth Memory: Laut AMD wird GDDR5 bald die GPU-Performance bremsen
GDDR5 als Speicherstandard für GPUs nähert sich seinem Lebensabend. Zu groß sind die Limitierungen bei High-End-Lösungen: Je breiter ein Speichercontroller ausfällt, desto komplexer wird das Design. An mehr als 512 Bit hat sich bisher noch kein Chiphersteller getraut, eine Erhöhung der Bandbreite erfolgt also durch höhere Taktraten. Die erfordern höhere Spannungen und steigern damit die Leistungsaufnahme sowie Wärmeentwicklung. Als Nachfolger für GDDR5 gelten gestapelte Speicherchips, die über sogenannte Through Silicon Vias (TSVs) miteinander verbunden werden. Neben dem Hybrid Memory Cube (HMC, hauptsächlich von Micron und Intel entwickelt) setzt der JEDEC-Standard High Bandwidth Memory auf ein solches Design.
HBM wurde beziehungsweise wird maßgeblich von AMD und SK Hynix entwickelt, wurde inzwischen aber schon offiziell von der JEDEC spezifiziert. SK Hynix als Speicherhersteller untergliedert die Technologie unabhängig von der JEDEC noch in die beiden Generationen "HBM1" und "HBM2", die sich jedoch lediglich in optionalen Implementierungsdetails unterscheiden. Erstere gibt es offiziell mit Stack-Größen von 1 GiByte. Dabei werden vier jeweils 2 Gbit große Chips übereinander gestapelt ("4 Hi") und paarweise mit je 256 Bit angebunden. Ein kompletter Stack bekommt folglich 1.024 Bit spendiert, was bei einer Standardfrequenz von 1 GHz eine Bandbreite von 128 GB/s ermöglicht. AMDs Radeon R9 390X soll mit HBM1 und einem 4.096-Bit-Interface daherkommen. Das würde laut SK Hynix' offiziellen Angaben vier HBM-Stacks mit insgesamt 4 GiByte VRAM bei 512 GB/s ermöglichen. Gerüchte sprachen von einer "Dual-Link"-Lösung, die 8 GiByte ermöglichen soll, die wurde von AMD jedoch nicht einmal erwähnt. Ohnehin zeigte man sich beim Call zu HBM sehr verhalten, was die Speichergröße der R9 390(X) angeht und erwähnte lediglich nebulös, dass die Anzahl der Stacks - wie bei jeder anderen Speicherlösung - kaum limitiert sei.
HBM2 soll ab dem kommenden Jahr zur Verfügung stehen und sowohl Kapazität als auch Übertragungsrate erhöhen. Die Speichermenge pro Chip soll damit auf 8 Gbit vervierfacht, die Geschwindigkeit auf 2 GHz verdoppelt werden. Ein 4-Hi-Stack hätte damit schon 4 GiByte bei 256 GB/s. Zudem sieht SK Hynix ab HBM2 auch achtfach gestapelte HBM-Stacks ("8 Hi") vor, dabei wird die Anbindung pro Chip auf 128 Bit halbiert, die Bandbreite bleibt also identisch. Diese 8-Hi-Organisation gibt die JEDEC-Spezifikation ebenfalls her, da HBM mit unabhängigen 128-Bit-Kanälen arbeitet, die quasi beliebig auch auf verschiedene Dies verteilt werden dürfen, solange dieselben Latenzen pro Kanal erreicht werden.
Mit HBM2 könnten an einem 4.096-Bit-Interface stolze 32 GiByte realisiert werden - und das auf sehr kleinem Raum. Die Radeon R9 290X braucht mit ihrer Hawaii-GPU und 4 GiByte (16 × 2 Gbit) 90 × 110 mm Platz. Eine ungenannte GPU - nennen wir sie mal Fiji - mit vier HBM-Stacks braucht laut AMD nur 70 × 70 mm.
 Quelle: AMD
High Bandwidth Memory: Die PCBs entsprechender GPUs sollen deutlich kleiner gehalten werden können
Neben dem Platzersparnis bietet HBM gegenüber GDDR5 Vorteile in Sachen Stromverbrauch und Chipfläche. Durch die niedrigen Frequenzen und die ausgewanderte Logik auf die Basis-Dies der SK-Hynix-Stacks fällt der Speichercontroller innerhalb der GPU deutlich simpler und kleiner aus. Das so frei gewordene Flächen- und Strombudget - bei der R9-290X maß AMD rund 30 Watt für das Speichersubsystem - kann so in zusätzliche Leistung gesteckt werden. Das wird vorerst aber nur bei High-End-Lösungen geschehen, derzeit ist HBM nämlich noch teurer als GDDR5 und lohnt sich deshalb noch nicht bei Low-End-Chips.
Quelle: AMD
High Bandwidth Memory: Die PCBs entsprechender GPUs sollen deutlich kleiner gehalten werden können
Neben dem Platzersparnis bietet HBM gegenüber GDDR5 Vorteile in Sachen Stromverbrauch und Chipfläche. Durch die niedrigen Frequenzen und die ausgewanderte Logik auf die Basis-Dies der SK-Hynix-Stacks fällt der Speichercontroller innerhalb der GPU deutlich simpler und kleiner aus. Das so frei gewordene Flächen- und Strombudget - bei der R9-290X maß AMD rund 30 Watt für das Speichersubsystem - kann so in zusätzliche Leistung gesteckt werden. Das wird vorerst aber nur bei High-End-Lösungen geschehen, derzeit ist HBM nämlich noch teurer als GDDR5 und lohnt sich deshalb noch nicht bei Low-End-Chips.
 Quelle: AMD
High Bandwidth Memory: Aktuell werden die Stacks per Interposer noch neben der GPU platziert ("2.5D")
Bei den ersten HBM-Iterationen handelt es sich derweil noch um "2.5D"-Lösungen, indem die Speicher-Stacks über einen Interposer neben einer GPU platziert werden. Grundsätzlich ist die Technologie aber auch darauf ausgelegt, "echte" 3D-Chips zu ermöglichen. Dabei werden die Stacks direkt über der GPU platziert, das würde bei Hochleistungs-Chips allerdings zu Kühlungsproblemen führen, denn die Abwärme der GPU müsste erst einmal durch die Speicher-Stacks hindurch, bevor sie von einem Wärmetauscher abgeleitet werden kann. Volle 3D-Integration ist daher eher für Low-Power-Chips wie sie in mobilen Geräten Verwendung finden, sinnvoll.
Quelle: AMD
High Bandwidth Memory: Aktuell werden die Stacks per Interposer noch neben der GPU platziert ("2.5D")
Bei den ersten HBM-Iterationen handelt es sich derweil noch um "2.5D"-Lösungen, indem die Speicher-Stacks über einen Interposer neben einer GPU platziert werden. Grundsätzlich ist die Technologie aber auch darauf ausgelegt, "echte" 3D-Chips zu ermöglichen. Dabei werden die Stacks direkt über der GPU platziert, das würde bei Hochleistungs-Chips allerdings zu Kühlungsproblemen führen, denn die Abwärme der GPU müsste erst einmal durch die Speicher-Stacks hindurch, bevor sie von einem Wärmetauscher abgeleitet werden kann. Volle 3D-Integration ist daher eher für Low-Power-Chips wie sie in mobilen Geräten Verwendung finden, sinnvoll.
Mit Interposern habe AMD diesbezüglich weitaus weniger Probleme gehabt als ursprünglich angenommen. Die HBM-Stacks würden als "Heatsink für die GPU" dienen, indem ein Teil der GPU-Abwärme durch die Verbindungen im Silicon Interposer quasi automatisch auf die Stacks verteilt wird. Die bieten zusätzliche Kontaktfläche zum Kühler, womit die Kühlung vereinfacht werden kann. Damit dürfte direkt auch unsere Annahme bestätigt werden, dass die Kompakt-Wasserkühlung bei der R9 390X alle Komponenten und nicht nur die GPU kühlt. Zudem sieht AMD HBM als "sehr gut übertaktbar" an, sprach dabei allerdings im Konjunktiv II ("should be").
Zu guter Letzt gab es noch einen minimalen Ausblick auf Fiji. Der soll keine größere TDP spendiert bekommen als Hawaii, die dafür aber effizienter nutzen. Das durch den Speicher freiwerdende Leistungsbudget soll der Rechenleistung zugute kommen. Bei Compute könnte auch die hohe Bandbreite durchschlagen, die Vorteile im 3D-Bereich müssen sich erst noch zeigen.









Und die mehrleistung kommt nur daher das die gamehersteller bezahlt worden sind damit nvidia Grafikkarten das bißchen schneller sind.
Streng nach dem Motto:"Wenn man weiß wer der Böse ist, dann hat der Tag Struktur".
Ist momentan ja auch anders bei gddr5 nvidia hat weniger vram voll als AMD.
Was du meinst ist ja nicht die Geschwindigkeit sondern die Speicherverwaltung.
Ist momentan ja auch anders bei gddr5 nvidia hat weniger vram voll als AMD.