Nvidia forscht an Multi-Chip-Modulen für Grafikkarten
Führt langfristig kein Weg an Multi-GPU vorbei? Während manche beim Gedanken daran direkt drei graue Haare mehr haben, forscht Nvidia zumindest für den Tag, an dem monolithische, sprich einzelne große GPUs ausgedient haben, weil der Fertigungsprozess nicht mehr verkleinert werden kann. Die Antwort auf das Skalierungsproblem könnte Multi-Chip-Module lauten.
Grafikkarten sind heute das Thema bei Hardware-Enthusiasten. Hier fand in der Vergangenheit die meiste Leistungsentwicklung statt und heutzutage operieren Spiele in der Regel im Grafikkartenlimit, weshalb hier besonders viel Aufmerksamkeit gefragt ist. Doch wie geht es weiter? Performance-Gewinne bei Grafikkarten finden wie auch bei CPUs über drei elementare Säulen statt:
- Verbesserung der Architektur
- Größere Chips mit mehr Recheneinheiten
- Höherer Takt.
Verbesserungen der Architektur alleine erlauben heute aber keine immensen Sprünge mehr und die beiden letzten Punkte sind maßgeblich von der Fertigungsgröße des Chips abhängig.
Alle drei Punkte greifen zusammen und hängen daran, dass künftig noch feinere Siliziumplättchen belichtet werden können. Doch diese Reise der feineren Strukturen wird irgendwann ein Ende nehmen, ebenso wie die Vergrößerung des Chips. Gut 800 mm² werden als Ende der Fahnenstange angesehen, Pascal hat maximal 610 mm², Volta 815 mm². Die maximale Belichtungsgröße eines entsprechenden Gerätes wie dem Twinscan NXT 1950i von ASML liegt bei 26,0 × 33,0 mm. Und dann? Stillstand?
Nvidia wie auch AMD versuchen daher zumindest in der Forschungsabteilung sein Glück mit Multi-Chip-Module GPUs (MCM-GPU). An denen wird gerade zusammen mit der Arizona State University, der University of Texas und dem Barcelona Supercomputing Centre geforscht und sie könnten künftige Leistungssteigerungen sichern.
 Quelle: Nvidia
Nvidia forscht an Multi-Chip-Modulen für Grafikkarten (1)
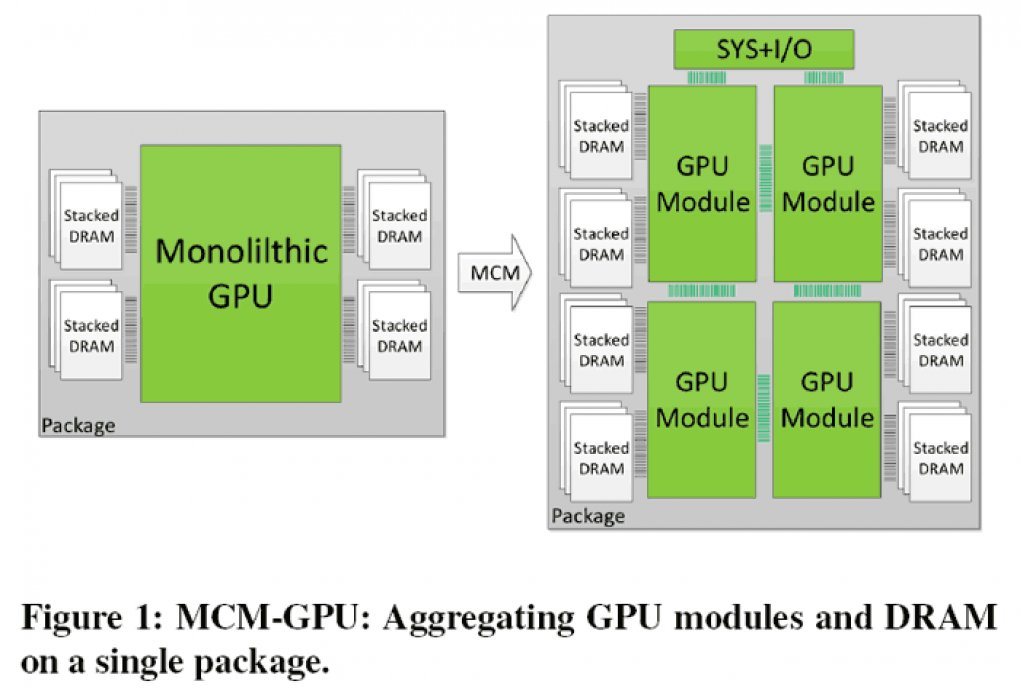
Multi-Chip-Module sind aus "einfachen" GPU-Kernen bestehende Module, und von den GPU-Kernen sind es viele. Quasi so etwas wie SLI nur in anderem Maßstab oder Intels Many-Core-Projekt. Oder noch besser so ähnlich wie AMD es aktuell bei Ryzen macht. Vom 4- bis zum 16-Kerner steckt überall das gleiche Grundmodul drin, teilweise mehrfach ausgeführt und mit dem flexiblen Infinity Fabric als schnellem Interconnect verbunden.
Quelle: Nvidia
Nvidia forscht an Multi-Chip-Modulen für Grafikkarten (1)
Multi-Chip-Module sind aus "einfachen" GPU-Kernen bestehende Module, und von den GPU-Kernen sind es viele. Quasi so etwas wie SLI nur in anderem Maßstab oder Intels Many-Core-Projekt. Oder noch besser so ähnlich wie AMD es aktuell bei Ryzen macht. Vom 4- bis zum 16-Kerner steckt überall das gleiche Grundmodul drin, teilweise mehrfach ausgeführt und mit dem flexiblen Infinity Fabric als schnellem Interconnect verbunden.
Hardware-Enthusiasten werden nun angesichts der bekannten Probleme von Multi-GPU-Lösungen schon graue Haare haben, aber grundsätzlich sollte neuen Technologien eine Chance gegeben werden und die vollmundigen Versprechen lauten derzeit, ohne sie überprüfen zu können, dass die Multi-Chip-Module besser skalieren und dank schnellen Interconnects weniger (mikro)ruckeln sollten. Allerdings sind sämtliche Simulationen erst einmal anhand gut parallelisierbarer und für Probleme wie Mikroruckeln eher weniger anfälligen, allgemeinen Algorithmen durchgeführt worden.
Man darf die Technologie also eher als das verstehen, was jetzt auch schon auf Grafikkarten-Chips passiert: Die Kombination mehrerer Rechencluster zu einem großen Chip; beispielsweise beim GP102 28 SMs zu 64 Cuda-Kernen, was zu 3.584:224:88 (Shader/TMU/ROP) führt.
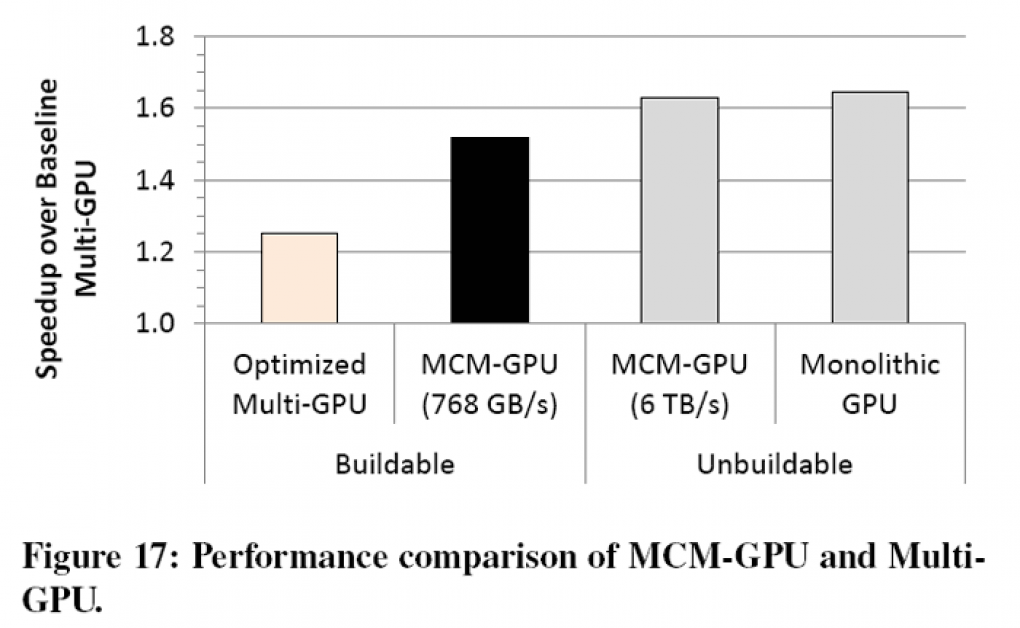
Und so wird auch verglichen: Eine MCM-Lösung mit 256 (4×64) SMs (Streaming Multiprocessor) und 1 GHz soll auf dem Papier 45,5 Prozent flotter sein als die größtmögliche monolithische GPU mit 128 SMs. Durch den einfachen Aufbau sollen sich die MCM-Module auch leichter in größeren Mengen kombinieren lassen als bisherige Rechencluster, von denen die schnellste Pascal-Karte Tesla P100 56 hat (GP100 insgesamt 60), die gerade vorgestellte V100-GPU bis zu 84, von denen auf der Tesla V100 jedoch nur 80 aktiv sind.
Auf dem Papier wurde ein MCM-Setup auch gegen ein klassisches SLI-Setup mit gleicher Menge an Rechenkernen gestellt und da sollen es 26,8 Prozent Mehrleistung sein. Eine SLI-Lösung soll sich aber nicht so gut skalieren lassen wie die MCM-Lösung. Eine vergleichbar ausgestattete monolithische GPU wäre zwar nach wie vor mit rund 10 Prozent Abstand in Schlagdistanz, lässt sich laut der Forscher aber mit heutigen Möglichkeiten nicht konstruieren.
 Quelle: Nvidia
Nvidia forscht an Multi-Chip-Modulen für Grafikkarten (2)
Klar ist, dass die Fertigungsprozesse sich nicht mehr in dem Tempo verkleinern lassen, wie man das in den vergangenen Jahren gewohnt war. Die ersten Effekte davon hat man schon erlebt, etwa bei Intel, wo schon die letzten beiden Fertigungsprozesse mehr Probleme machten, als man gerne gehabt hätte. An anderen Basismaterialien wird geforscht, marktreif ist davon aber nichts. Ebenso wie das MCM-Konzept von Nvidia. Sollte es jemals zur Marktreife reichen, dürfte das fertige Produkt noch einige Zeit auf sich warten lassen. Ebenso wie bei AMD, wo man ebenfalls an ähnlichen Projekten forscht.
Quelle: Nvidia
Nvidia forscht an Multi-Chip-Modulen für Grafikkarten (2)
Klar ist, dass die Fertigungsprozesse sich nicht mehr in dem Tempo verkleinern lassen, wie man das in den vergangenen Jahren gewohnt war. Die ersten Effekte davon hat man schon erlebt, etwa bei Intel, wo schon die letzten beiden Fertigungsprozesse mehr Probleme machten, als man gerne gehabt hätte. An anderen Basismaterialien wird geforscht, marktreif ist davon aber nichts. Ebenso wie das MCM-Konzept von Nvidia. Sollte es jemals zur Marktreife reichen, dürfte das fertige Produkt noch einige Zeit auf sich warten lassen. Ebenso wie bei AMD, wo man ebenfalls an ähnlichen Projekten forscht.








Oder war das wie bei VW ein April-Scherz?
In Zeiten wo Verschwörungstheroretiker und Covidioten jeden Quatsch für wahr halten gar nicht so einfach FakeNews von Aprilscherzen und Satire zu unterscheiden.
n, weil der Fertigungsprozess nicht mehr verkleinert werden kann.
[Ins Forum, um diesen Inhalt zu sehen]
UUUUND hier mal eine NEWS von 2017 !!!!
[Ins Forum, um diesen Inhalt zu sehen]
VON 2017:
Laut NVIDIA hat Morres Law nur noch durch die Parallelisierung in den vergangenen Jahren bestand. Die Instruktion Pipelines wurden immer größer, um die Single-Threaded-Anwendungen zu beschleunigen. Weitere Optimierungen wie Caches-Hirarchien und Instruktionen wurden ebenfalls immer komplexer, um diese Bedürfnisse zu erfüllen.
Das dürfte am geringeren Takt und der steigenden benötigten Bandbreite liegen. Es gibt bei diesen ersten Prototypen / Konzeptmodellen sicher noch unendlich viele Flaschenhälse, weshalb die Leistung nicht linear ansteigen kann.
Es ist hierbei die Frage wie gut die Kommunikation innerhalb der Architektur arbeitet. Im Multiplexszenario steigen die Anforderungen mit jeder neu angeflanchten Teil-GPU massivst an.
Der Scheduler müsste wohl auch stark überarbeitet werden. Für das fertige Produkt müsse man die Verhältnisse sehr genau anpassen, was bei dieser Studie sicher nicht passiert ist. Sie is wohl nur ein absolutes Grobkonzept um das potential aufzuzeigen.
Ein monolitischer Chip würde auch nicht endlos skalieren. Das Ergebnis kommt sicher auf die individuelle Konfiguration an. Primär dürfte MCM eher eine Technik zur Kostenreduzierung und Umgehung von Fertigungslimits sein. Um die eigentliche Leistung müssen sich dann die Ingenieure in der Entwicklung kümmern.
Das es keine lineare oder bessere Skalierung gibt wird im Paper so erklärt das die Transistoren nicht besser skalieren können und es dadurch Flaschenhälse gibt. Diese lassen sich nicht vermeiden wodurch man bei MCM auf viele kleine Pakete mit weniger SM setzt. Interessanter ist die nächste Simulation wo ein SLI System modelliert wurde aus 2x128SM und auch dort ist die MCM GPU schneller. 51,9% mit aktueller SLI Skalierung und 25,1% mit optimierter SLI Skalierung.
Das Paper klingt nicht danach das man versucht über MCM Kosten zu sparen sondern um die Leistung weiter steigern zu können. Im Paper geht man davon aus das ein einzelner Die mit 128 SM das Limit ist weil danach die Verluste im Vergleich zum Leistungsgewinn zu groß sind. Was für Möglichkeiten bestehen wenn man nicht mehr Leistung aus einer einzelnen GPU holen kann? Man nutzt mehrere GPUs, jedoch gibt es auch dort Flaschenhälse die man durch MCM umgehen will. Durch die vielen, kleinen Dies werden vielleicht die Kosten geringer ausfallen als bei riesen Dies mit 800mm² aber ich denke nicht dass es das Primärziel ist.
Aber die ansätze für MCM ist ja nicht Zwei GPUs. Sondern eine GPU mit mehreren DIEs.
Oder eben das quasi zusammenfügen von mehreren GPUs zu einer "einzigen".